
Episodio I
** ****En el año 2051, un grupo de jóvenes científicos afortunados recibe la exclusiva oportunidad de explorar los secretos de WestWorld. Su viaje entre bastidores toma un giro excepcional cuando son invitados a una conferencia única, orquestada por el enigmático director del parque, el Dr. Ford. **
En el centro de este encuentro, una fascinante inmersión en el mundo del Aprendizaje Profundo reserva a los participantes una experiencia sin precedentes, revelando los secretos de la simbiosis entre la tecnología de vanguardia y la imaginación audaz de WestWorld.
En los Confines de la Inteligencia
Bienvenidos, mentes innovadoras, a WestWorld, un parque de atracciones revolucionario donde la innovación tecnológica y la audacia artística se fusionan para crear una experiencia inmersiva sin precedentes. Soy el Dr. Ford, y como Director de este parque de un nuevo tipo, estoy aquí para revelarles los fundamentos computacionales y la visión matemática que sustentan este proyecto extraordinario.
Créditos: HBO

Créditos: HBO
Nuestra ambición va mucho más allá de una simple recreación del Lejano Oeste. WestWorld empuja los límites de la imaginación al presentar huéspedes, androides de una sofisticación sin igual capaces de interactuar de manera indistinguible con nuestros visitantes. No es simplemente entretenimiento; es una exploración de los rincones más profundos de la inteligencia artificial: el Deep Learning.
En el corazón de este paraíso forjado por la tecnología, nuestra búsqueda es empujar constantemente los límites de lo posible. Nuestros huéspedes no simplemente replican acciones preprogramadas; reaccionan, aprenden y evolucionan en tiempo real. Alimentados durante años por una enorme base de datos, los hemos entrenado, validado y sometido a pruebas (aprendizaje supervisado), asegurando que ofrezcan una experiencia única y tengan la capacidad de aprender de manera autónoma después.
Las redes neuronales que los alimentan, inspiradas en la complejidad del cerebro humano, les proporcionan la versatilidad necesaria para realizar una variedad de tareas, desde conducir una carreta hasta montar a caballo, desde leer hasta escribir, desde reconocer a sus semejantes hasta expresar empatía a través del reconocimiento de emociones. Esta sublime unión entre la máquina y el pensamiento humano va más allá de los modelos clásicos de Machine Learning como K-Nearest Neighbors, árboles de decisión o máquinas de vectores de soporte. Cada interacción con un visitante representa una oportunidad para perfeccionar sus habilidades cognitivas (aprendizaje no supervisado), brindando así una experiencia única en cada momento, incluso si este aspecto no se explorará en esta conferencia.
En WestWorld, nuestra vocación no se limita a proporcionar simples entretenimientos; creamos universos virtuales que trascienden la realidad. Para mentes iluminadas como las suyas, destacados participantes en esta empresa, es una expedición a los límites de la tecnología y la humanidad, una fusión entre la creatividad artística y el poder del cálculo avanzado. Nuestro objetivo hoy es iniciarle en los conceptos fundamentales de las redes neuronales presentando el perceptrón multicapa y revelándole el proceso mediante el cual nuestros huéspedes aprenden a reconocer números. En una próxima conferencia, exploraremos en detalle cómo logran identificar a otros individuos. Prepárese para sumergirse en una aventura donde la línea entre el hombre y la máquina se difumina, abriendo horizontes tan vastos como la imaginación misma.
Créditos: HBO
Al Principio: La Neurona Biológica
En un número aproximado de 86 mil millones y conectadas por miles e incluso decenas de miles de sinapsis, estas células altamente especializadas, inscritas en nuestro patrimonio genético desde hace miles de millones de años, se llaman neuronas.
Ensambladas en red, estas neuronas, que calificamos de “biológicas” en contraposición a “artificiales”, generan el pensamiento humano y lo que llamamos inteligencia. Sin embargo, no son las únicas células cerebrales en acción. Otros tipos de células desempeñan un papel fundamental y contribuyen al proceso neuronal, siendo su presencia esencial indispensable para la existencia misma de las neuronas.
Su Estructura
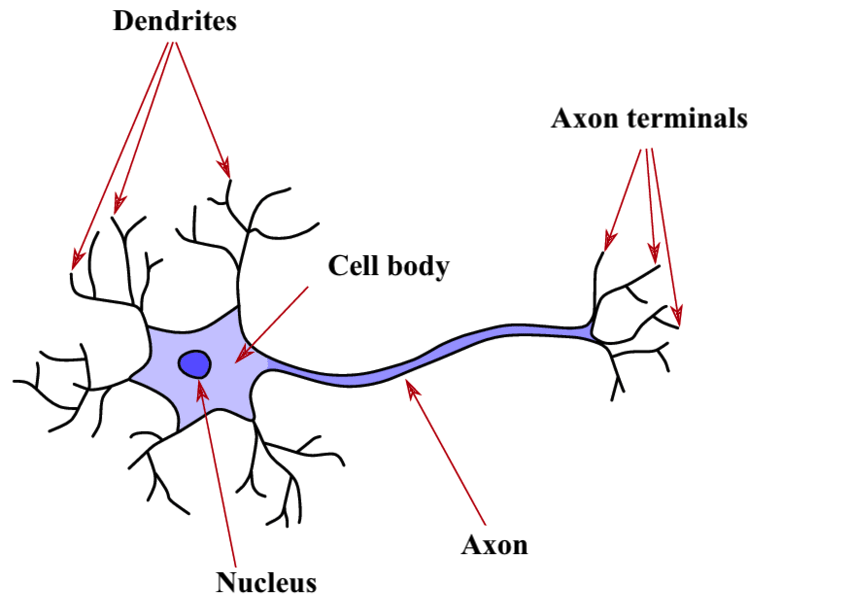
La estructura fundamental del sistema nervioso, compuesta por células excitables interconectadas, desempeña un papel crucial en la transmisión de información dentro de nuestra red neuronal. Está compuesta por varios componentes clave que orquestan su función.
Las dendritas actúan como interfaces con el entorno, formando la entrada de la neurona. En gran número, estas extensiones responden a varios estímulos, como la luz en los ojos o la presión sobre la piel, generando descargas eléctricas, también llamadas potenciales de acción, dirigidas hacia el cuerpo celular. La sinapsis, punto de conexión entre las neuronas, desempeña un papel crucial en este lugar, donde la neurona recibe señales de neuronas anteriores o del entorno. Estas señales, ya sean inhibidoras o excitadoras (+1 o -1), convergen hacia la neurona, y cuando su suma supera un umbral crítico, la neurona se activa, produciendo así una señal eléctrica.
El cuerpo celular, central en el proceso, realiza una suma de la intensidad de los impulsos eléctricos provenientes de todas las dendritas. Si esta suma supera un umbral crítico, la neurona se activa y genera una descarga eléctrica transmitida al axón, la única vía de salida de la neurona. Este umbral crítico, que determina la excitación supraumbral, tiene una importancia crucial.
El axón, como la vía final común, se ramifica en múltiples extensiones, conectando la neurona con otras neuronas a través de dendritas y sinapsis. Estos puntos de conexión, representados anatómicamente como hendiduras sinápticas, son esenciales para la transferencia de información entre las neuronas. El extremo del axón, marcado por vesículas de neurotransmisores, libera estos mensajeros químicos en la hendidura sináptica. A su vez, la dendrita de la siguiente neurona, equipada con receptores, captura los neurotransmisores, desencadenando la formación de una corriente eléctrica en la dendrita.
En cuanto a la información transmitida por la neurona, es crucial entender su dualidad electroquímica. Inicialmente creada en forma eléctrica en las dendritas en respuesta a un estímulo, la información se propaga a través del cuerpo celular hacia el axón. En la terminación del axón, el impulso eléctrico desencadena la liberación de neurotransmisores, transformando la información en una forma química en la sinapsis.
