
A diferencia de sus homólogos robóticos del pasado, Wall-E se destacaba por su curiosidad insaciable y su deseo de aprender. Cada día, se aventuraba en los rincones olvidados del planeta, en busca de tesoros enterrados y pasados por alto. Durante una de sus expediciones, en una antigua mina abandonada, Wall-E hizo un descubrimiento notable: muestras de oro centelleantes, ocultas bajo capas de tierra y roca. Intrigado por estos destellos dorados, se preguntó si podría divertirse estimando su valor.
Como un erudito robótico, sabía que la evaluación del precio de estas pepitas dependía de su pureza. Fue en ese preciso momento que se dispuso a explorar un problema de extrema simplicidad: la regresión lineal.
¡Se recomienda encarecidamente haber leído el Episodio I antes de continuar!
En las Profundidades del Conocimiento: la Regresión
La historia de nuestro intrépido robot solitario continúa y se enfrenta a una categoría fascinante de problemas: la regresión. Estos enigmas lo impulsan a desarrollar nuevas habilidades para estimar valores numéricos en función de datos de entrada, y ocupan un lugar destacado en su amplio repertorio de exploraciones.
Wall-E, el pequeño robot recolector de basura, se encuentra con problemas de regresión cada vez que desea predecir un valor numérico basado en ciertas características o variables continuas. Imagínenlo analizando los datos que ha recopilado mientras se esfuerza por determinar el precio de una pepita de oro en función de su pureza. En esta búsqueda, debe establecer una relación matemática entre los datos que tiene, como la pureza del oro, y los valores que desea predecir, es decir, los precios de estas valiosas pepitas.
Una de las dificultades que enfrenta Wall-E es elegir el modelo de regresión adecuado. Se pregunta si debe optar por una regresión lineal simple, lo que significa que supone una relación lineal entre la pureza del oro y su precio, o si debe explorar modelos más complejos, como una regresión polinómica. La elección del modelo es crucial ya que afectará la precisión de sus predicciones.
Otro problema que Wall-E debe resolver es cómo evaluar el rendimiento de su modelo. No puede permitirse cometer errores en sus estimaciones, ya que un error en la estimación del precio del oro podría tener consecuencias potencialmente desastrosas. Por lo tanto, explora diversas medidas de error, como el error absoluto medio y la raíz cuadrada del error cuadrático medio (por ahora, es un galimatías), para evaluar la precisión de sus predicciones.
Uno de los desafíos más intrigantes a los que se enfrenta Wall-E en los problemas de regresión es la optimización de los parámetros del modelo. Debe recorrer un proceso iterativo de ajuste de estos parámetros para minimizar el error entre sus predicciones y los valores reales. Wall-E se embarca entonces en el descenso del gradiente, una técnica que lo ayuda a encontrar los parámetros óptimos al minimizar una función de coste que recopila los errores del modelo.
Cada problema de regresión que Wall-E aborda es único, ya que los datos y los objetivos varían. Sin embargo, su perseverancia e ingenio, combinados con sus habilidades en aprendizaje automático, le permiten superar estos desafíos y estimar con precisión los valores numéricos, ya sea el precio del oro o cualquier otra tarea de regresión.
La Cosecha
Poco después de la fuga de la humanidad, el joven robot sintió como un viento de soledad invadía sus circuitos impresos. Para pasar el tiempo, después de un día de arduo trabajo, recorre terrenos lejanos, busca en los escombros de las grandes reservas de oro, analiza cada una de las aleaciones preciosas, examina cada pequeña pepita de oro para determinar su pureza y enumera todos los ejemplos de oro terrestre mostrándolos en una tabla con sus respectivos precios (aquí están las primeras 5 muestras de las 150).
| Pureza del oro | Precio del oro | |
|---|---|---|
| Muestra 1 | 0.3745 | 1028.1347 |
| Muestra 2 | 0.9507 | 1456.2091 |
| Muestra 3 | 0.7320 | 1260.2042 |
| Muestra 4 | 0.5987 | 1145.5583 |
| Muestra 5 | 0.1560 | 958.0828 |
Esta tabla constituye una base de datos de entrenamiento. Cada muestra está caracterizada por dos elementos: su pureza , que varía entre (no es oro) y (es oro puro), y su precio (que puede ir de a infinito).
La recopilación de estas muestras representa un momento crucial en la vida de este robot científico. Aquí hay dos aspectos esenciales que debe tener en cuenta para realizar estimaciones precisas.
Amplio rango de datos: Wall-E se da cuenta rápidamente de que para obtener estimaciones confiables, debe tener un gran número de muestras en su base de datos.
De hecho, si solo se consideran dos muestras, como se ilustra aquí, es imposible determinar si el comportamiento de los precios es lineal o no. Muchas curvas de estimación podrían pasar por estos dos puntos sin reflejar la realidad. Como las dos curvas a continuación, por ejemplo.
