
Como un robot fiel a su misión y entre algunas estimaciones de oro, Wall-E no olvida su tarea principal: clasificar la basura. Es durante sus expediciones a los rincones más remotos del planeta que se enfrenta al desafío supremo que estimula su mente curiosa. Entre los objetos que recolecta, Wall-E se encuentra con una colección variada de viejos componentes electrónicos — algunos en buen estado que lleva a la base, y otros defectuosos que almacena en un rincón.
Apasionado por tales objetos, comienza a desatornillar, desmontar y clasificar cuidadosamente cada componente en dos categorías distintas (clasificación binaria): por un lado las piezas de metal preciosas (clasificación multiclase) y por el otro el plástico sin valor. La pregunta fundamental es: ¿cómo lleva a cabo tal misión?
¡Es muy recomendable haber leído los Episodios I y II antes de continuar!
Los Nuevos Horizontes de Wall-E: la Clasificación
La épica aventura de nuestro intrépido robot solitario, Wall-E, adquiere una nueva dimensión fascinante cuando explora el vasto reino de la clasificación. Después de dominar brillantemente el arte de la regresión en el episodio anterior (ver Wall-E: El Pequeño Minero de Oro), Wall-E emprende valientemente una nueva fase, sumergiéndose en la clasificación binaria entre metales preciosos y plásticos. Este primer paso preparatorio marca el comienzo de una búsqueda más compleja en la que Wall-E despliega audazmente sus habilidades de clasificación.
Aprovechando sus éxitos iniciales, Wall-E decide ampliar su alcance abordando la clasificación multiclase de metales, convirtiendo al algoritmo K-Nearest Neighbors (KNN) en su aliado preferido. Este nuevo desafío exige una comprensión más profunda, ya que no solo debe distinguir entre dos categorías sino también clasificar diferentes tipos de metales como bronce, oro y plata.
El Elemento Clave: Siempre los Datos
Conociendo las Muestras
Cada ejemplo era un elemento con características específicas, como la densidad , la conductividad térmica , eléctrica , etc. Para ilustrar nuestro caso simplemente, consideraremos solo la variable de densidad .
Para cada muestra , Wall-E anota si es un metal (etiquetada ) o un plástico (etiquetada ). Aquí hay un ejemplo concreto de 5 muestras (entre las 650 que ya conoce):
| Muestra | Densidad | Material |
|---|---|---|
| 1 | 2.165747 | Plástico |
| 2 | 7.151579 | Metal |
| 3 | 0.901240 | Plástico |
| 4 | 19.24357 | Metal |
| 5 | 12.54564 | Metal |
Las Fronteras de Decisión
La diferencia con el problema anterior es que aquí debemos definir lo que se llama una frontera de decisión. En lugar de mirar cada objeto individualmente, Wall-E decide dividir este espacio en diferentes regiones. Cada región estaría destinada a recibir un tipo específico de objeto, ya sea metal o plástico. Los límites de estas regiones definirán las fronteras.
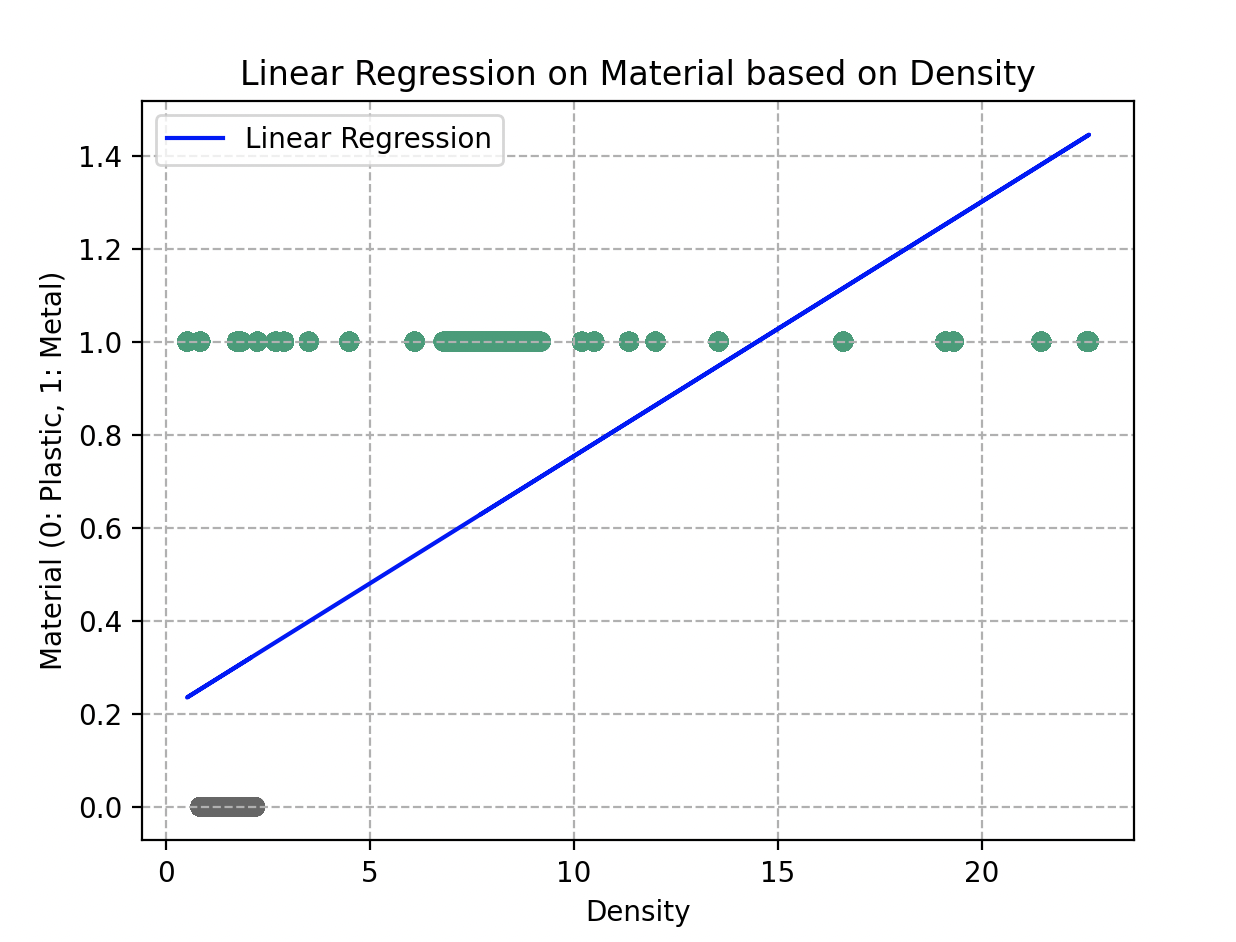
Cuando Wall-E dibuja estas fronteras, quiere asegurarse de que los objetos similares se encuentren en la misma región. Idealmente, le gustaría que los dos grupos estuvieran perfectamente separados, como si estuvieran en cajas distintas. Una simple línea recta podría servir.