Créditos: HBO
Es importante destacar que esta información circula solo en una dirección específica, desde las dendritas hacia el axón. La dendrita capta la señal, y el axón la difunde, creando así un flujo unidireccional en la información neuronal. Esta sutil danza electroquímica dentro de la neurona forma el fundamento de nuestra comprensión, nuestros pensamientos y nuestra interacción con el mundo que nos rodea.
Su funcionamiento
Pilar del sistema nervioso, se revela como la célula maestra capaz de transmitir señales electroquímicas a lo largo de todo el organismo. Estas señales, resultado de despolarizaciones de la membrana plasmática y la liberación de moléculas químicas en los puntos de conexión con otras células, constituyen el fundamento de la neurotransmisión.
Cada neurona, dedicada a tareas específicas, contribuye a una red compleja que permite realizar funciones tan diversas como la memorización, la motricidad, la facilidad de aprendizaje o incluso el reconocimiento vocal, entre otras.
La variedad de neuronas, reflejando la diversidad de roles que desempeñan, las convierte en actores esenciales en la orquestación compleja de las funciones del sistema nervioso. Estas células, a través de sus extensiones, las dendritas y el axón, establecen conexiones vitales con los órganos inervados y otras neuronas, consolidando así su papel central en las funciones del sistema nervioso.
El Primer Neurona Artificial de la Historia
Estimados oyentes, ahora es el momento oportuno para presentarles la célebre neurona artificial, un concepto importante en informática inaugurado por W. McCulloch y W. Pitt en 1943, una época ya lejana.
Aunque carece de realidad física, este notable elemento ofrece una réplica algorítmica simple de su homólogo biológico, marcando así el comienzo de una fascinante aventura en el mundo de la inteligencia artificial.
Su Estructura y Funcionamiento
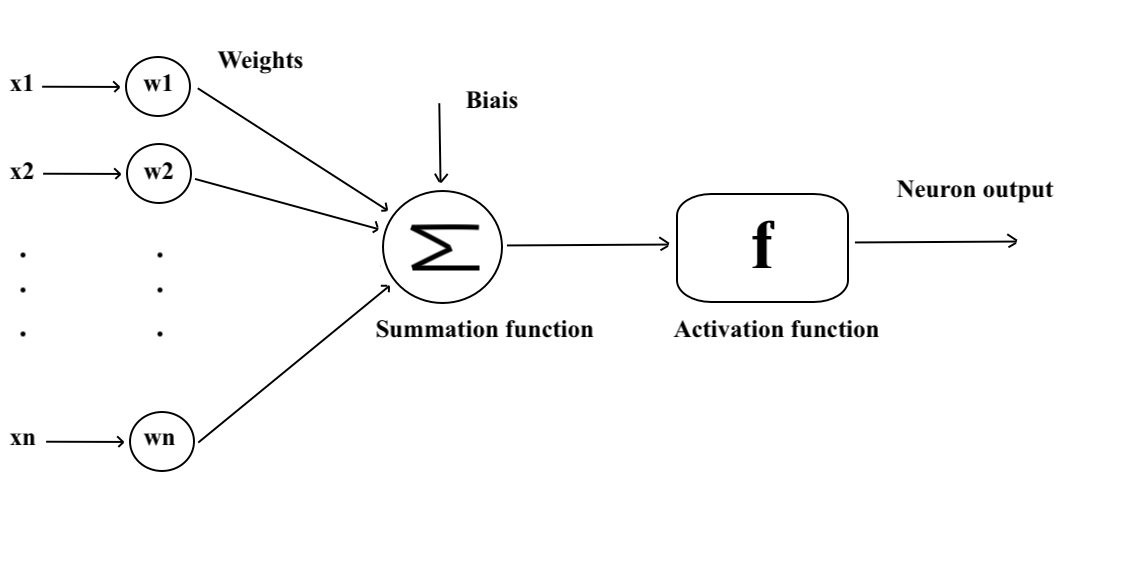
La estructura del neurona artificial se caracteriza por varios elementos clave, como la entrada y los pesos sinápticos, el cuerpo celular y la salida. Cada uno de estos aspectos contribuye de manera crucial al procesamiento de la información en las redes de neuronas artificiales. Veámoslo en detalle.
Se Recopila la Información
Comencemos con la entrada. En informática, la entrada representa los datos a procesar, como una cadena de caracteres, una imagen, una densidad de oro o incluso un video.
Cada neurona artificial recibe un número variable de entradas de neuronas aguas arriba, que denominaremos como X. Estas entradas son las señales que activan la neurona y estarán acompañadas de pesos (representados por “w” para “weight”) que cuantifican la fuerza de la conexión.
El conjunto de estas entradas forma la primera etapa del procesamiento de la información por la neurona artificial.
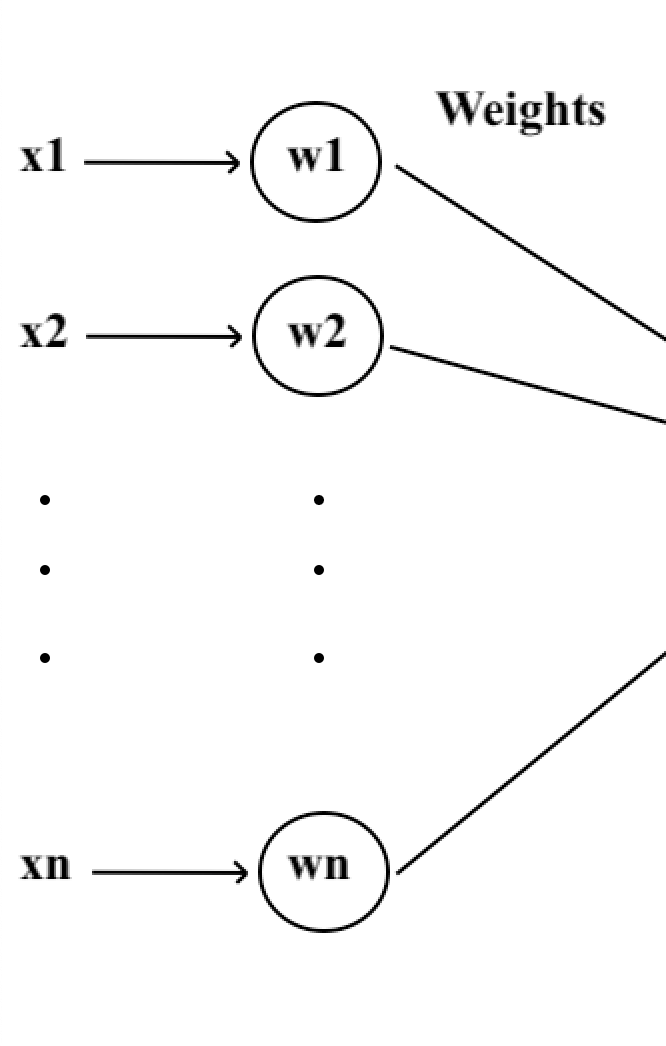
El Cuerpo Celular Artificial: una Función Matemática
La fase de agregación. Se asignan pesos sinápticos, inspirados en el funcionamiento de las dendritas, a cada valor de entrada que representa la importancia relativa de las diferentes conexiones para la neurona, luego se suman las entradas ponderadas agregando un sesgo (un valor constante). Por ahora, solo consideramos pesos sinápticos que valen +1 (excitador) o -1 (inhibidor), pero más adelante generalizaremos.