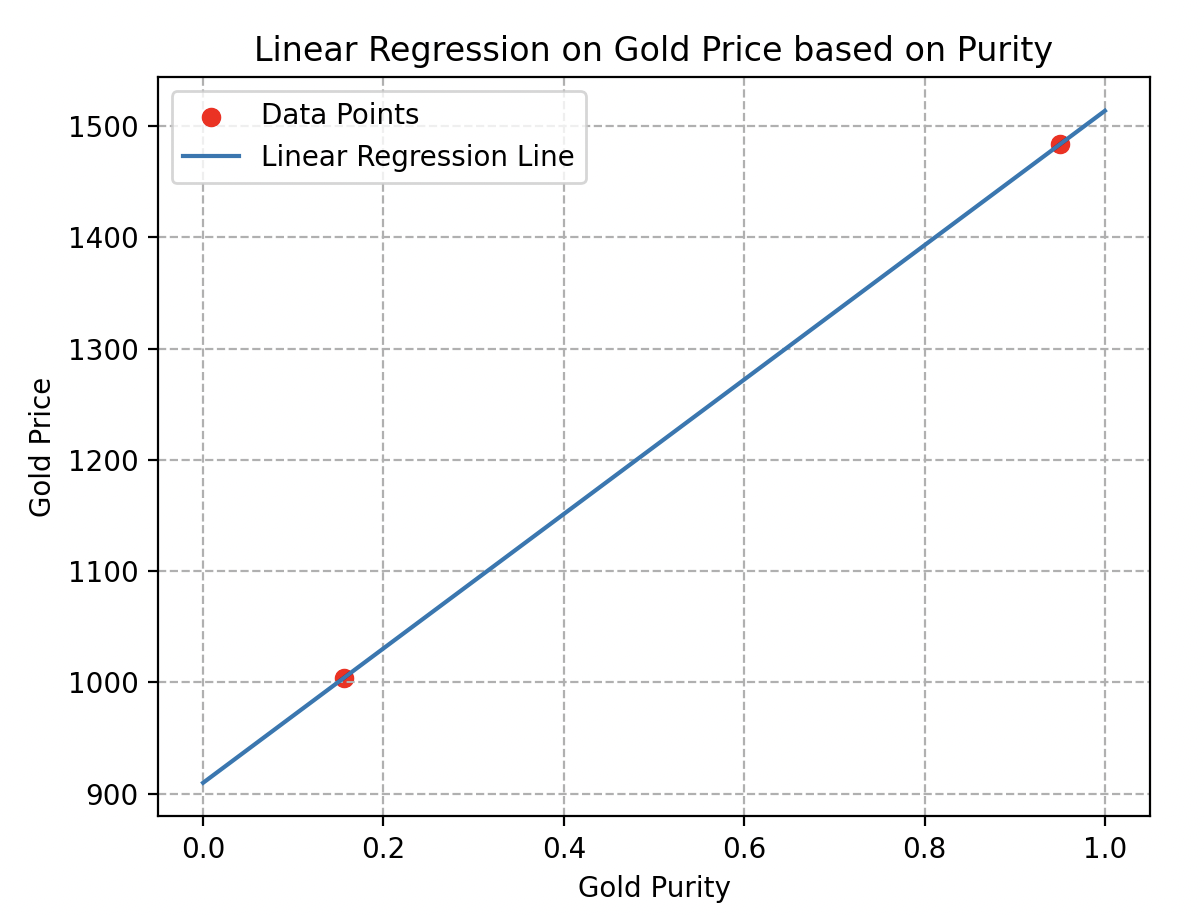

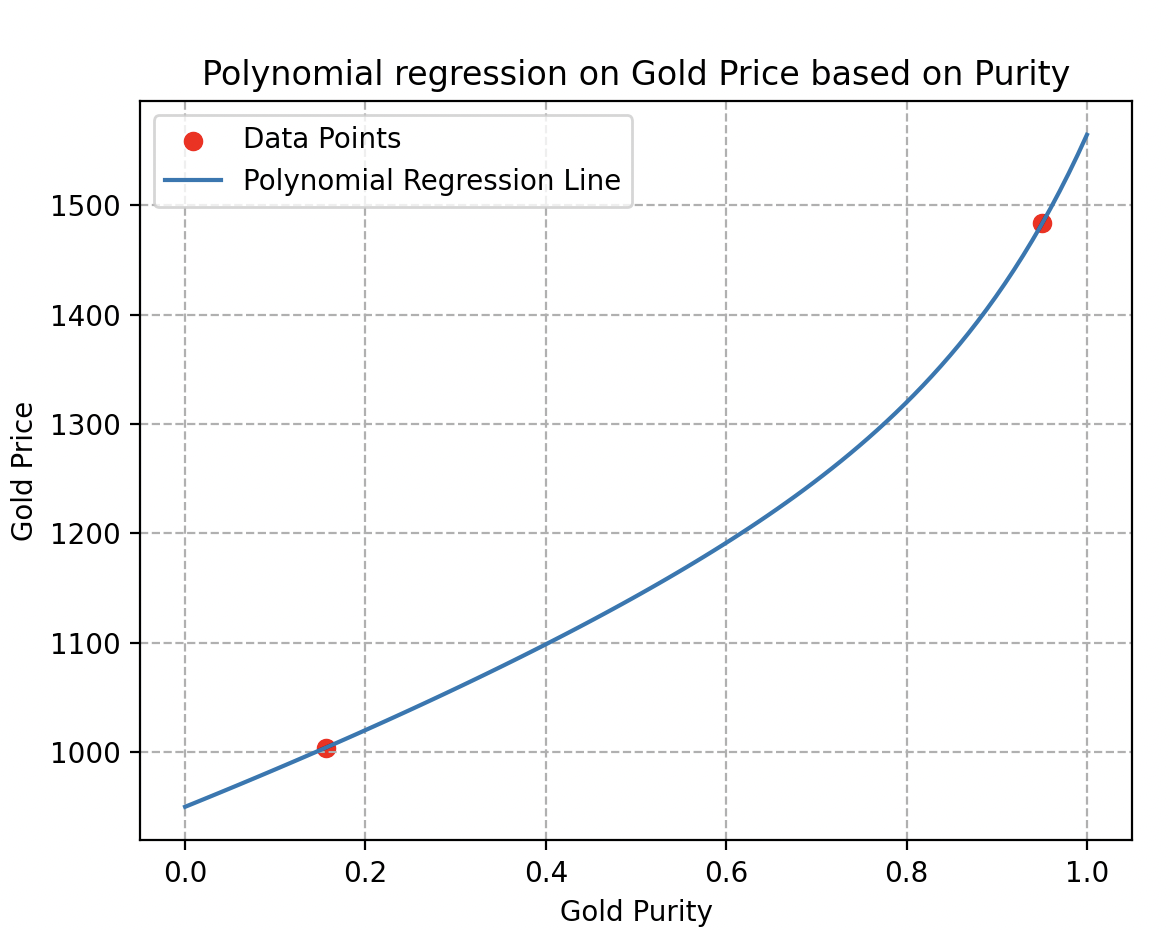
Diversidad de datos: otro detalle crucial a tener en cuenta durante la recolección es la variedad de datos.