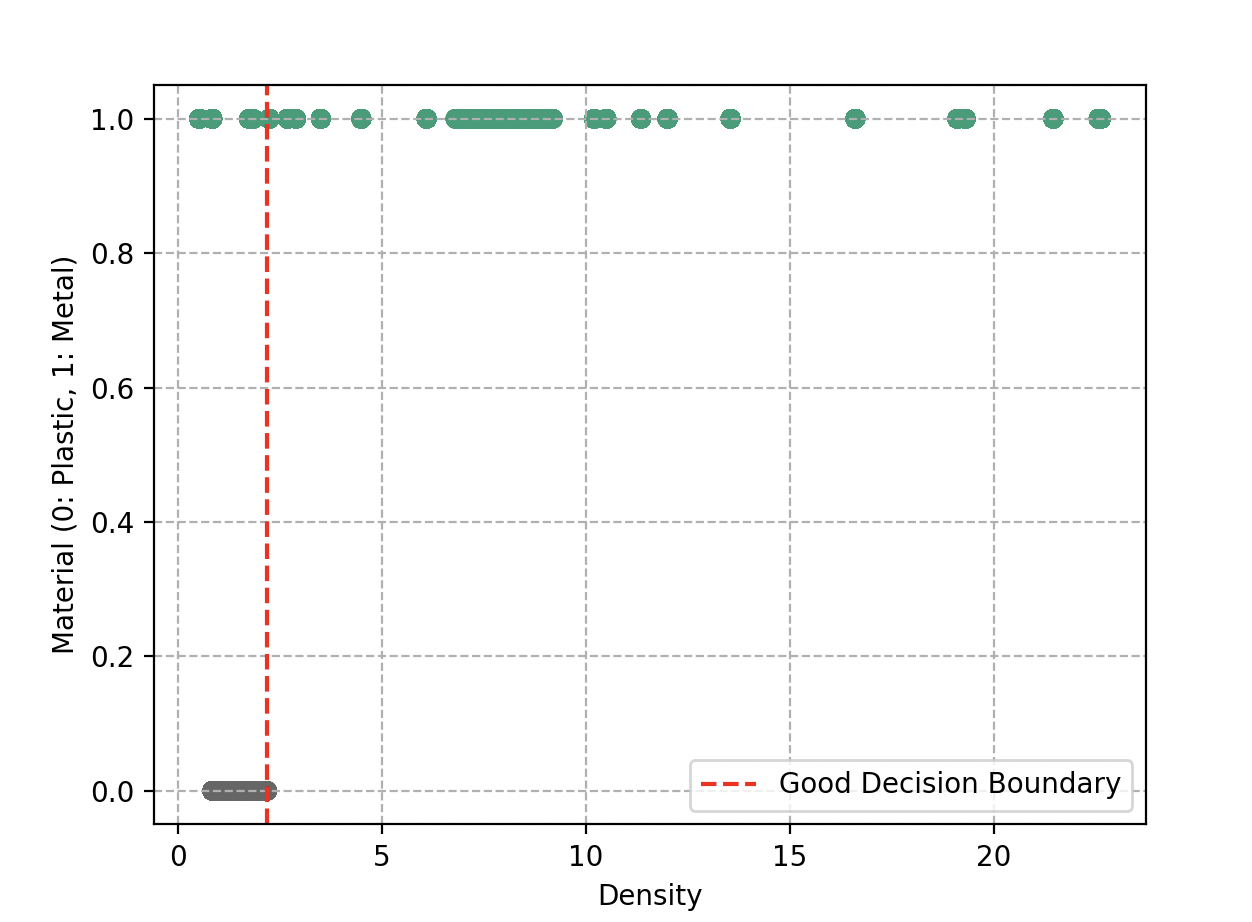
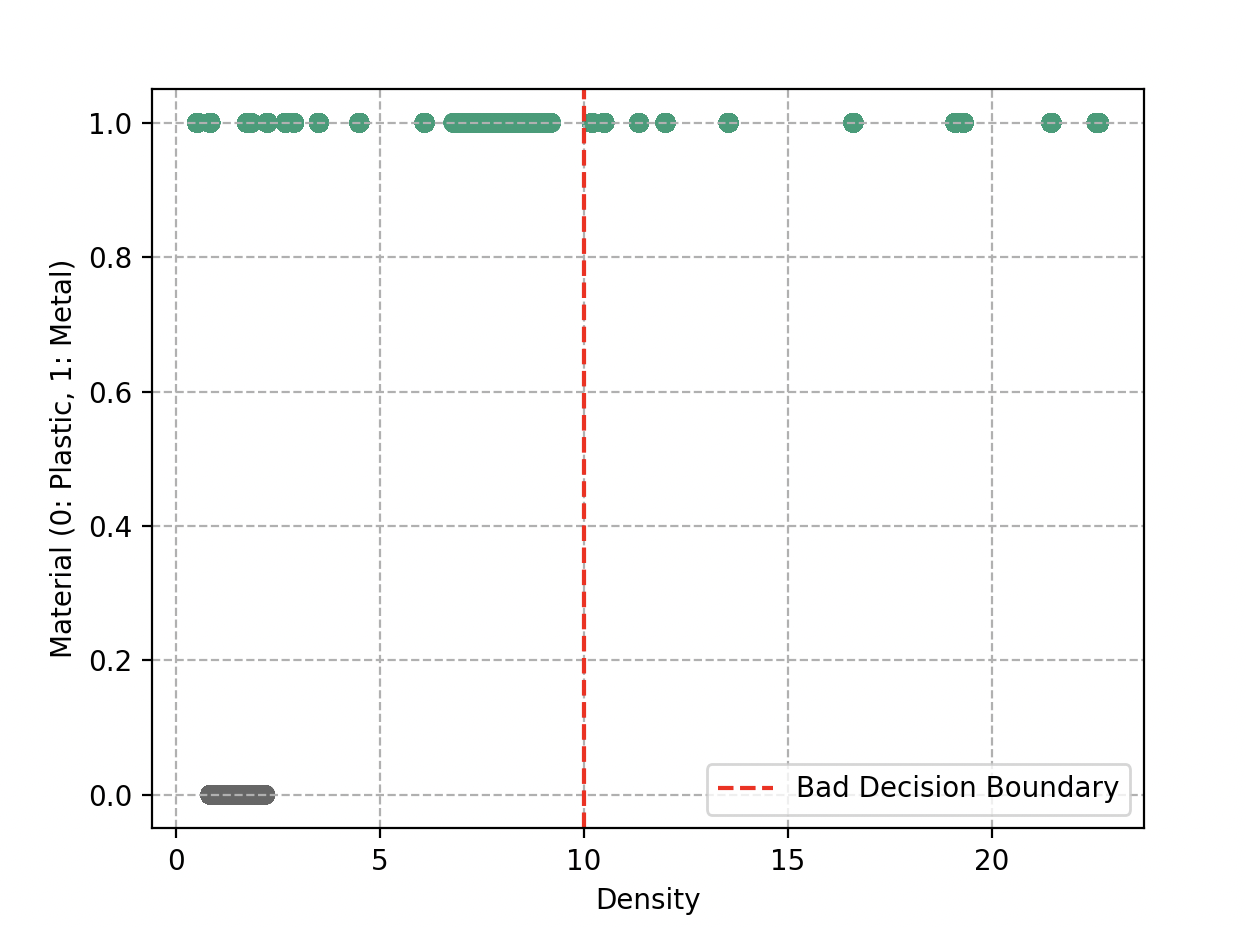
Sin embargo, la realidad no siempre es tan simple. A veces hay objetos que terminan al lado equivocado de la línea. Wall-E también es consciente de que no debe complicar la tarea dibujando fronteras zigzagueantes y complejas. Eso podría llevar a un sobreajuste.
Creación del Modelo de Clasificación Binaria
Wall-E opta por un modelo clásico de regresión logística cuya función asociada (entre 0 y 1) se expresa de la siguiente manera:
Se llama función sigmoide (por su forma de “S”).

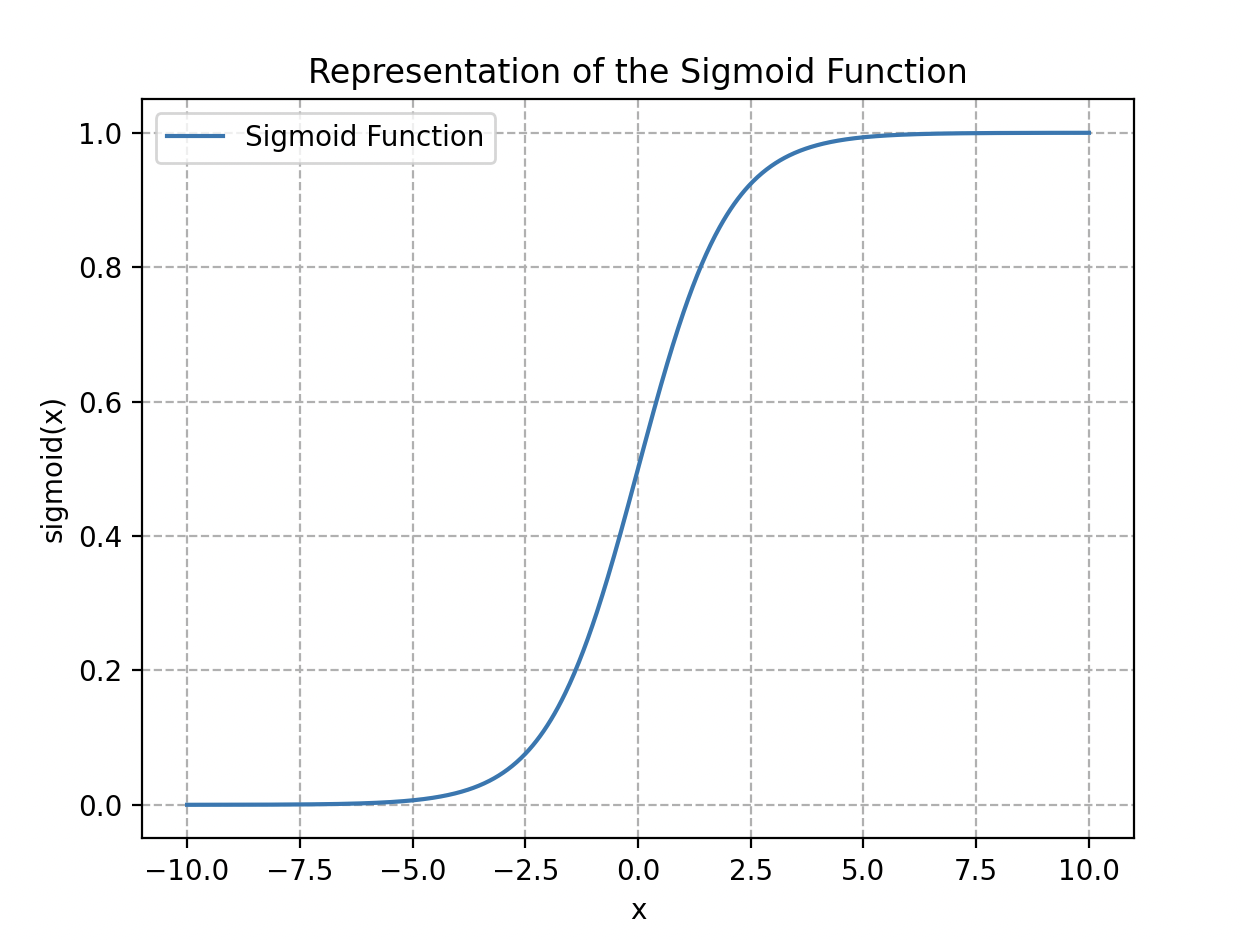
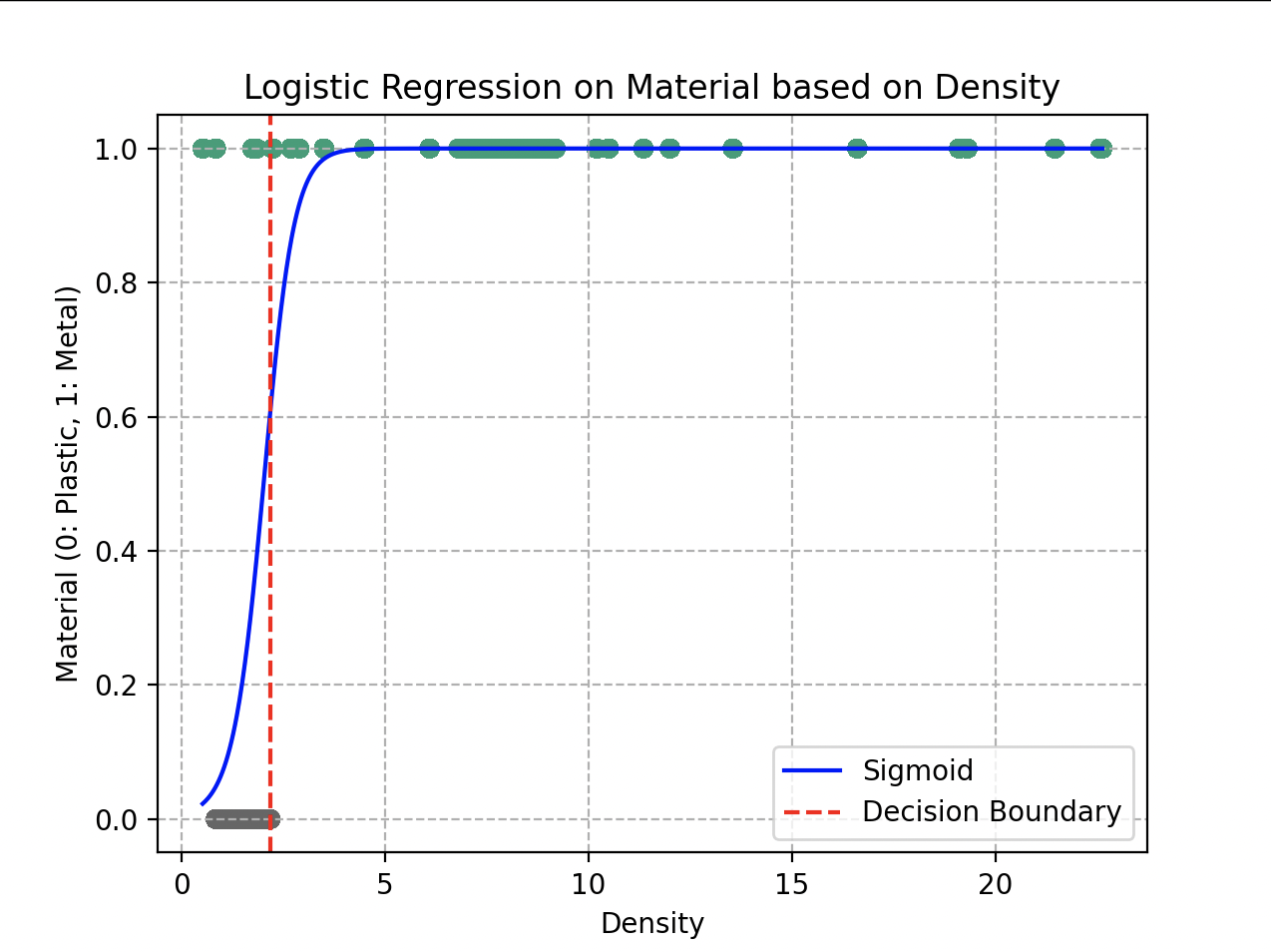
Representación de la función logística o sigmoide.
Aplicando esta función a nuestro dataset, obtenemos , donde puede ser una función lineal o polinómica , con , y como parámetros a ajustar.
La gran ventaja de esta función es que podemos definir muy fácilmente una frontera de decisión fijando un valor umbral de decisión. Si la probabilidad es mayor que 0,5, se clasifica el objeto como “metal”; si es menor que 0,5, será plástico.

Evaluación de las Predicciones: la Función de Coste