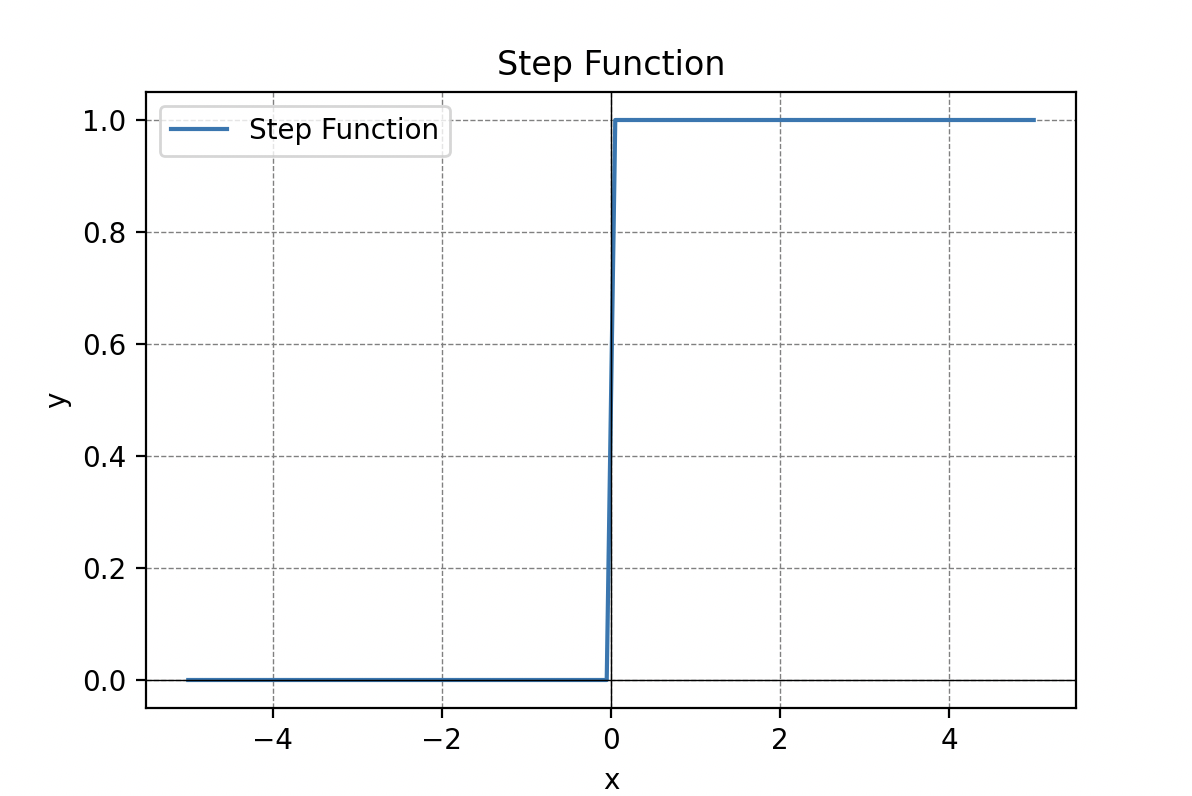
La fase de activación. Luego, una función de activación determina si la neurona debe activarse o no. Primero elegimos una función umbral (llamada Heaviside), es decir, una función que devuelve una salida si la suma ponderada anterior supera un umbral y 0 en caso contrario.
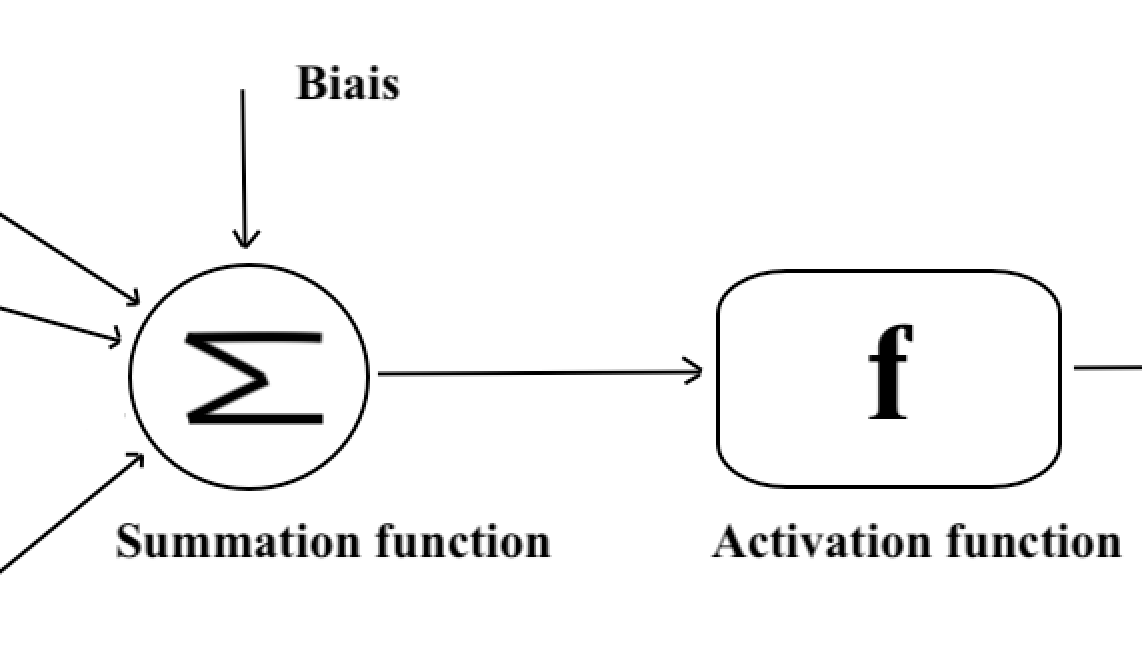
Representación de la función de suma y activación.
Las funciones de activación son cruciales en el procesamiento de la información y pueden tomar diferentes formas, como la función umbral, la función sigmoide, la función lineal rectificada (ReLU) o la tangente hiperbólica.