Supongamos que Wall-E solo tiene en cuenta muestras puras o muestras con pureza extremadamente cercana (ver la figura adjunta). En esta situación, todas las muestras tendrán casi el mismo precio, lo que le impediría estimar el precio de otras aleaciones de oro.
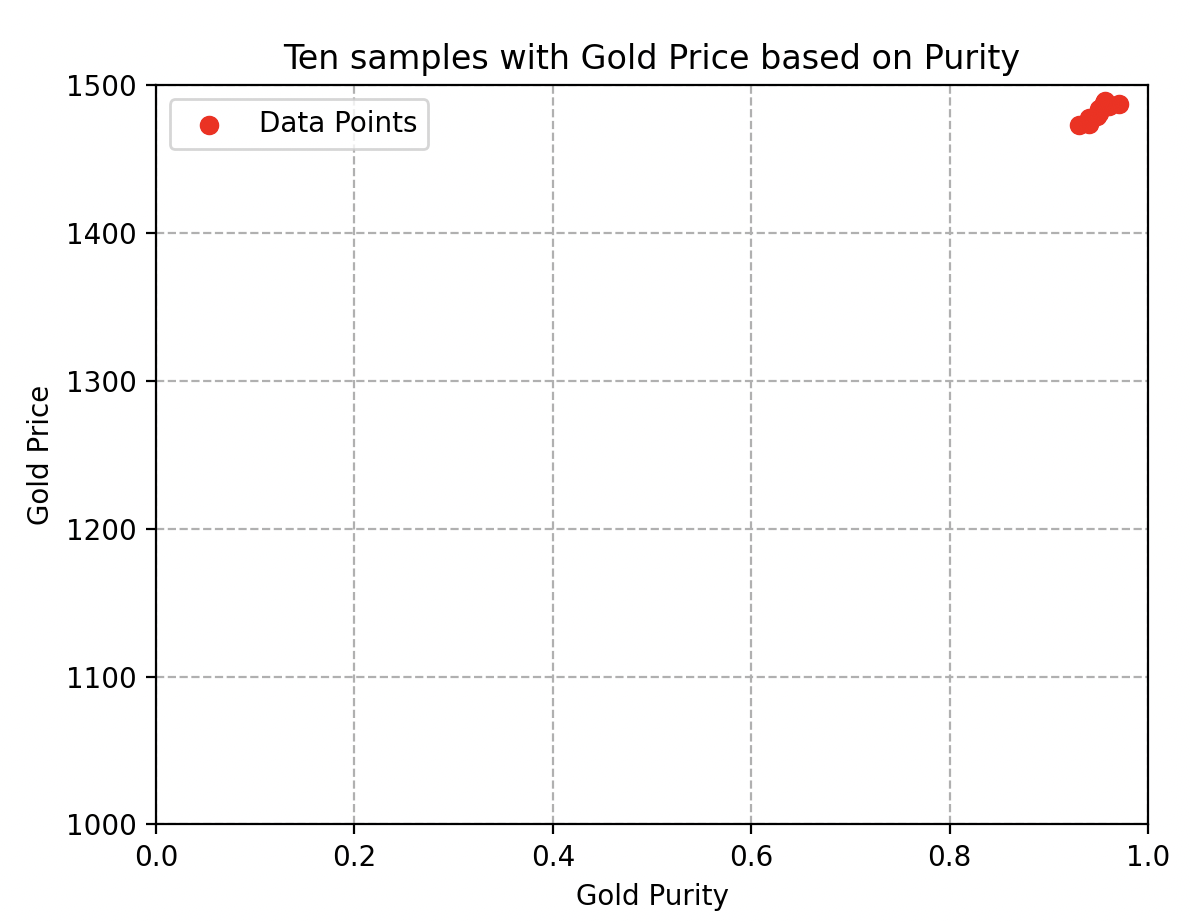
Representación del precio del oro en función de su pureza para muestras demasiado similares
Conclusión de la recolección: es imperativo reunir una multitud de muestras seleccionadas al azar para evitar estas limitaciones y garantizar la obtención de estimaciones precisas para una amplia variedad de aleaciones de oro.
Creación del Modelo Lineal
A partir de estos datos, Wall-E elabora lo que hemos llamado un modelo lineal , donde y son los parámetros del modelo. Un modelo eficiente minimiza las discrepancias entre las predicciones de Wall-E y los valores reales de las muestras. Como una especie de buscador de oro moderno, Wall-E ajusta estos parámetros para alinear mejor sus estimaciones con la realidad, creando así una ecuación que vincula sutilmente la pureza y el valor del oro. Aquí está su intento inicial, que no es asombroso en absoluto.

Medir los Tesoros de Oro: la Función de Coste
La siguiente etapa en el aprendizaje de Wall-E implica evaluar el rendimiento de este modelo, es decir, medir los errores entre sus predicciones y los valores en el conjunto de datos.
Para el pequeño robot, el procedimiento es simple: cada estimación, denotada como , en el conjunto de datos se enfrenta a la realidad. Según el enfoque elegido, el programa de Wall-E devuelve el error correspondiente a cada predicción que llamaremos .
Cada una de las estimaciones de Wall-E está así asociada con su propio margen de error. Con el tiempo, estos errores se acumulan hasta alcanzar el número total de ejemplos en el conjunto de datos.