Wall-E elabora su modelo, pero quiere evaluar la precisión de sus predicciones. Para ello, podría usar una función de coste clásica de la regresión, el MSE (ver Wall-E: El Pequeño Minero de Oro):
Sin embargo, esta función de coste no es convexa: tiene varios mínimos locales. Esta peculiaridad hace que el algoritmo de descenso de gradiente sea poco eficaz, ya que usando la analogía de un relieve montañoso, Wall-E corre el riesgo de quedar atrapado en un mínimo local que no es necesariamente el mínimo global de la curva.
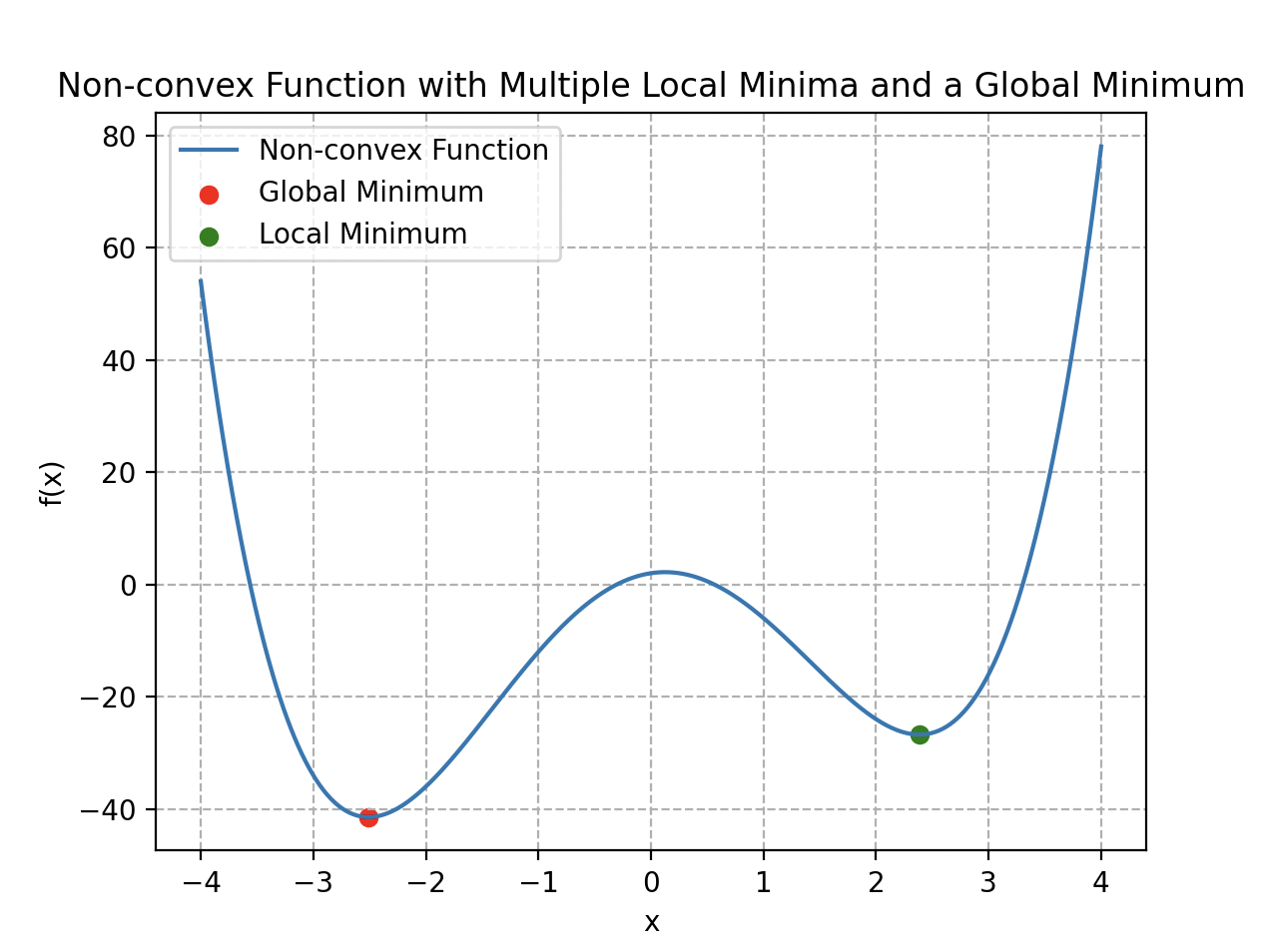
Ejemplo de función no convexa con varios mínimos locales y un mínimo global.
Wall-E introduce entonces una nueva función de coste basada en el logaritmo (log-verosimilitud negativa):
Esta función posee la propiedad de convexidad, lo que significa que tiene un único mínimo global y ningún mínimo local. Esto facilita el uso del descenso de gradiente para ajustar los parámetros del modelo.
La primera parte de la función de coste, cuando una etiqueta es 1, está representada por . La segunda parte trata los casos donde la etiqueta es 0: .