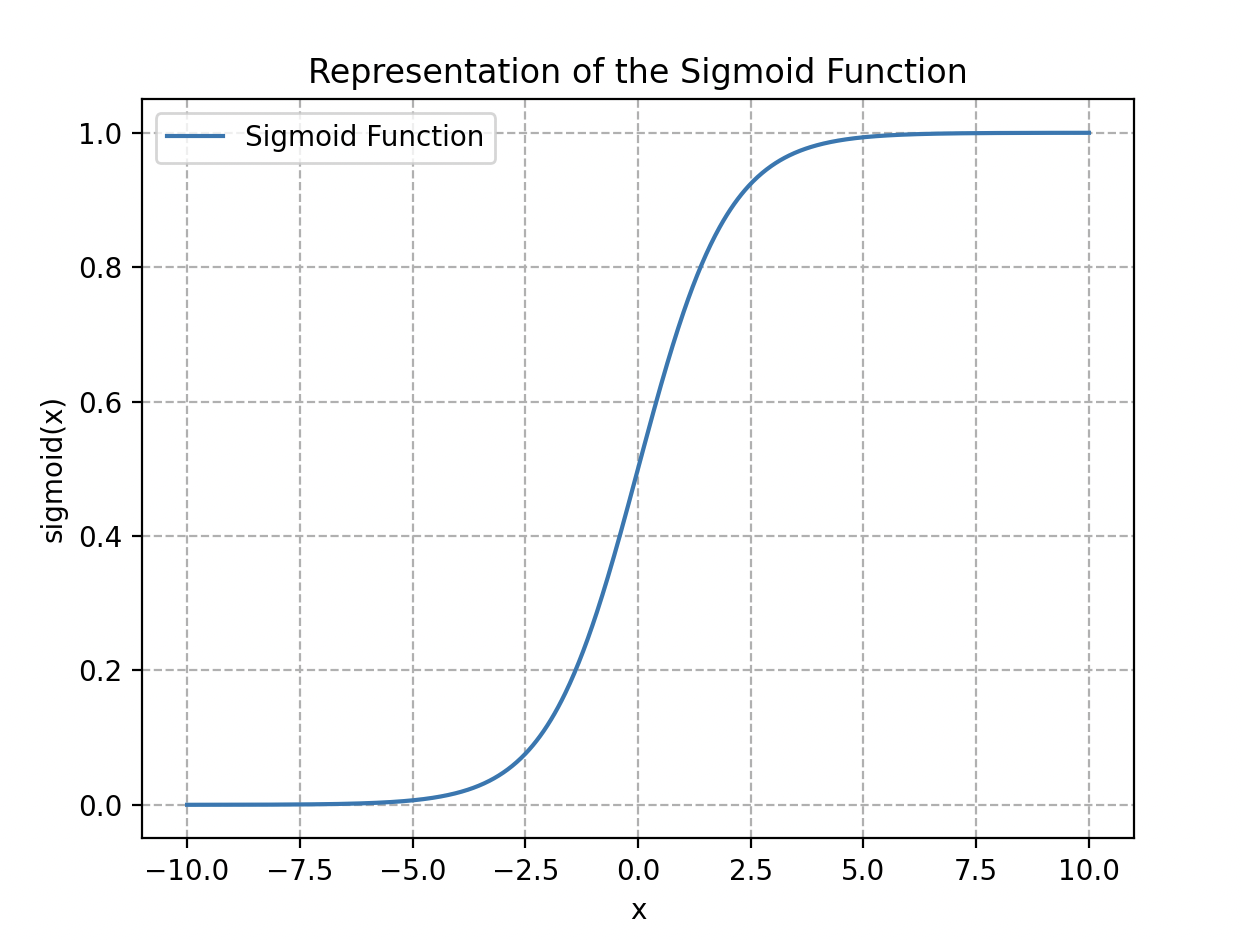
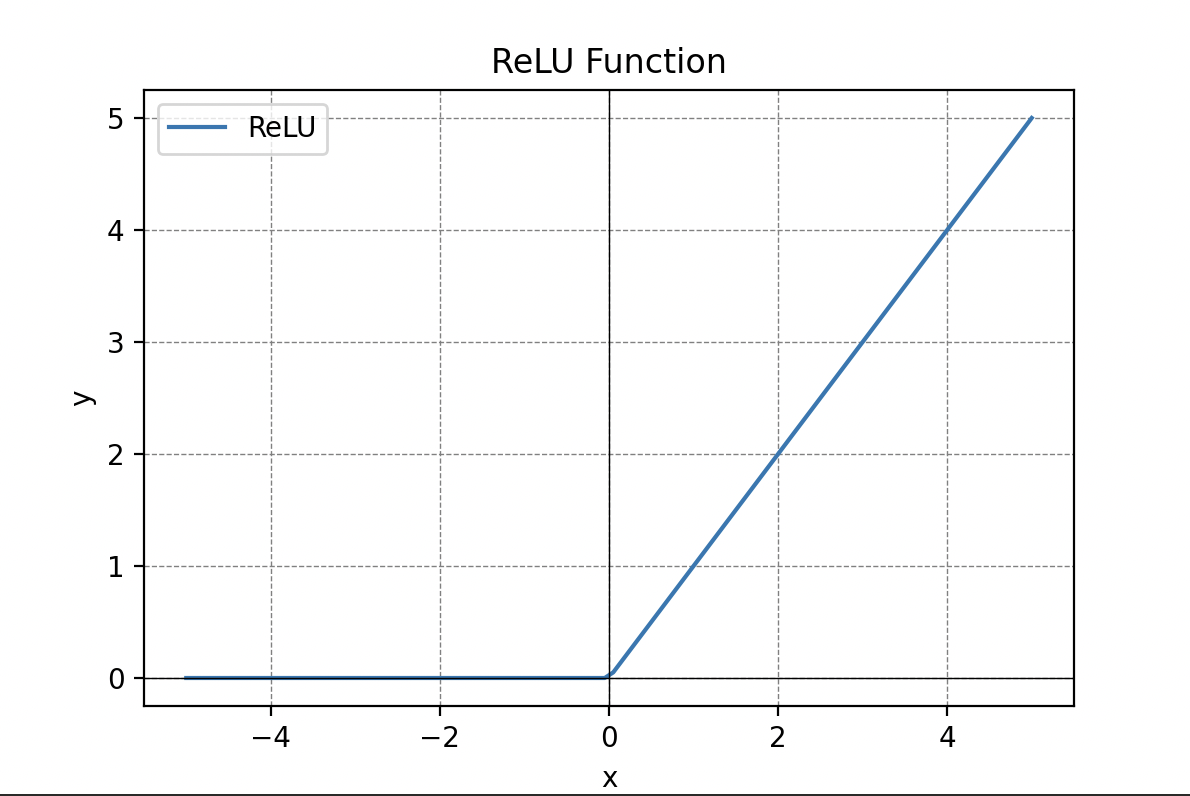
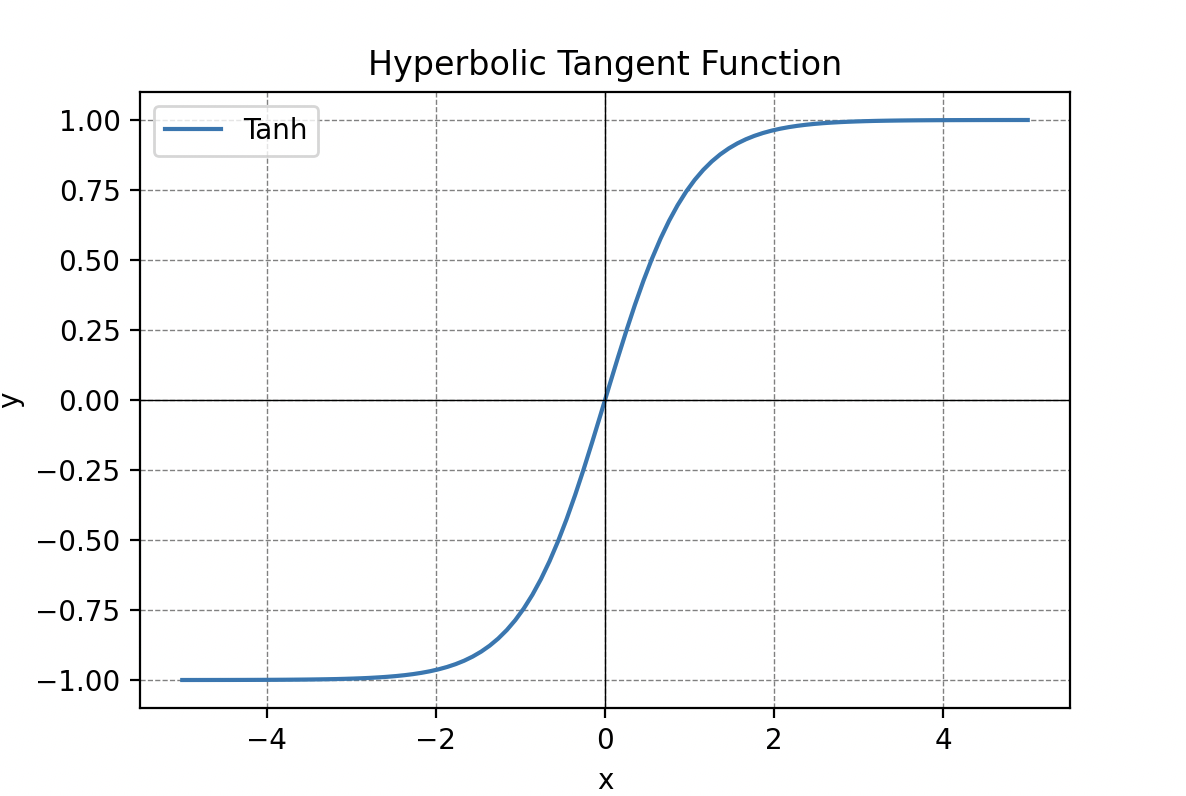
Información Procesada
La salida de la neurona artificial es el resultado final del procesamiento de la información contenida en los datos de entrada X, ya sea y=0 (activado) o y=1 (desactivado). Puede ser transmitida a otras neuronas, formando así una cadena compleja de cálculos que caracteriza el funcionamiento global de la red de neuronas artificiales.