Entonces, se reúnen todos estos errores en una función que llamamos función de coste, denotada como . Es una función que depende de los parámetros a ajustar y simplemente calcula el promedio de todos los errores. Se escribe de la siguiente manera:
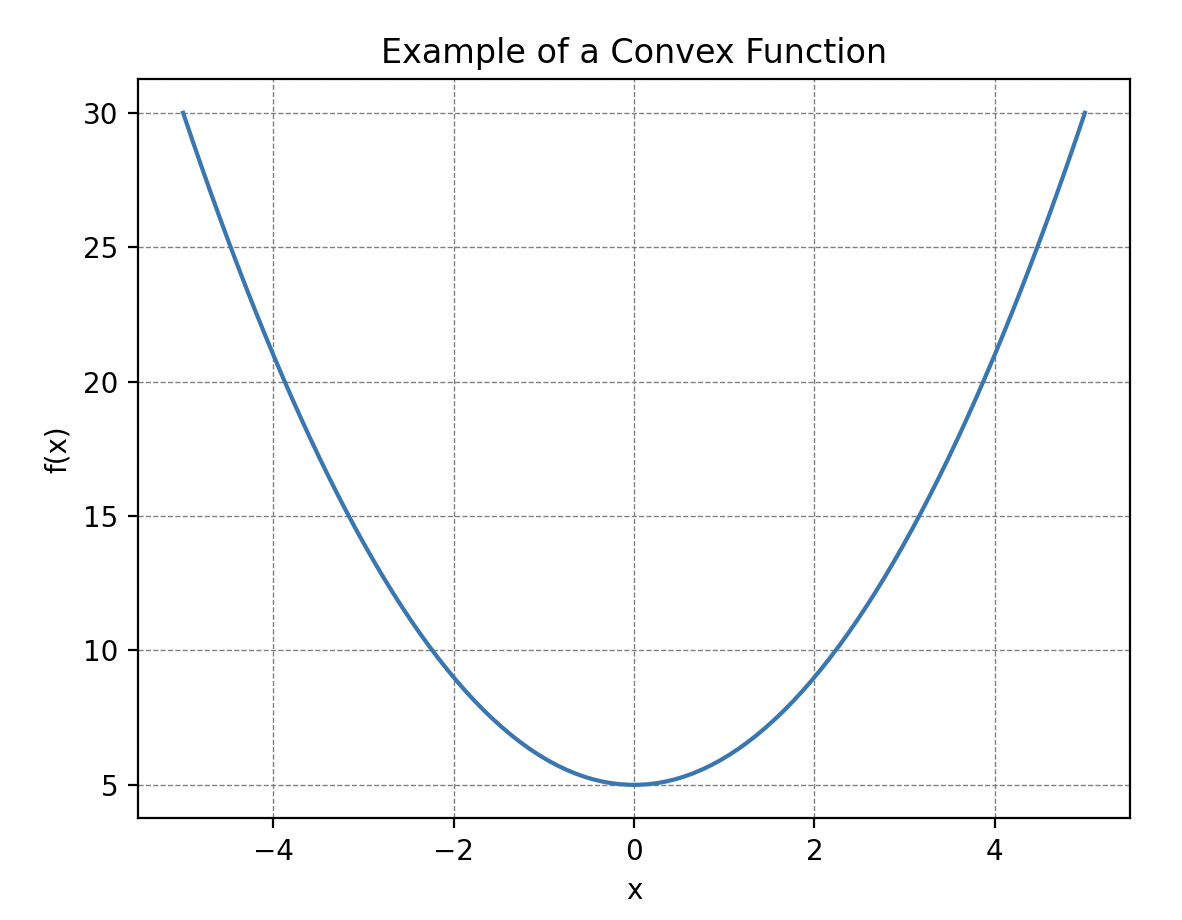
Una propiedad importante a tener en cuenta sobre esta función es su convexidad, es decir, que su curva “mira hacia arriba en todas partes”. Más específicamente, esto significa que si trazamos una línea entre dos puntos de la curva, esta siempre estará por encima o al nivel de la curva. ¡Tales curvas siempre tienen un mínimo global! Esto es lo que nos será útil más adelante.

Sin embargo, ¿qué es el error? ¿Cómo se puede definir? Antes de abordar estas preguntas, es crucial hablar sobre un concepto matemático: la distancia, que permite cuantificar la separación entre dos puntos dados.
Las Distancias Explicadas por Hal
Wall-E, en pleno momento de reflexión, buscaba entender por qué debía prestar atención al concepto de distancia. La perplejidad lo invadía mientras observaba a Hal, su leal compañero cucaracha, deslizarse sigilosamente entre los rincones del laboratorio.
¿Qué significado podría tener esta exploración minuciosa y metódica del espacio por parte de Hal?

Créditos: Disney/PIXAR
Estaba muy lejos de imaginar que detrás de estos movimientos silenciosos y discretos, Hal compartía, a su manera, las sutilezas de las distancias. Cada movimiento entre los objetos de la habitación ilustraba una regla matemática esencial. Eran cuatro en total.
La Positividad. En esta coreografía, Hal demostraba la primera regla: la positividad de las distancias. Explicando a su manera que la distancia entre su escondite favorito y la despensa de basura siempre era positiva, un hecho simplemente ilustrado por su trayectoria (una longitud no es negativa).
Wall-E, como buen científico, lo expresó en términos matemáticos: la distancia entre dos puntos cualesquiera y debe ser positiva o nula. Esto se escribe,
El símbolo significa “para todo” y significa “en”. Se lee: para todos los elementos arbitrarios y (aquí estamos hablando de puntos) en , la distancia entre y es positiva o nula.
La Simetría. El concepto de simetría fue luego destacado por Hal, demostrando cómo sus movimientos del punto al punto siempre eran idénticos, ya fuera de a o de a . Sus sutiles idas y venidas marcaban la idea de simetría en esta danza entre puntos.