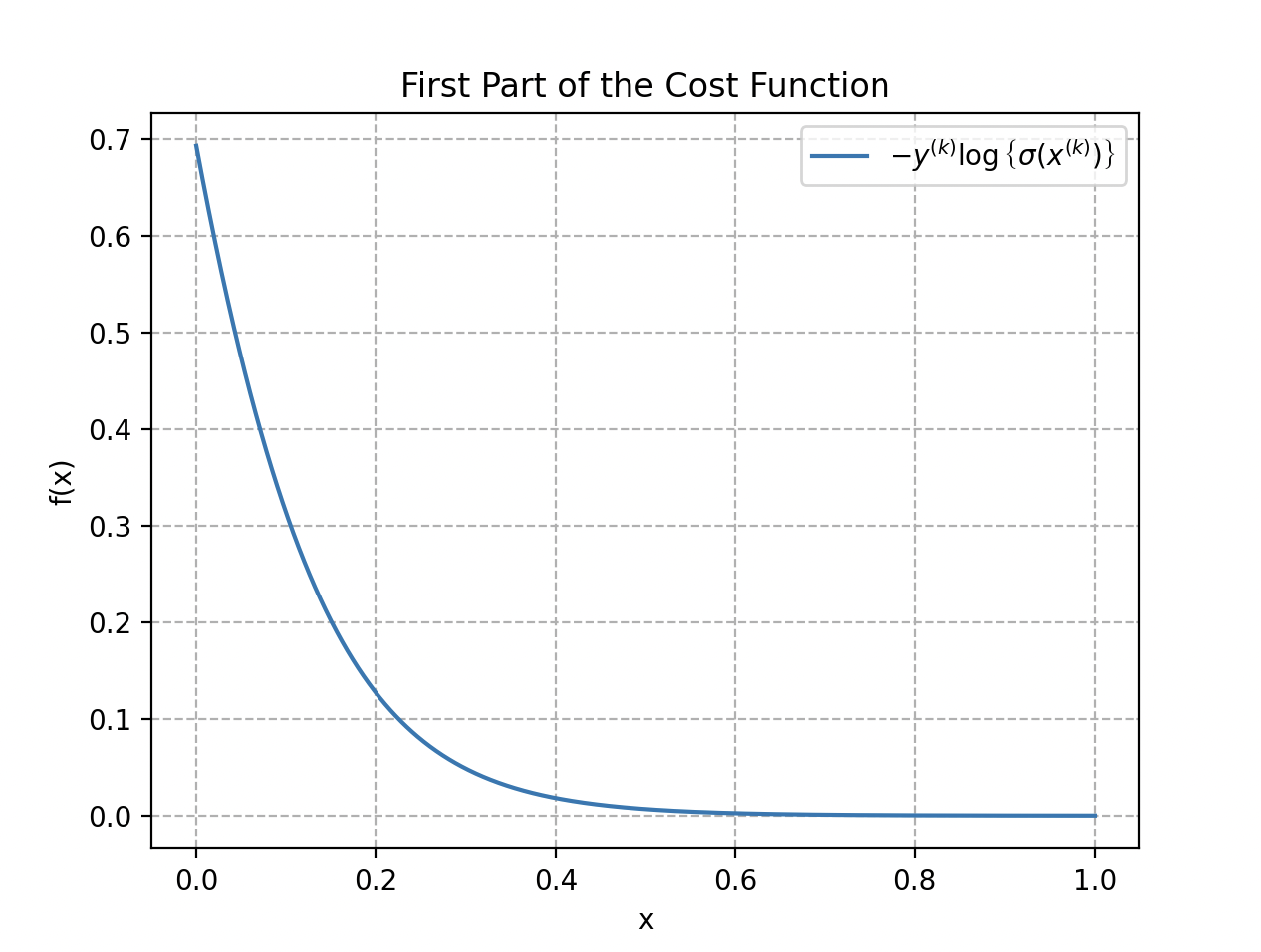
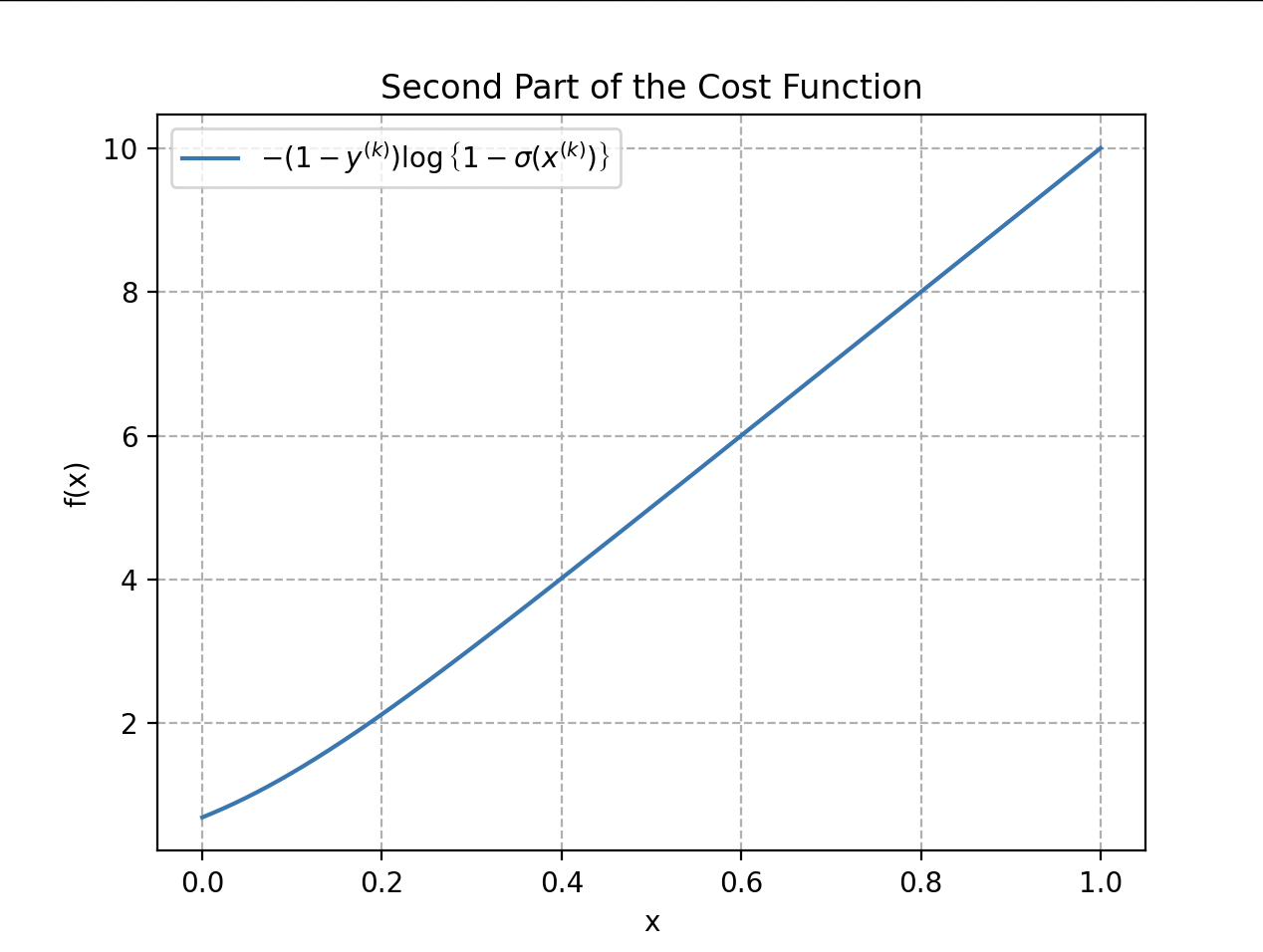
Cuando solo la primera parte de la función actúa; cuando , solo la segunda. La función de coste total es el promedio de estas dos partes, tomado sobre todos los ejemplos de entrenamiento, para obtener una medida global del ajuste del modelo a los datos de entrenamiento.
El Re-Descenso de Gradiente
Hacemos exactamente lo mismo que para la regresión, pero con la nueva función de coste. Los gradientes se escriben:
Y la actualización de los parámetros:

Créditos: Disney/PIXAR
El Poder del Pequeño Clasificador de Basura
En notación matricial, con el vector , la matriz y el vector de parámetros , la función sigmoide se aplica componente a componente:
La función de coste se convierte en:
y su gradiente:
con la actualización:
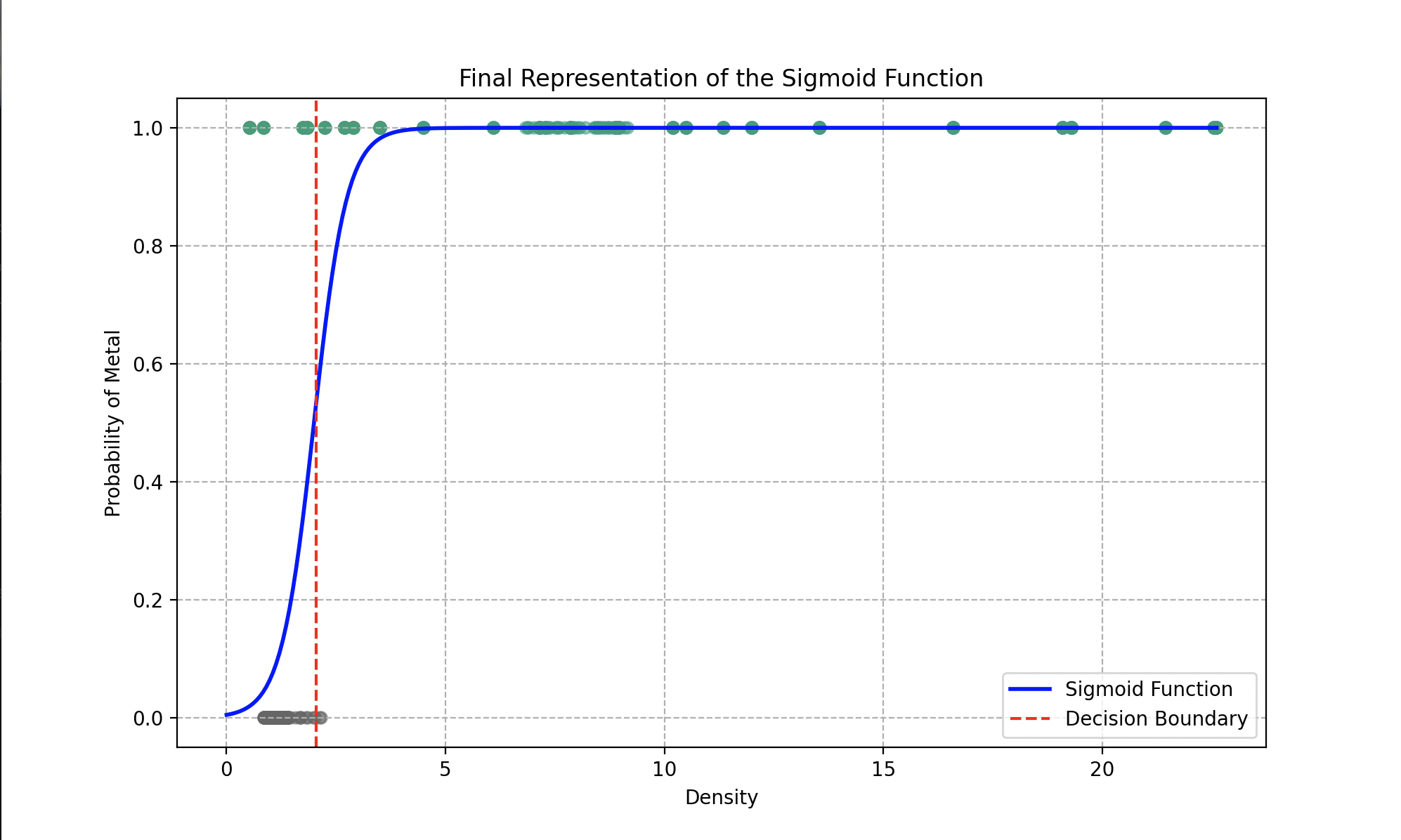
Representación final de la función sigmoide ajustándose lo mejor posible a los datos presentes.