Créditos: HBO
Este primer modelo de neurona artificial fue posteriormente designado como “Unidad de Lógica de Umbral” debido a su capacidad para procesar solo entradas lógicas que valen ya sea 0 o 1. Lograron demostrar que este modelo era capaz de reproducir ciertas funciones lógicas como las compuertas AND y OR (respectivamente Y y O en inglés). Además, al interconectar varias de estas funciones de manera similar a las conexiones entre las neuronas de nuestro cerebro, parecía posible resolver prácticamente cualquier problema de lógica booleana.
A pesar del entusiasmo desmedido generado por este anuncio, quiero asegurarles que, en ese momento, una parte significativa de la comunidad científica pensaba que podríamos desarrollar inteligencias artificiales capaces de reemplazar completamente a los seres humanos.
Científico en la audiencia mirando a los huéspedes junto al Dr. Ford: “¡No estaban completamente equivocados!” Risas en la sala.
El Dr. Ford retoma con una sonrisa: De hecho, no completamente, simplemente que su escala de tiempo no era adecuada para ese anuncio. De todos modos, esa anticipación no se materializó directamente. Aunque este modelo sentó las bases de lo que hoy conocemos como Aprendizaje Profundo, presenta varias deficiencias, como la falta de un algoritmo de aprendizaje. Así, es responsabilidad del usuario determinar manualmente los valores de los parámetros “W” si desea aplicar este modelo a aplicaciones del mundo real.
Un Ejemplo Sencillo
Ahora, comencemos con una breve explicación del álgebra booleana para los dos científicos del fondo.
El álgebra booleana, llamada así por el matemático británico George Boole, es una rama de las matemáticas que se centra en la representación y manipulación de información lógica a través de operaciones en variables llamadas booleanas. Estas variables solo pueden tomar dos valores, generalmente denotados como 0 y 1, simbolizando respectivamente los estados falso (no) y verdadero (sí).
Ampliamente utilizada en informática, electrónica y otros campos relacionados con el procesamiento de información, el álgebra booleana es fundamental para diseñar circuitos lógicos, algoritmos y sirve como base para la lógica proposicional.
En el álgebra booleana, las operaciones fundamentales son el Y lógico, el O lógico y la negación lógica (NO). Estas operaciones se aplican a pares de variables booleanas y producen un resultado booleano.
Un Ejemplo en un Ejemplo
Ahora, para entender mejor estas operaciones, tomemos el ejemplo de una habitación con un interruptor A y un sensor B que detecta la presencia de personas controlando la luz.
Interruptor A Y Sensor B (A Y B):
- Si el interruptor A está activado (A = 1) Y el sensor B detecta personas (B = 1), entonces la condición C “la luz se enciende” es VERDADERA (C = 1).
- Si el interruptor A está desactivado (A = 0), incluso si el sensor B detecta personas (B = 1), la condición C es FALSA (C = 0).
- Si el interruptor A está activado (A = 1) pero el sensor B no detecta personas (B = 0), la condición C también es FALSA (C=0).
- Si ambos, el interruptor A y el sensor B, están desactivados (A=0 y B=0), la condición C es FALSA (C=0).
Interruptor A O Sensor B (A O B):
- Si el interruptor A está activado (A = 1) O el sensor B detecta personas (B = 1), entonces la condición C es VERDADERA (C = 1).
- Si el interruptor A está desactivado (A = 0) O el sensor B detecta personas (B = 1), entonces la condición C es VERDADERA (C = 1).
- Si ambos, si el interruptor A está activado (A = 1) o el sensor B no detecta personas (B = 0), entonces la condición es VERDADERA (C = 1).
- Si el interruptor A está desactivado (A = 0) o el sensor B no detecta personas (B=0), entonces la condición C es FALSA (C = 0).
En estos ejemplos, la operación Y requiere que el interruptor esté activado y que se detecte la presencia de personas para que la condición sea verdadera. Por otro lado, la operación O requiere que el interruptor esté activado o que se detecte la presencia de personas para que la condición sea verdadera.
Todo se puede resumir en estos dos cuadros:
| A | B | A AND B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
| A | B | A OR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
Estas operaciones básicas pueden combinarse para formar expresiones lógicas más complejas, permitiendo representar condiciones (no solo dos como en el ejemplo anterior) y razonamientos lógicos.
El álgebra de Boole encuentra aplicaciones prácticas en el diseño de circuitos lógicos, sistemas de control, informática y otros campos donde la lógica binaria se utiliza para modelar estados y decisiones.
Volvamos al Neurona
El científico del fondo levanta la mano para pedir la palabra: “Pero, ¿qué tiene que ver un neurona con el álgebra de Boole?”
El Dr. Ford entra en detalle en las explicaciones: “Simplifiquemos y consideremos un neurona formal que acepta simplemente dos variables de entrada y , que colocamos en un vector de entrada (es la información que recibe la neurona):
Dado que las entradas solo pueden tener valores de 0 o 1 en nuestro caso, tenemos solo 4 vectores de entrada posibles:
”
También definimos los dos parámetros sinápticos y , que también colocamos en un vector que llamamos .
Estos pueden tener valores de 1 o -1, por lo que, como anteriormente, tenemos solo 4 vectores de pesos posibles:

Créditos: HBO
Ahora podemos comenzar la fase de agregación, que toma una entrada, le asocia un peso correspondiente, suma y agrega un sesgo denominado ( b ). Aquí está el resultado:
Colocamos todo esto en una tabla.
Luego, pasamos a la fase de activación, es decir, introducimos el valor obtenido en nuestra función de umbral que llamaremos ( H ) y que determina la salida de la neurona de la siguiente manera:
Aplicando un razonamiento similar, observamos que una neurona con una sola entrada puede no tener ningún efecto (neurona identidad) o realizar una operación lógica NOT.
Al establecer un vínculo con el álgebra de Boole, hemos demostrado cómo este modelo puede realizar operaciones lógicas fundamentales, como OR y AND.
Sin embargo, a pesar de sus avances, este modelo único presenta dos limitaciones importantes: en primer lugar, está limitado a operaciones simples, y en segundo lugar, no tiene ningún mecanismo de aprendizaje. Como se ilustró anteriormente, las únicas operaciones que podemos realizar son OR y AND, y debemos determinar manualmente los valores de los pesos para realizar estas operaciones lógicas específicas. Estas limitaciones han motivado el desarrollo posterior de modelos más sofisticados en el campo del aprendizaje profundo, especialmente al interconectar estos modelos de neuronas, obtenemos la capacidad de resolver prácticamente cualquier problema de lógica booleana. Además, si permitimos que el modelo aprenda de manera autónoma, se vuelve posible abordar problemas más complejos y ampliar considerablemente sus capacidades.
La Llegada del Perceptrón
El perceptrón, diseñado por el psicólogo estadounidense Frank Rosenblatt unos quince años después de la introducción del concepto de neurona formal por McCulloch y Pitt, representa un avance significativo con la introducción del primer algoritmo de aprendizaje profundo.
El modelo del perceptrón comparte una similitud sorprendente con el que acabamos de estudiar. De hecho, la única diferencia entre el perceptrón y la neurona formal anterior radica en la adición de un algoritmo de aprendizaje que le permite determinar los valores de sus parámetros W para obtener las salidas y deseadas, eliminando así la necesidad de una búsqueda manual por parte de los humanos.