El pequeño robot introdujo esta idea en sus circuitos: la distancia entre y debe ser la misma que entre y . Matemáticamente,
La Separación. Sin embargo, la demostración más sorprendente para Wall-E fue la de la separación. Hal fue a buscar dos semillas que colocó en dos lugares diferentes de la habitación. Luego comenzó una danza frenética, dejando una semilla fija y trayendo la otra hacia ella mediante una serie de rápidos movimientos hacia adelante y hacia atrás hasta finalmente pegar las dos semillas juntas.
De esta manera, quería ilustrarle a Wall-E que si la distancia entre estos dos puntos era nula entonces los dos puntos coinciden. Una representación impresionante y clara de la regla de separación.
Comprendió la lección, que tradujo a su propio lenguaje: si la distancia entre y es nula, entonces y coinciden.
El símbolo significa “implica”.
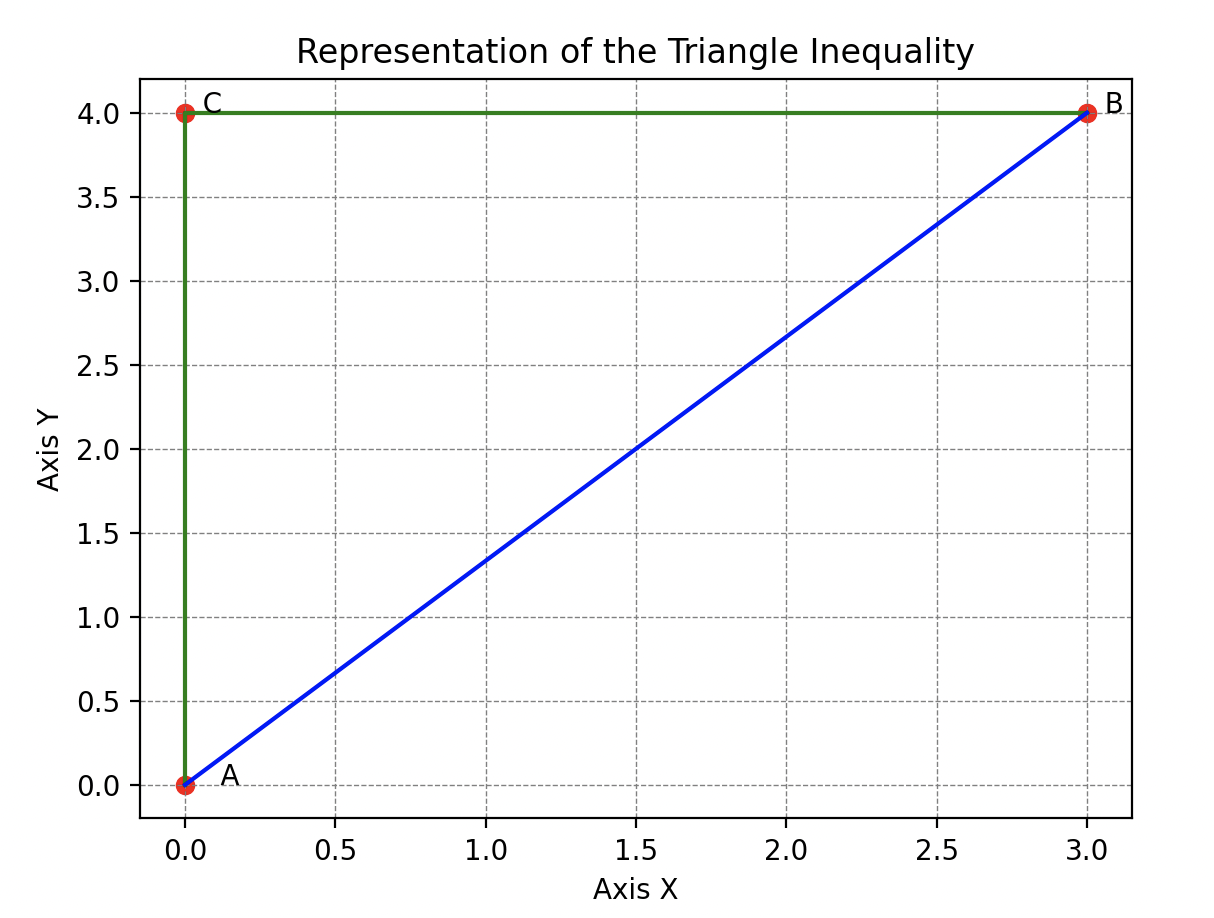
La Desigualdad Triangular. Sin embargo, la lección de Hal no se detuvo ahí porque aún quedaba otra regla esencial por analizar. Continuó su exploración ilustrando la desigualdad triangular.
Moviéndose entre su escondite, Wall-E y la despensa, Hal mostraba que la distancia entre su escondite y Wall-E es siempre menor que la distancia entre su escondite y la despensa más la distancia entre la despensa y Wall-E. Este truco ingenioso, enseñando que el camino más corto entre dos puntos es una línea recta, cautivó a Wall-E.
Se apresuró a transcribirlo todo: si tomo tres puntos , y que no coinciden, entonces la distancia entre y siempre es menor o igual a la distancia entre y más la distancia entre y .

Gracias a Hal, Wall-E asimiló que formalmente, una distancia es una función que compara dos puntos en un espacio dado al asignar un número real no negativo, expresando la “longitud” entre estos dos puntos, y sigue reglas específicas. Este espacio puede ser el plano familiar de dos dimensiones como demostró la cucaracha, o nuestro espacio tridimensional, o incluso espacios mucho más exóticos.