Los parámetros óptimos obtenidos tras el descenso de gradiente son y . El modelo puede determinar, con una precisión global del 93%, si el material proporcionado es metal o plástico.
Más Allá de la Clasificación de Basura: Determinar el Tipo de Metal
Adentrándose más profundamente en la clasificación de metales, Wall-E se enfrenta a un desafío más complejo: determinar el tipo específico de metal entre una variedad de aleaciones que incluyen bronce, oro, plata y muchas otras.
Para enfrentar este desafío, la herramienta predilecta de Wall-E se convierte en el algoritmo de los K vecinos más cercanos (KNN). Aquí está la lista de todos los metales puros registrados por Wall-E:
| Metal | Conductividad Eléctrica (Giga S/m) | Densidad |
|---|---|---|
| Acero | 1.5 | 7.500 - 8.100 |
| Aluminio | 37.7 | 2.700 |
| Plata | 63 | 10.500 |
| Berilio | 31.3 | 1.848 |
| Bronce | 7.4 | 8.400 - 9.200 |
| Carbono (grafito) | 61 | 2.250 |
| Cobre | 59.6 | 8.960 |
| Estaño | 9.17 | 7.290 |
| Hierro | 9.93 | 7.860 |
| Iridio | 19.7 | 22.560 |
| Litio | 10.8 | 5.30 |
| Magnesio | 22.6 | 1.750 |
| Mercurio | 1.04 | 13.545 |
| Molibdeno | 18.7 | 10.200 |
| Níquel | 14.3 | 8.900 |
| Oro | 45.2 | 19.300 |
| Osmio | 10.9 | 22.610 |
| Paladio | 9.5 | 12.000 |
| Platino | 9.66 | 21.450 |
| Plomo | 4.81 | 11.350 |
| Potasio | 13.9 | 0.850 |
| Tántalo | 7.61 | 16.600 |
| Titanio | 2.34 | 4.500 |
| Tungsteno | 8.9 | 19.300 |
| Uranio | 3.8 | 19.100 |
| Vanadio | 4.89 | 6.100 |
| Zinc | 16.6 | 7.150 |
Esto simula aleaciones metálicas, donde cada aleación se considera compuesta por un metal puro a determinar y por impurezas que modifican ligeramente sus características. La base de datos de Wall-E contiene 300 muestras para cada tipo de aleación metálica. Aquí hay cinco muestras, cada una con sus propiedades distintivas:
| Metal | Conductividad Eléctrica (Giga S/m) | Densidad |
|---|---|---|
| Acero | 2.7093 | 7.7446 |
| Vanadio | 5.8000 | 7.5000 |
| Hierro | 9.2600 | 8.4000 |
| Oro | 43.000 | 18.500 |
| Bronce | 7.5132 | 8.7000 |
El objetivo de Wall-E será entonces clasificar cada muestra metálica que encuentre — en función de su densidad y conductividad eléctrica — en una categoría de metales puros.
Contraste con la Clasificación Binaria: la Complejidad de la Multiclase