F. Rosenblatt se inspiró en la ley de Hebb en neurociencia, que sugiere que el fortalecimiento de las conexiones sinápticas entre dos neuronas biológicas ocurre cuando se excitan conjuntamente, un fenómeno conocido como el principio “cells that fire together, wire together”. Esta plasticidad sináptica es crucial en la construcción de la memoria y el aprendizaje.
La Ley de Hebb
El algoritmo de aprendizaje del perceptrón consiste en entrenar la neurona artificial con datos de referencia (X, y). En cada activación de la entrada X junto con la salida y presente en los datos, los parámetros W se refuerzan. F. Rosenblatt formuló esta idea con la siguiente ecuación:
donde los nuevos pesos se actualizan mediante una tasa de aprendizaje . es la salida de referencia, y es la salida producida por la neurona, y X es la entrada de la neurona.
Esta fórmula ajusta los pesos para minimizar la diferencia entre la salida esperada y la salida producida por la neurona. Así, si la neurona produce una salida diferente de la esperada (por ejemplo, y=0 en lugar de y=1), los pesos asociados a las entradas activadas se incrementan. Este proceso continúa hasta que la salida de la neurona converge hacia la salida esperada.
Limites del Modelo
Damas y caballeros de la comunidad científica, consideremos ahora un perceptrón compuesto únicamente por dos entradas y . Su función de agregación es y, por su forma, puede modelar relaciones lineales. Sin embargo, esta simplicidad presenta limitaciones cuando nos enfrentamos a problemas no lineales.
El Dr. Ford destaca con perspicacia: “El perceptrón, en su esencia, es como una herramienta con una perspectiva limitada. Puede tener éxito en realizar predicciones simples, pero lucha por capturar la complejidad de las relaciones no lineales presentes en el mundo real.”
Un científico en la audiencia, mostrando una comprensión profunda: “Es como si estuviéramos tratando de predecir el comportamiento de un círculo trazando solo una línea con la regla.”
Dr. Ford, sonriendo: “¡Exactamente! Es por eso que exploramos enfoques más complejos para modelar la riqueza de las relaciones.”
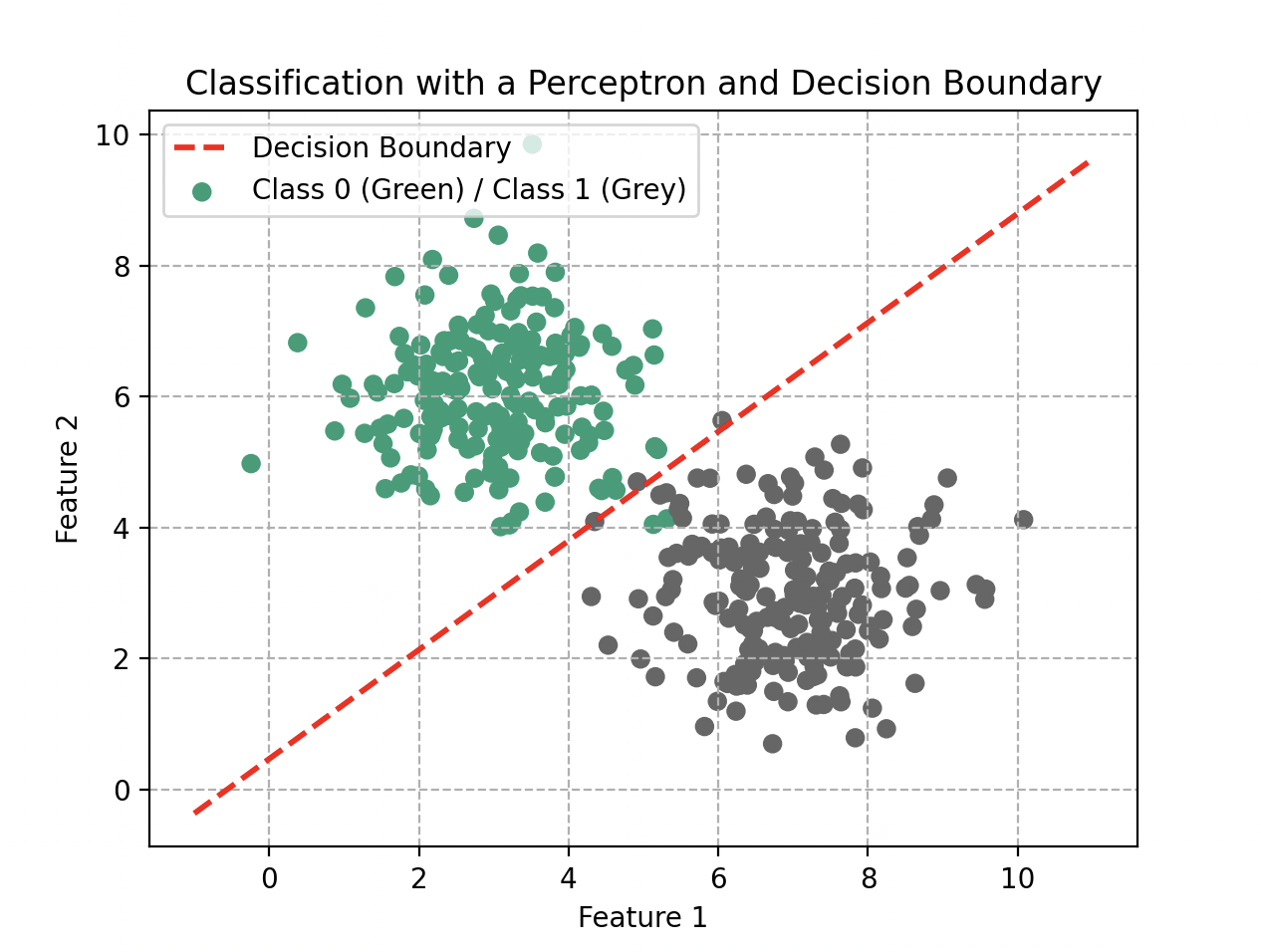
Clasificación con un perceptrón: la frontera de decisión es necesariamente una recta.
Algunos Perceptrones Adicionales
Para superar este primer problema, introduzcamos primero tres perceptrones que conectaremos entre sí. Los dos primeros recibirán cada uno las entradas y , realizarán sus cálculos según sus parámetros y luego enviarán una salida (y) al tercer perceptrón. Este último también realizará sus propios cálculos para producir una salida final.
Créditos: HBO
Intente programar tres perceptrones de este huésped y podrá trazar la representación gráfica de la salida final en función de las entradas y , obteniendo así un modelo no lineal, mucho más interesante.
Este modelo será entonces su primera red de neuronas artificiales, compuesta por 3 perceptrones distribuidos en dos capas: una capa de entrada y una capa de salida. Puede agregar tantas capas y perceptrones como desee, pero cuantos más agregue, más tiempo de cálculo y recursos se requerirán para simular resultados complejos. También puede cambiar la topología, es decir, la naturaleza de las conexiones entre las neuronas. Esto dependerá del problema a resolver. Es lo que vamos a ver ahora.
Las redes neuronales
Las redes neuronales, también conocidas como redes neuronales artificiales, son modelos computacionales inspirados en la estructura y el funcionamiento del cerebro humano. Están compuestas por neuronas artificiales interconectadas y organizadas en capas. Cada neurona recibe entradas, realiza operaciones de procesamiento y luego transmite una salida. Estas salidas se envían luego a las neuronas de la capa siguiente, creando así una arquitectura en capas.
Las redes neuronales comprenden tres tipos principales de capas:
-
Capa de entrada (Input Layer): Recibe los datos de entrada del sistema, donde cada nodo en esta capa representa una característica o variable de entrada.