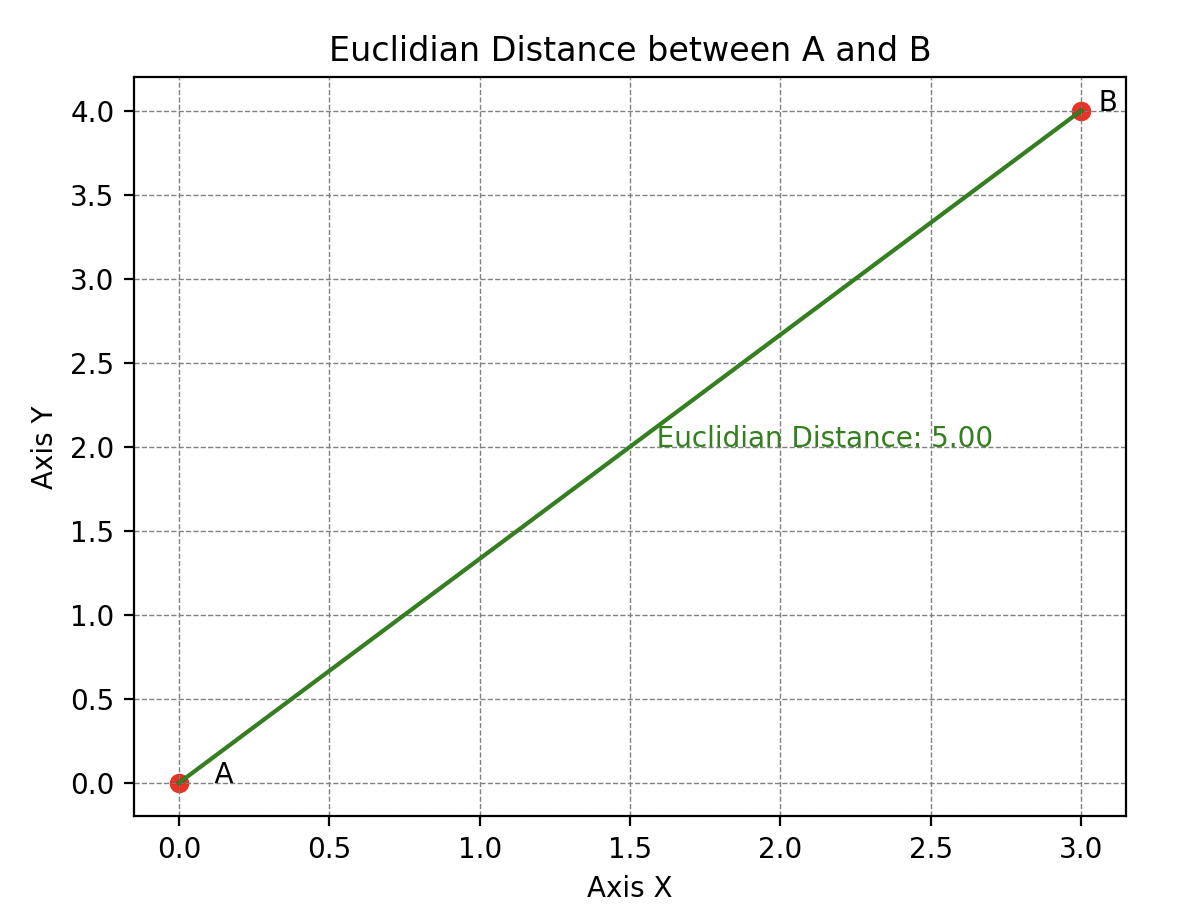
Sus habilidades de abstracción también le permiten comprender que existen diferentes tipos de distancias, entre las cuales la más conocida es la distancia euclidiana (también llamada 2-distancia).
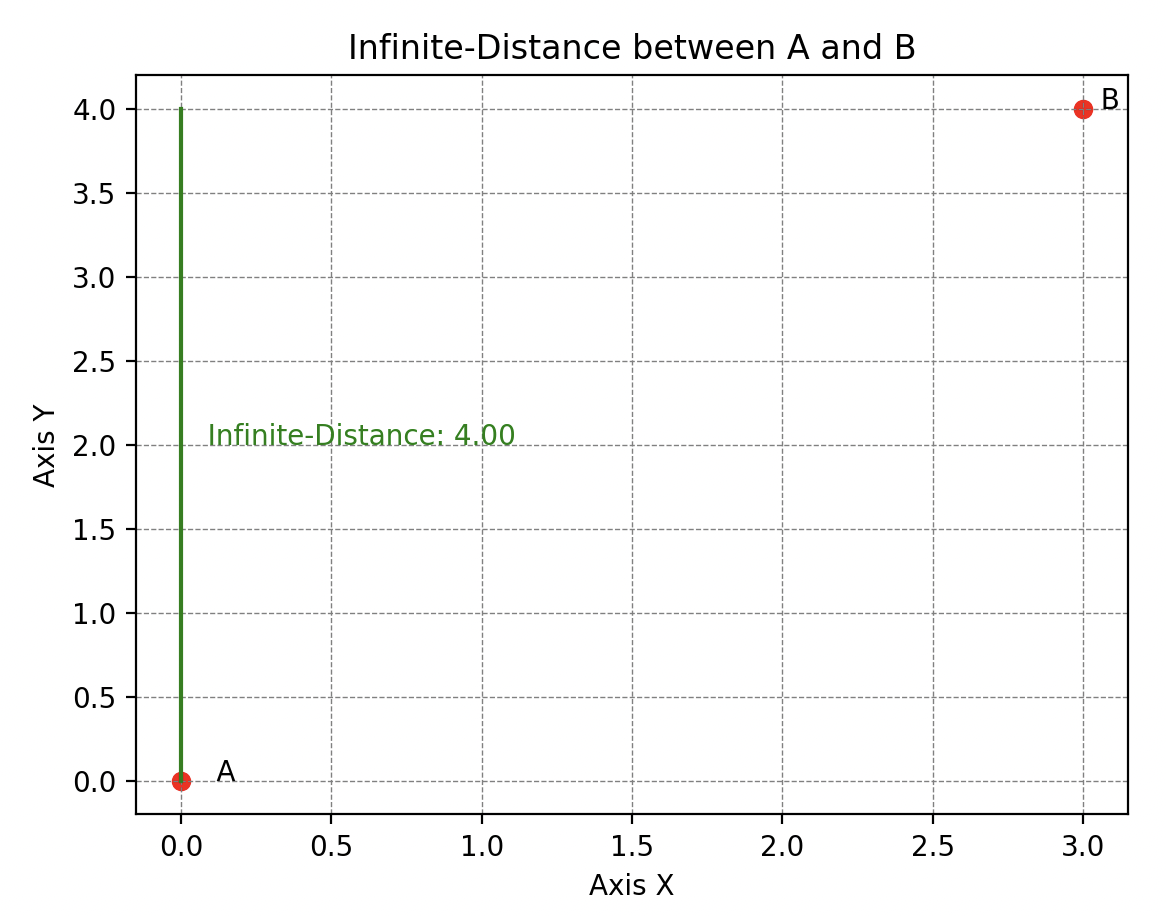
También está la -distancia (o distancia infinita), que evalúa la distancia máxima entre estos puntos a lo largo de cualquier dimensión. Pero también encontramos la distancia de Manhattan (o 1-distancia para los puristas), llamada así porque refleja la distancia que un taxi tendría que recorrer en una red de calles que forman cuadrículas ortogonales (típica del trazado de calles en Manhattan, de ahí el nombre).