Wall-E, después de dominar la clasificación binaria para distinguir metales preciosos de plásticos, se da cuenta de que el siguiente paso — la clasificación multiclase — representa un desafío más complejo. Mientras que la clasificación binaria simplemente divide los objetos en dos categorías distintas, Wall-E ahora debe diferenciar entre tipos específicos. La simplicidad de una frontera de decisión como una recta ya no basta.
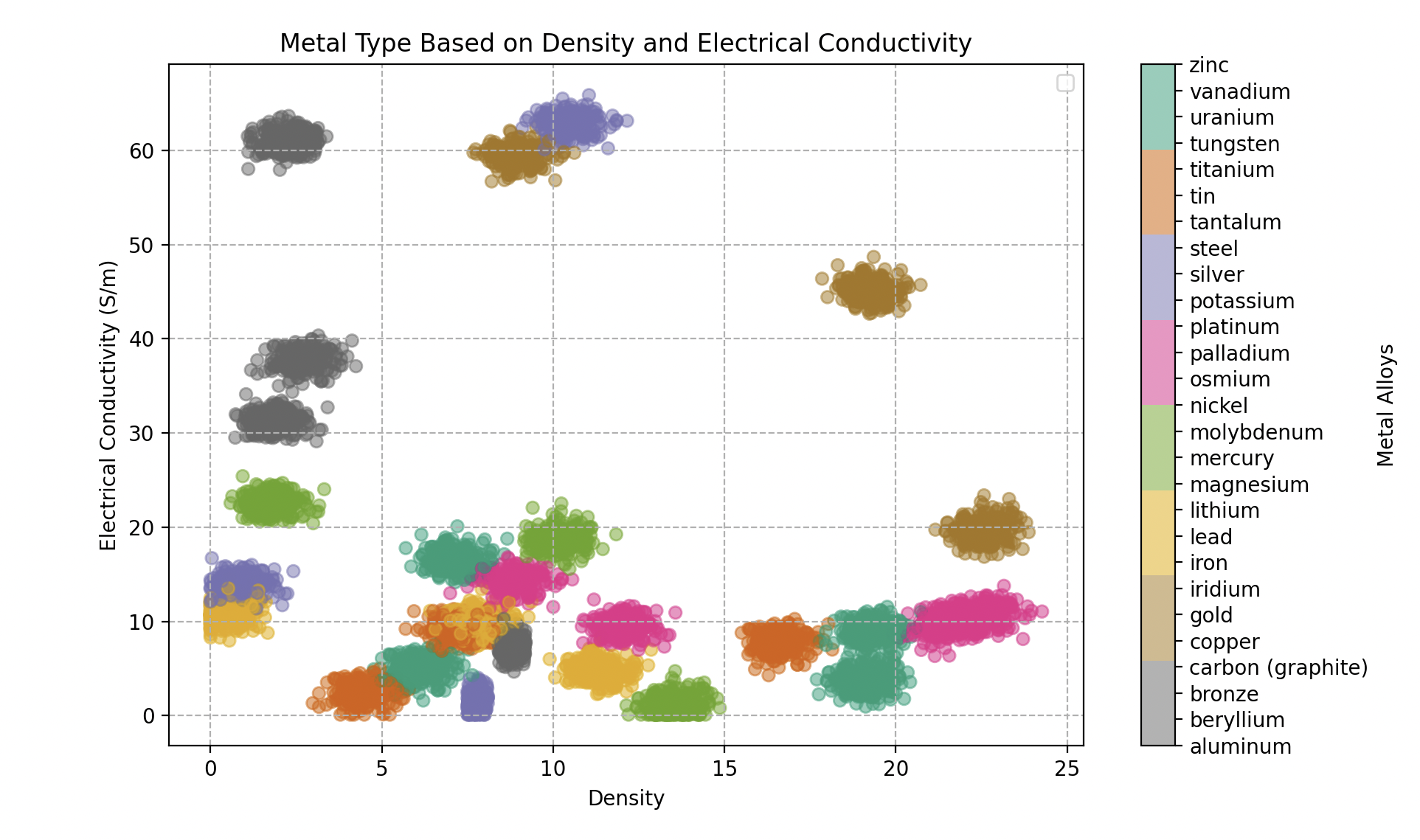
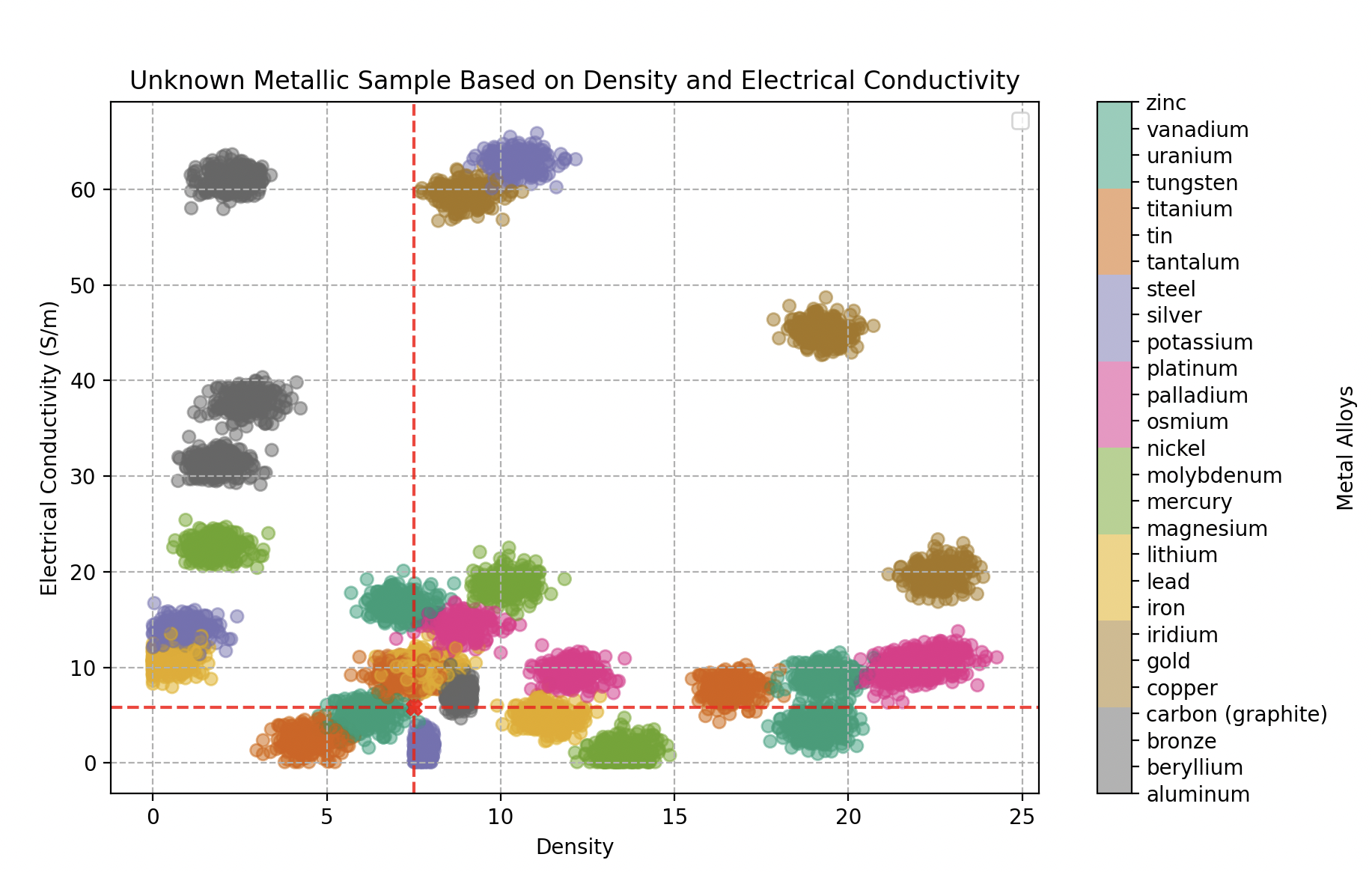
Tipo de metal en función de la densidad y conductividad eléctrica (en Giga Siemens por metro). 300 muestras para cada aleación.
En este nuevo territorio, Wall-E debe navegar por un espacio de características complejo donde los metales pueden solaparse. Esta complejidad exige un enfoque más refinado — y es aquí donde Wall-E recurre a un método que tiene en cuenta las sutilezas de las relaciones entre los metales.
El Poder de la Proximidad: K-Nearest Neighbors
La idea esencial detrás de KNN es agrupar objetos similares en el espacio de características. En nuestro contexto, si una pieza de bronce comparte características similares con otras piezas de bronce, esos objetos estarán situados cerca unos de otros en este espacio multidimensional.
El proceso es bastante intuitivo. Cuando una nueva pieza de metal debe clasificarse, Wall-E mide sus características específicas y la posiciona en el espacio de características. Luego, el algoritmo identifica los vecinos más cercanos. Una vez identificados los vecinos, KNN asigna a la nueva pieza el tipo de metal que recoge la mayoría de votos entre esos vecinos cercanos.
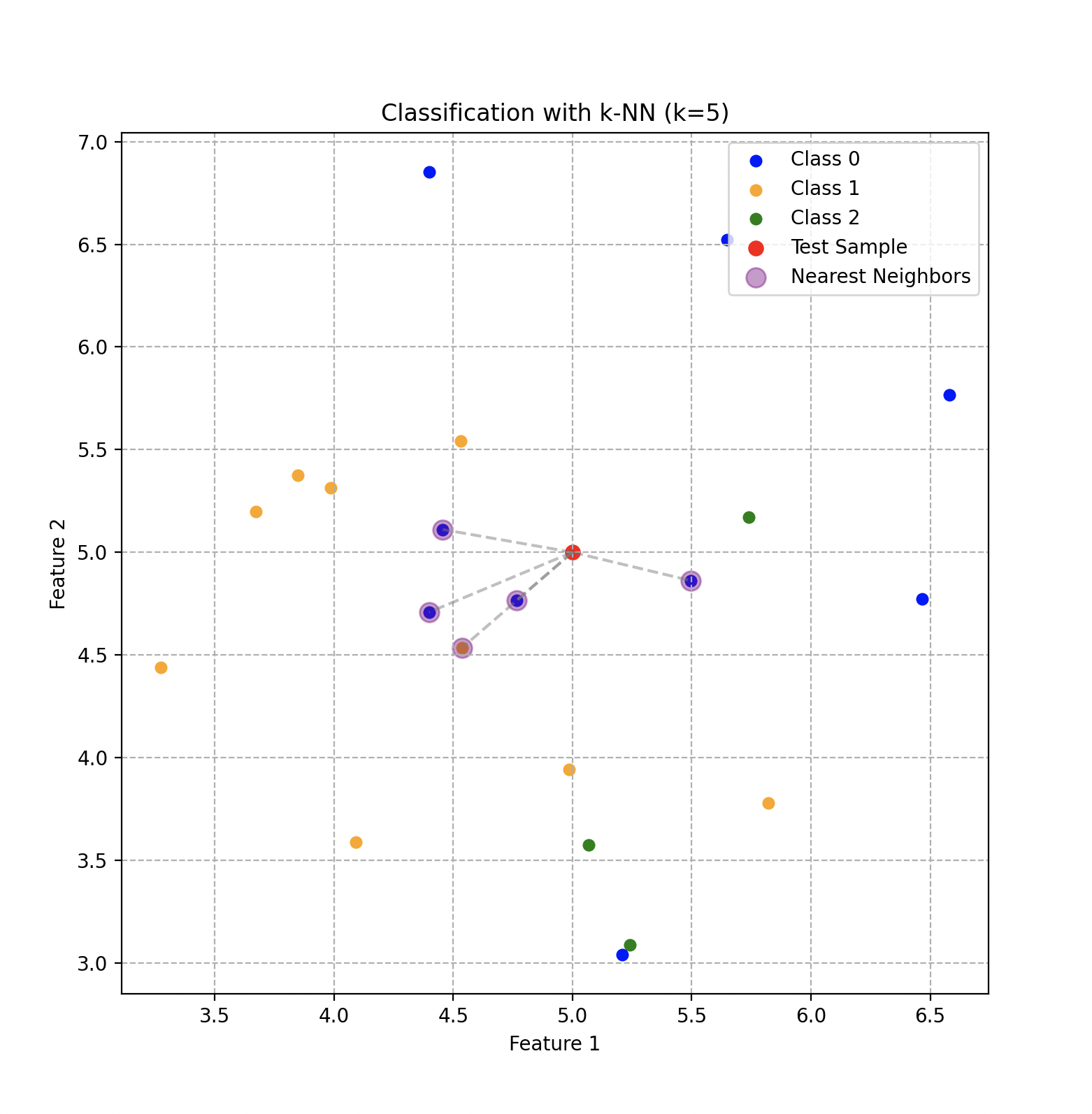
Clasificación usando el algoritmo KNN con 5 vecinos y 3 clases que dependen de dos características.
Proceso de Clasificación Metálica: los Vecinos en Acción
Wall-E busca en su base de datos relativamente extensa, que comprende diversos tipos de metales y aleaciones, cada uno asociado con características específicas como conductividad eléctrica, densidad y otras propiedades únicas. Cuando se presenta una nueva pieza de metal, Wall-E activa el algoritmo KNN para determinar su tipo:
- Medición de características: Wall-E mide las características de la nueva pieza, situándola en el espacio de características.
- Identificación de vecinos cercanos: KNN identifica los vecinos más cercanos a la nueva pieza en este espacio.
- Mayoría de votos: Wall-E asigna a la nueva pieza el tipo de metal mayoritario entre los vecinos cercanos.

Créditos: Disney/PIXAR
Con un parámetro óptimo de 20 vecinos, Wall-E puede afirmar con una confianza cercana al 95% su capacidad de identificar cualquier aleación metálica.