-
Capas ocultas (Hidden Layers): Estas capas realizan operaciones de transformación de datos. Cada nodo en una capa oculta toma entradas, aplica pesos y sesgos, y luego produce una salida. Son cruciales para que la red aprenda representaciones complejas de los datos.
-
Capa de salida (Output Layer): Produce la predicción o clasificación final, esta capa sintetiza la información aprendida por las capas ocultas para generar la salida final.
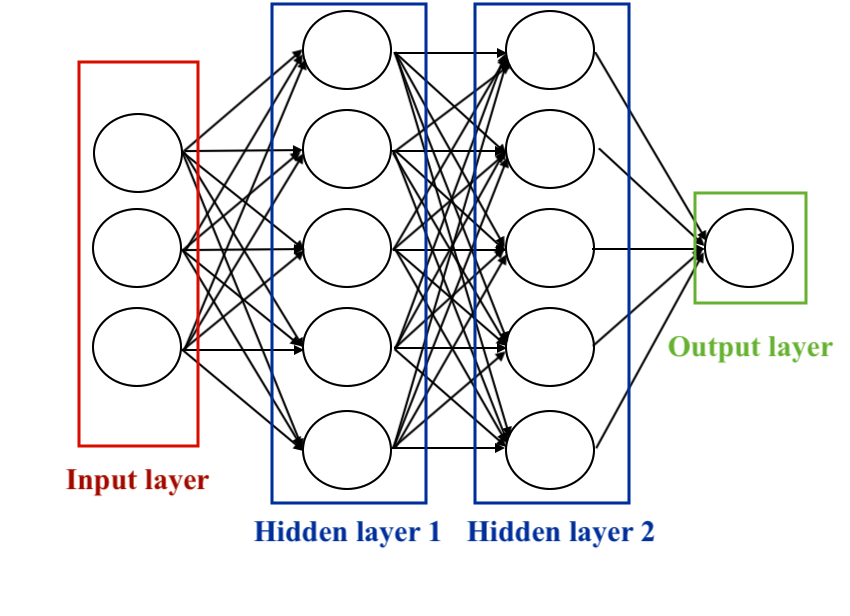
Representación de una red neuronal de dos capas (5 neuronas en cada capa) con 3 neuronas de entrada y 1 neurona de salida
La elección de las unidades ocultas es un área de investigación activa en aprendizaje automático. El número de capas ocultas se llama la profundidad de la red neuronal. La cuestión de cuántas capas hacen que una red sea “profunda” no tiene una respuesta única. En general, las redes más profundas pueden aprender funciones más complejas.
Existen varios tipos de redes neuronales según la topología de las conexiones entre los neuronas. La topología puede variar según la arquitectura específica de la red, pero algunas regularidades son comúnmente observadas. Aquí tienes algunos ejemplos de topologías:
• Perceptrón Multicapa (Multi-layer perceptron): Cada neurona de la capa está conectada a todas las neuronas de la siguiente capa. Es una configuración simple utilizada especialmente para la clasificación de imágenes.
• Red Neuronal Convolucional (Convolutional Neural Network - CNN): Especializada en el procesamiento de imágenes, utiliza filtros para analizar partes locales, reduciendo así el número de parámetros y extrayendo características importantes.
• Red Neuronal Recurrente (Recurrent Neural Network - RNN): Diseñada para procesar datos secuenciales, utiliza conexiones recurrentes para tener en cuenta la secuencia temporal de los datos.
• Memoria a Corto y Largo Plazo (Long Short-Term Memory - LSTM): Una extensión de las RNN, las LSTM procesan secuencias más largas evitando la desaparición del gradiente.
• Autoencoder: Destinada al aprendizaje no supervisado, la red autoencoder consta de una capa de codificación y una capa de decodificación. Su objetivo es reproducir la entrada mientras genera una representación latente. Se centra en la reducción de dimensiones, especialmente útil cuando hay un volumen importante de datos. Al sustituir estos datos por una representación en un espacio de dimensión inferior, se optimiza el procesamiento por los procesadores, mejorando así la eficiencia del modelo (se hablará de esto en otro artículo).
• Red Neuronal Residual (Residual Neural Network - ResNet): Introducidas para resolver el problema de la desaparición del gradiente, las ResNets utilizan conexiones residuales para facilitar el aprendizaje de representaciones más profundas.
En esta exploración, nos centraremos especialmente en las redes neuronales de propagación hacia adelante. Este es el primer tipo de red neuronal artificial, el más simple, donde la información se mueve solo hacia adelante, desde los nodos de entrada hasta los nodos de salida, sin ciclos ni bucles (se dice que es acíclico, distinguiéndose así de las redes recurrentes). El perceptrón solo que ya hemos visto, y luego su extensión más conocida, el perceptrón multicapa que veremos de inmediato.
Pero por cierto, me olvidé, ¿cómo entrenar a una red neuronal para que realice lo que se le pide, es decir, cómo encontrar los parámetros w y b para obtener el modelo correcto?
La audiencia permanece en silencio.
No se preocupen, es ahora cuando veremos eso.
Programación Cognitiva de Huésped de Reconocimiento de Dígitos Manuscritos: el Perceptrón Multicapa
Antes de que nuestros huéspedes puedan sobresalir en tareas más avanzadas, como el reconocimiento de seres humanos o incluso de emociones, es necesario introducirles en las nociones básicas, empezando por el reconocimiento de números escritos a mano, porque como dice el refrán, “antes de aprender a correr, hay que aprender a caminar”.
Para guiarles en este aprendizaje (supervisado), utilizamos una serie de imágenes de números, cada una de las cuales representa visualmente la correspondencia entre la forma manuscrita y el número en cuestión.
Nuestros invitados deben reconocer los números que se les presentan.
Créditos: HBO
Este modelo de clasificación constituye la primera red neuronal artificial de nuestros huéspedes, con una capa de entrada, varias capas ocultas por determinar y una capa de salida. Se trata de una red multicapa cuya complejidad puede aumentarse añadiendo más capas y neuronas, pero esto requerirá más tiempo de cálculo.
Ahora vamos a explorar el proceso por el que pasan nuestros huéspedes al programar para dominar esta tarea.
Asimilación de Datos de Entrenamiento (DataSet)
A nuestros huéspedes se les suministran datos de entrenamiento, consistentes en 60.000 ejemplos de imágenes en escala de grises de dígitos manuscritos con una resolución de 28 píxeles por 28 píxeles y sus respectivas correspondencias. Estos datos son cruciales para enseñar a los hosts a generalizar a partir de ejemplos existentes. Y 10.000 imágenes de prueba del mismo formato para examinarlas, es decir, para ver lo bien que han clasificado las imágenes. Aquí están los números del 0 al 9:
Estas imágenes son simplemente matrices de datos que contienen números del 0 al 255. Cada una de las 60.000 matrices se “aplana” para formar 60.000 vectores X con 784 coordenadas correspondientes al número total de píxeles de una imagen con una etiqueta y comprendida entre 0 y 9.
Construcción del Modelo Cognitivo
El modelo cognitivo representa la estructura de la red neuronal en la mente de nuestros huéspedes, abarcando aspectos como el número de capas, el número de neuronas por capa, los parámetros de aprendizaje (W y b) e incluso las funciones de activación. El diseño del modelo depende en gran medida de la naturaleza específica de la tarea.
Los pesos y los sesgos se ajustarán continuamente a lo largo del entrenamiento para minimizar el error entre las predicciones del modelo y los resultados esperados. La inicialización y actualización adecuadas de estos parámetros son cruciales para optimizar el rendimiento de la red. Otros parámetros, como el número de capas y el número de neuronas, se ajustarán manualmente para encontrar el modelo más eficiente en un plazo razonable y sin consumir excesivos recursos, ya que no es deseable que un huéspedes tarde 30 segundos en reconocer un dígito manuscrito o que esté inactivo durante esta tarea.