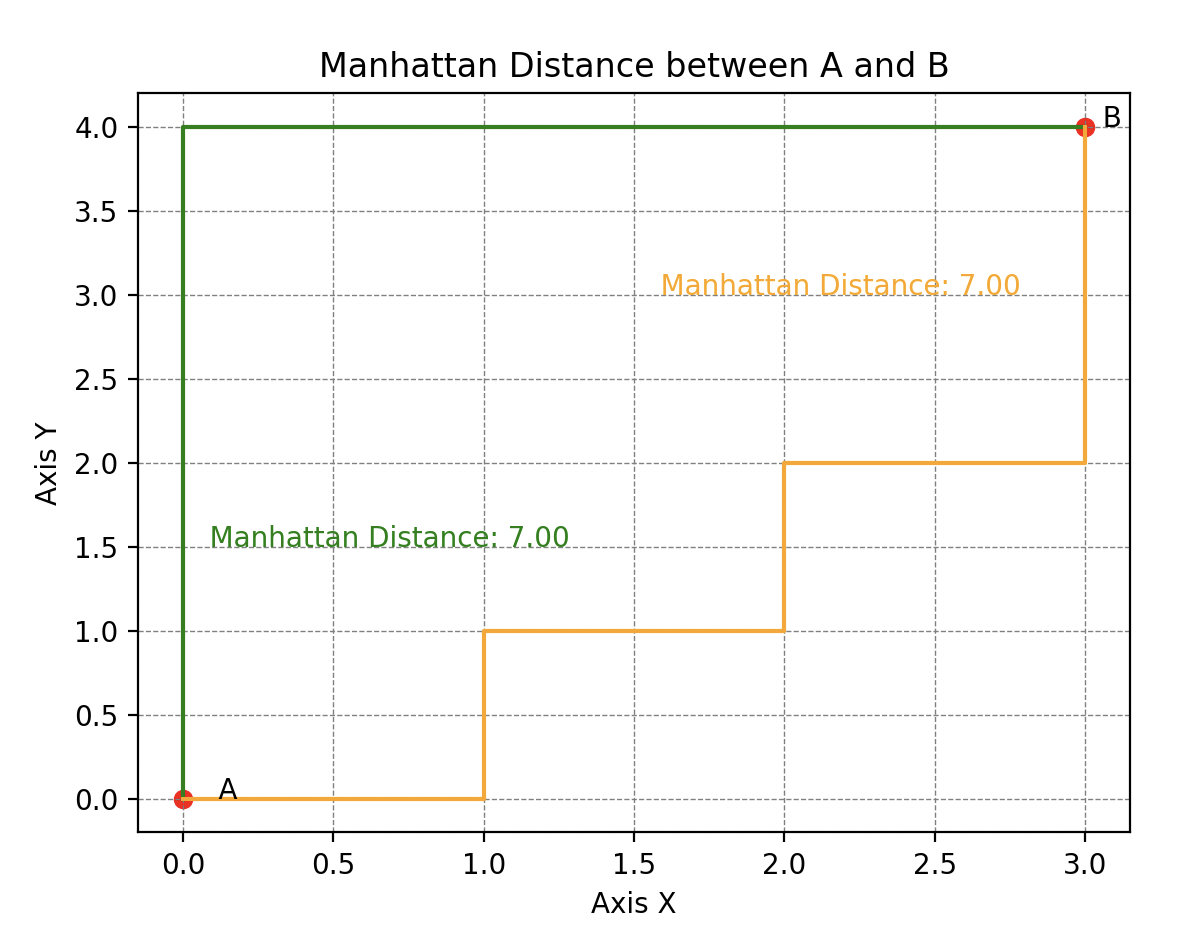
Cálculo de la distancia de Manhattan entre el punto A y el punto B
Exploraremos estas particularidades en detalle en un próximo artículo.
Un Error Fatal
Ahora, ¿por qué abordar el concepto de distancia en el contexto de la evaluación de las predicciones de Wall-E? De hecho, esto nos lleva a reflexionar sobre lo que realmente representan los errores entre las predicciones y los valores reales del conjunto de datos.
Imaginen que Wall-E evalúa la primera muestra, una aleación de oro de un kilo con una pureza de y un precio real de pernos, pero predice pernos. Observan una diferencia de pernos. Aquí obtenemos un valor negativo, pero tomando otro ejemplo podría ser positivo. Esta dualidad entre valores positivos y negativos no es práctica.