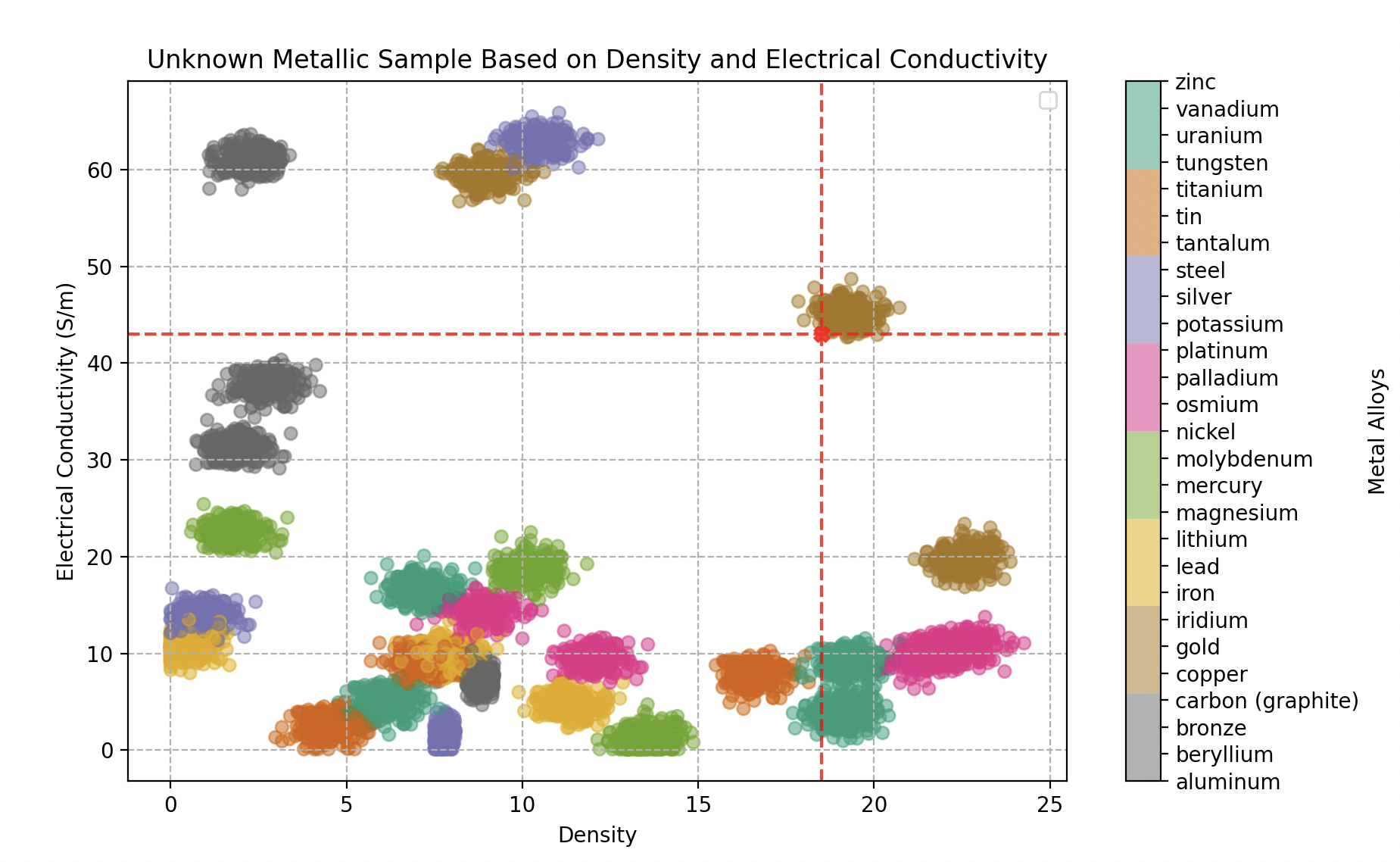
Clasificación de una muestra metálica desconocida según su densidad y conductividad eléctrica — resulta ser una aleación de oro.
- El primer objeto analizado (densidad 18,5, conductividad 43 GS/m) es identificado como oro al 100%.
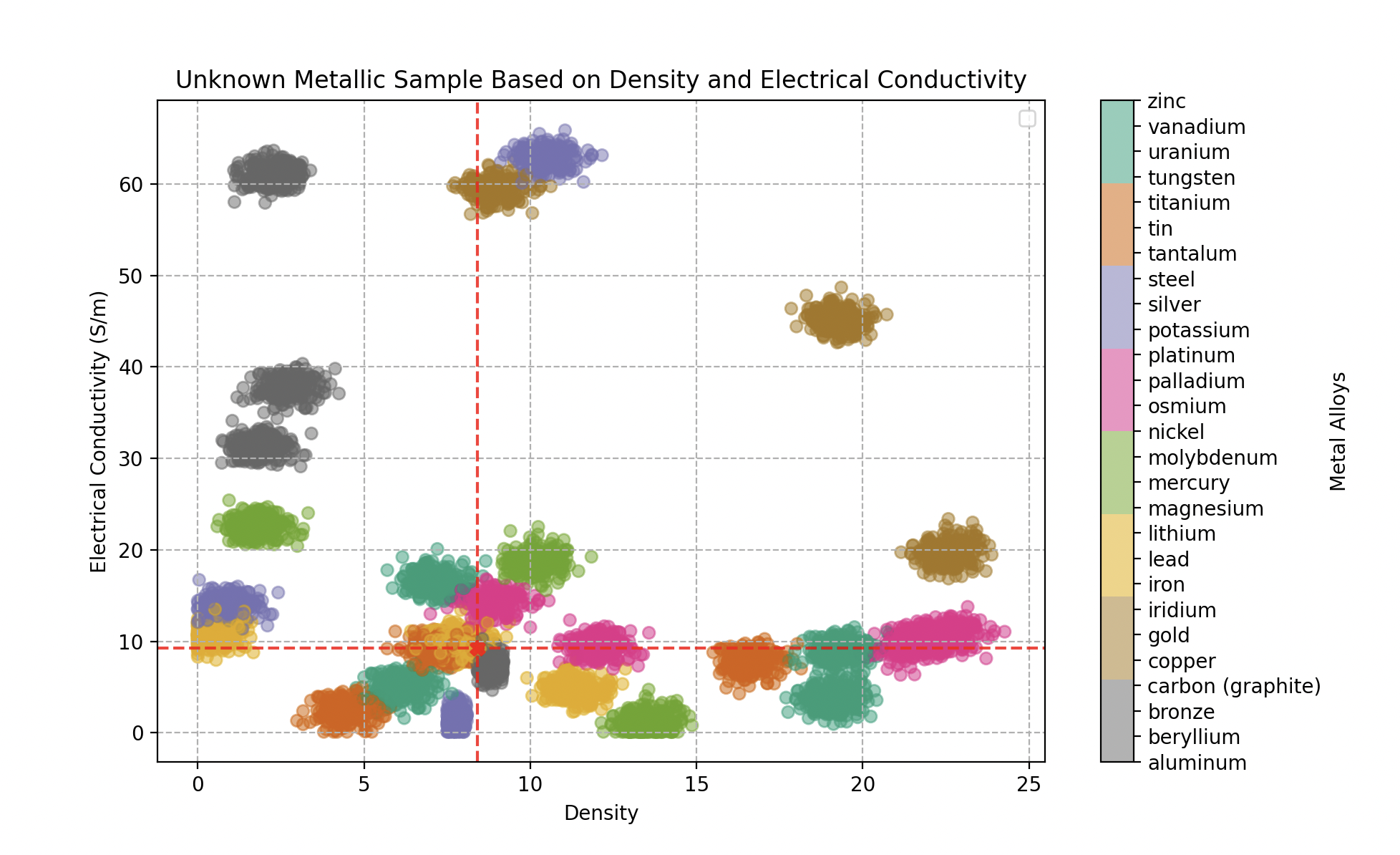
Clasificación de una muestra metálica desconocida: aleación de hierro (70% hierro, 20% bronce, 10% estaño).
- El segundo (densidad 8,4, conductividad 9,26 GS/m): 70% hierro, 20% bronce, 10% estaño.
Clasificación de una muestra metálica desconocida: aleación de vanadio (70% vanadio, 25% estaño, 5% hierro).
- El tercero (densidad 7,5, conductividad 5,8 GS/m): 70% vanadio, 25% estaño, 5% hierro.
El Arte de la Selección del Modelo
Entrenamiento y Test
Wall-E comprende rápidamente la importancia de no evaluar nunca su modelo sobre los mismos datos que sirvieron para entrenarlo. Divide el conjunto de datos en dos partes:
- Train set (80%): dedicado al entrenamiento del modelo.
- Test set (20%): reservado para la evaluación final.

Créditos: Disney/PIXAR
Validación del Modelo
Para ajustar los hiperparámetros (como el número de vecinos del KNN), Wall-E introduce una tercera sección: el validation set. Compara distintos modelos — KNN con 2, 3, 20 o 100 vecinos — siguiendo esta metodología:
- Entrenar los modelos en el conjunto de entrenamiento.
- Seleccionar el modelo con mejor rendimiento en el conjunto de validación.
- Evaluar ese modelo elegido en el conjunto de test.