Propagación hacia delante
La primera etapa de este proceso cognitivo es la propagación hacia delante: el cerebro huéspedes hace circular la información de los píxeles de la primera capa a la última para producir una salida y (la etiqueta manuscrita del dígito).
Analicemos cómo funciona.
• La capa de entrada está formada por 784 neuronas, cada una de las cuales analiza un píxel de la imagen. No tiene parámetros.
• Las capas ocultas (sigmoide): a continuación, dotamos a nuestros huéspedes de dos capas ocultas, cada una de ellas compuesta por 100 neuronas con una función de activación de tipo sigmoide.
La salida de la primera capa es un vector (A^1) que contiene 100 coordenadas (una por cada neurona). Los cálculos realizados para cada elemento son sencillos y se basan en el modelo del perceptrón: calculamos la función de agregación y luego le aplicamos la función de activación.
Créditos: HBO
Todo está escrito en forma de matriz compacta.
La segunda capa oculta proporciona un vector (A^2) que también contiene 100 coordenadas. Hacemos lo mismo para la segunda capa
• La capa de salida: Por último, como el objetivo es clasificar números del 0 al 9, una capa de salida de 10 neuronas, acompañada de una función de activación de tipo softmax, es más que suficiente.
La función softmax asigna probabilidades a cada clase posible. Para cada imagen de entrada, asigna una probabilidad de pertenecer a la clase 0, 1, 2, …, hasta 9. Aquí está un ejemplo
Créditos: HBO
Según esta tabla, no hay prácticamente ninguna duda de que este número es el 99% 7, por lo que el host le asignará este número. En general, el huésped asignará a la imagen la etiqueta con mayor probabilidad.
Esta función permite interpretar los resultados como la confianza del modelo en cada clase, y facilita la toma de decisiones en el contexto de una tarea de clasificación multiclase.
Análisis de Errores Cognitivos: la Función de Costes
En la segunda fase, la red neuronal analiza el error entre la salida y del modelo (su predicción) y la salida de referencia esperada . Esta evaluación se realiza mediante una función de coste frecuentemente utilizada en tareas de clasificación, incluido el reconocimiento de dígitos manuscritos, en este caso la entropía cruzada categórica, que ya hemos encontrado (de otra forma).

Créditos: HBO
Recordemos su expresión:
\begin{align*}L(W,b)=-\frac{1}{n}\sum_{k=1}^nleft[y^{(k)}\log{y_{\text{ref}}}+\left(1-y^{(k)}\right)\log{\left(1-y_{\text{ref}}\right)}\right].\end{align*}En general, puede ser la salida final pero también cualquier salida de capa neuronal con i la capa i-ésima que colocamos en una matriz llamada . Esto da la siguiente fórmula matricial:
Es un elemento crucial del análisis cognitivo del modelo y mide la diferencia entre las probabilidades predichas por el modelo y las probabilidades reales de las clases. Su objetivo es cuantificar adecuadamente la discrepancia entre las predicciones de la red neuronal y las verdaderas etiquetas asociadas a las imágenes de los dígitos. La minimización eficiente de esta función de coste durante el entrenamiento ayuda a refinar los parámetros del modelo para obtener un mejor rendimiento.
Comprender los Mecanismos
El tercer paso es la retropropagación. Los huéspedes miden cómo varía esta función de coste en relación con cada capa del modelo, trabajando hacia atrás desde la última a la primera. En otras palabras, analizarán el error en la capa de salida y en la penúltima capa, luego en la penúltima capa y en la penúltima capa, y así sucesivamente, hasta llegar a la capa de entrada.
En resumen, tenemos que calcular cómo se propaga el error de la salida a la entrada para reducirlo. En esta red con dos capas ocultas, esto da 6 expresiones aterradoras (si sólo recuerdas la frase anterior, está bien):
Empezaremos por la última (de la salida a la segunda)
penúltimo (penúltimo)
y finalmente la entrada (de la primera a la entrada)
Créditos: HBO
Optimización Mental
Por último, la cuarta etapa es la optimización mental. Los huéspedes ajustan mentalmente cada parámetro del modelo mediante el descenso de gradiente (¿lo recuerdas? consulta el artículo Wall-E: El Pequeño Minero de Oro), antes de volver a la primera etapa, la propagación hacia delante, para iniciar un nuevo ciclo de entrenamiento.
con la tasa de aprendizaje de todas las neuronas.
En resumen, este proceso permite a nuestros huéspedes dominar hasta cierto punto el reconocimiento de dígitos manuscritos, con una tasa de éxito de alrededor del 83%, aunque este rendimiento no es excepcional. He aquí algunos de los errores que cometen nuestros huéspedes:
Es evidente que algunos números manuscritos pueden resultar confusos, incluso para el ojo humano, mientras que otros parecen inequívocamente identificables, como el 3 anterior.

Créditos: HBO
Así, ajustando unos pocos parámetros, resulta relativamente fácil mejorar significativamente el rendimiento del modelo y alcanzar una precisión del 94%, una habilidad crucial en su camino hacia la adquisición de tareas cognitivas más avanzadas.
A medida que nuestros invitados progresen, ampliarán sus áreas de especialización, abriendo nuevas posibilidades para experiencias más inmersivas en Westworld.
Los Huéspedes de Westworld: de los Números a las Caras
En conclusión, mis queridos invitados, nuestra primera exploración de los misterios del Aprendizaje Profundo termina aquí. Estoy encantado de haberles desvelado una serie de conceptos, como las neuronas formales, los perceptrones y los perceptrones multicapa. Hemos analizado un ejemplo concreto en el que los huéspedes de Westworld, utilizando sus procesadores, han adquirido la capacidad de reconocer e interpretar números escritos a mano con una precisión desconcertante.
Pero no nos equivoquemos, esta red neuronal por sí sola dista mucho de ser suficiente cuando el mundo que hay que analizar tiene una resolución mayor. El número de parámetros de entrenamiento que había que ajustar para nuestro perceptrón multicapa (¡eran muchos! 89.610 parámetros) de sólo dos capas ocultas de 100 neuronas era relativamente pequeño para funcionar en máquinas de bajo consumo. Ahora imagine simular un modelo así con cientos de capas y miles de neuronas por capa. Sería imposible. Por eso se han desarrollado otras técnicas, como las redes neuronales convolucionales, que utilizan filtros para analizar elementos característicos de la imagen.
Por último, y lo dejo aquí, no visualicemos como “inteligente” una inteligencia artificial que discierne rostros, objetos complejos o emociones. Porque aunque los huéspedes parezcan acercarse asombrosamente a la humanidad en sus interacciones, recordemos siempre que no son más que máquinas.
Dr. Ford - “Recuerda, los huéspedes no son reales. No son conscientes.”
Crédits: HBO
Bibliografía
F. Rosenblatt, The Perceptron, A perceiving and recognizing automaton, Cornell Aeronautical Laboratory, 1957
F. Rosenblatt, The Perceptron: A Probabilistic Model For Information Storage And Organization in the Brain, Psychological Review, vol. 65, no 6, 1958
M. Tommasi, Le Perceptron, Apprentissage automatique : les réseaux de neurones, cours à l’université de Lille 3.
D.B. Parker, Learning Logic , Massachusetts Institute of Technology, Cambridge MA, 1985.
G. Saint-Cirgue, Machine Learnia, Youtube Channel.
USI Events, Deep learning, Yann LeCun on Youtube.
Nota
El código fuente de las tres implementaciones (perceptrón a mano, perceptrón multicapa para reconocimiento de dígitos manuscritos y la versión Keras) está disponible en GitHub.