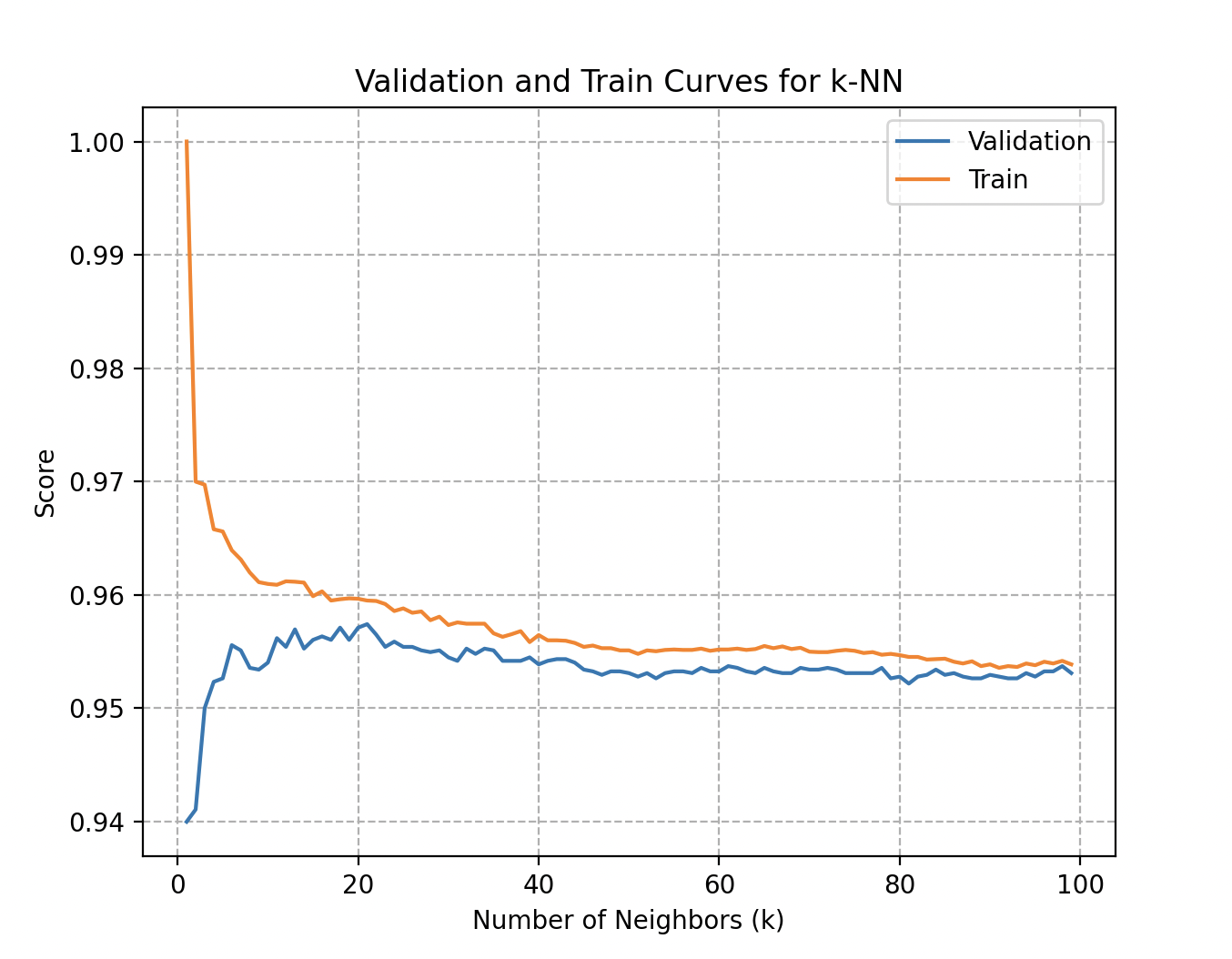
Curvas de validación y entrenamiento: precisión en función del número de vecinos usados en el algoritmo KNN.
Más precisamente, la curva de validación para el número de vecinos en KNN da respuestas a preguntas clave:
- Sobreajuste (overfitting): una brecha significativa entre la puntuación de entrenamiento y la de validación indica que el modelo es demasiado complejo y pierde generalización.
- Subajuste (underfitting): al contrario, un modelo que no ha aprendido bien los patrones en los datos de entrenamiento muestra rendimiento mediocre y predicciones poco fiables.
- Sensibilidad al parámetro: observar las variaciones de rendimiento permite elegir un valor óptimo de .
En su caso, ambas curvas alcanzan rápidamente una precisión de 95,7% a partir de unos 20 a 25 vecinos.
Validación Cruzada
Wall-E utiliza el método K-fold (con 5 particiones). Durante el entrenamiento, el modelo se entrena sistemáticamente sobre de estas particiones y se valida en la partición restante, repitiendo este proceso veces. También aprovecha el Stratified K-fold, que tiene en cuenta la distribución de clases en el conjunto de datos.
Curvas de Aprendizaje
Curioso por saber si su modelo podría beneficiarse de añadir más datos, Wall-E examina las curvas de aprendizaje. Aunque añadir datos puede inicialmente conducir a una mejora en el rendimiento, Wall-E reconoce que estos beneficios acaban por alcanzar un umbral.
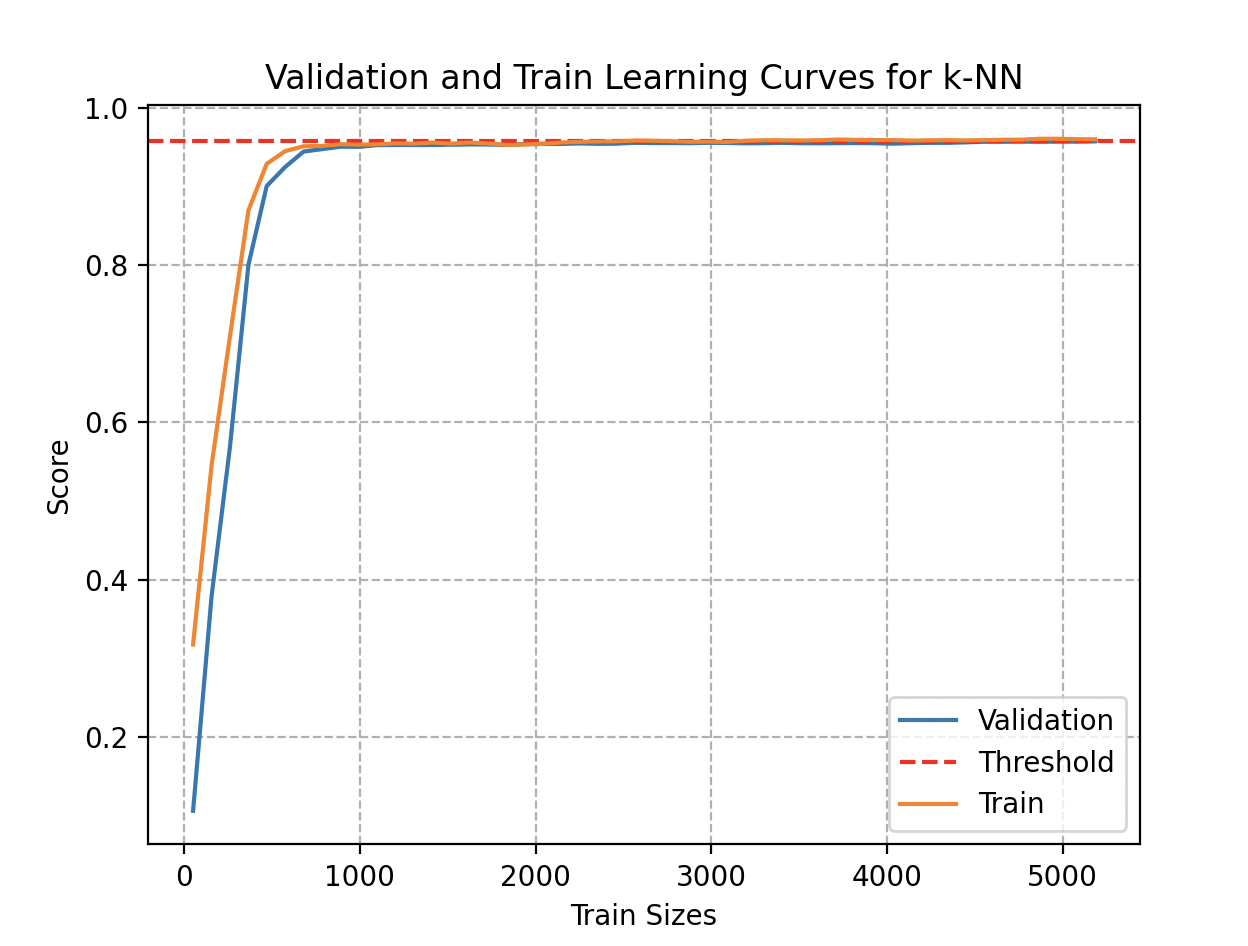
Examinando esta curva, observa que se podría haber obtenido una estimación suficientemente precisa con menos de 1000 muestras de metales. Incluso acumulando 300 muestras para cada tipo (8100 objetos en total), la precisión se estanca en 95,7%.
El Fin de una Trilogía, el Inicio de una Era Tecnológica
Este último episodio marca la conclusión de la cautivadora saga del pequeño robot Wall-E, una aventura que comenzó con los fundamentos del machine learning. Desde sus primeros pasos en el reino de la inteligencia artificial, Wall-E ha evolucionado a través de varios capítulos, explorando los principios básicos del aprendizaje automático, sumergiéndose en el estudio profundo de la regresión y, finalmente, escalando las complejas cumbres de la clasificación.
Esta saga, rica en enseñanzas, se cierra con la certeza de que Wall-E está ahora listo para enfrentar nuevos desafíos en el complejo mundo de la inteligencia artificial.

Créditos: Disney/PIXAR
Bibliografía
- G. James, D. Witten, T. Hastie y R. Tibshirani, An Introduction to Statistical Learning, Springer Verlag, 2013
- D. MacKay, Information Theory, Inference, and Learning Algorithms, Cambridge University Press, 2003
- T. Mitchell, Machine Learning, 1997
- C. Bishop, Pattern Recognition and Machine Learning, Springer, 2006
- J. Tolles, W-J. Meurer, “Logistic Regression Relating Patient Characteristics to Outcomes”, JAMA, 316 (5): 533–4, 2016
- B-V. Dasarathy, Nearest Neighbor (NN) Norms: NN Pattern Classification Techniques, 1991