Para resolver este problema, dos opciones están disponibles para nosotros:
-
Error absoluto. Considerar el valor absoluto de cada diferencia (eliminamos el signo menos cuando está presente). El error obtenido se llama el error absoluto, denotado (Absolute Error en inglés). En el ejemplo anterior, tendríamos .
-
Error cuadrático. Calcular el cuadrado de cada diferencia. Este error se llama el error cuadrático, denotado (Squared Error). Aquí tendríamos .
Notamos que la segunda opción amplifica considerablemente los errores, pero veremos cómo equilibrar estas diferencias más adelante.
Así, al aplicar cualquiera de estas opciones, elegimos cómo queremos medir los errores, es decir, una distancia. La -distancia para la primera o la distancia euclidiana para la segunda.
Ahora, el procedimiento es simple: cada estimación, denotada por , en el conjunto de datos se compara con la realidad. Según el enfoque elegido, el programa de Wall-E devuelve el error correspondiente. Además, según la distancia elegida, la función de coste se nombra de manera diferente:
- Si consideramos el enfoque de errores absolutos, se llama el Error Absoluto Medio, denotado MAE (Mean Absolute Error en inglés), y se escribe:
- El enfoque de errores cuadráticos nos proporciona una función de coste llamada Error Cuadrático Medio, denotada MSE (Mean Squared Error en inglés), y se escribe:
Para reescalar a la escala original nuestros errores calculados por esta función, simplemente tomamos su raíz cuadrada. La función obtenida de esta manera se llama la Raíz del Error Cuadrático Medio, denotada RMSE (Root Mean Squared Error).
Aquí hay un ejemplo para ilustrar el cálculo donde Wall-E estima el valor de solo cinco muestras (con cinco diferencias).
| Diferencias | -100 | 7 | -2 | 42 | 13 |
|---|---|---|---|---|---|
| Errores AE | 100 | 7 | 2 | 42 | 13 |
| Errores SE | 10 000 | 49 | 4 | 1764 | 169 |
Cálculo de la MAE
Cálculo de la RMSE
¿Por qué elegir uno u otro? Para responder a esta pregunta, presentemos a Eve.

Créditos: Disney/PIXAR
Además de su capacidad para distinguir objetos orgánicos, posee un sofisticado sistema de autodefensa. Ha sido entrenada para estimar la distancia (en centímetros) entre el impacto de sus disparos y el centro del objetivo. Eve entrena dos modelos para encontrar el que minimizará los errores.
| Error 1 | Error 2 | Error 3 | Error 4 | MAE | |
|---|---|---|---|---|---|
| Modelo 1 | 20 | 0 | 0 | 0 | 5 |
| Modelo 2 | 6 | 5 | 6 | 4 | 5.25 |
| Error 1 | Error 2 | Error 3 | Error 4 | RMSE | |
|---|---|---|---|---|---|
| Modelo 1 | 20 | 0 | 0 | 0 | 10 |
| Modelo 2 | 6 | 5 | 6 | 4 | 5.31 |
Aquí observamos que la MAE del modelo 1 es menor que la del modelo 2, por lo que Eve elegirá el modelo 1 para estimar sus disparos. Sin embargo, en el primer modelo, podemos ver que Eve casi no comete errores excepto en su primer disparo donde se equivoca por 20 cm. Esta es una cantidad no despreciable y peligrosa, ya que podría dañar a alguien si su arsenal no es lo suficientemente preciso.
En la segunda tabla, es completamente diferente: observamos que la RMSE del modelo 1 es mucho peor que la del modelo 2, ya que muestra un error mucho más grande. Eve tendería a elegir el modelo 2 en este caso. De hecho, RMSE penaliza mucho más los errores grandes que MAE.
Si Eve favorece el Error Absoluto Medio (MAE), significa que quiere minimizar las diferencias absolutas entre el impacto de sus disparos y el objetivo. Esto sugiere que para Eve, cada diferencia tiene la misma importancia. Una diferencia de 20 unidades se considera veinte veces más importante que una diferencia de 1 unidad.
Por otro lado, si Eve elige favorecer la Raíz del Error Cuadrático Medio (RMSE), significa que quiere enfatizar las diferencias grandes. En este caso, los errores más significativos tienen un peso más significativo. De hecho, una diferencia de 20 unidades es 400 veces más importante que una diferencia de una unidad. Por lo tanto, si Eve quiere eliminar disparos con diferencias muy grandes, el modelo basado en RMSE sería más adecuado.
Estas elecciones de funciones de coste dependen de los objetivos de Eve: si quiere reducir las diferencias grandes, favorecerá el MSE. Por otro lado, si quiere una evaluación equilibrada de todas las diferencias, optará por el MAE. También existen otras formas de medir errores, pero no hablaremos de ellas aquí.
Un Pequeño Paso para el Robot, un Gran Paso para el Algoritmo
Lo que más le gusta a Wall-E es aprender por sí mismo qué parámetros minimizan la función de coste, es decir, los parámetros que nos dan el mejor modelo posible. Para encontrar estos parámetros óptimos, Wall-E usa un algoritmo de optimización bien conocido llamado descenso de gradiente. Imaginen este paso como si Wall-E estuviera ajustando meticulosamente las perillas de su modelo matemático para alcanzar el nivel de experiencia necesario en la tarea de predecir el precio del oro en función de su pureza.
¡Bajemos!
El concepto de descenso de gradiente es simple: imaginen a Wall-E perdido en las laderas de una montaña de basura en una densa niebla, reciclando lo que le queda por hacer. Desafortunadamente para él, sus baterías están desvaneciéndose peligrosamente y debe llegar a su pequeña nave espacial ubicada en el punto más bajo, pero solo puede ver las pendientes inmediatas a su alrededor. Así, en cada paso de longitud (la letra delta en griego), elige la dirección que lo hace descender lo más rápido posible. A medida que avanza, ajusta su dirección en función de las pendientes que percibe, acercándose progresivamente al punto más bajo.
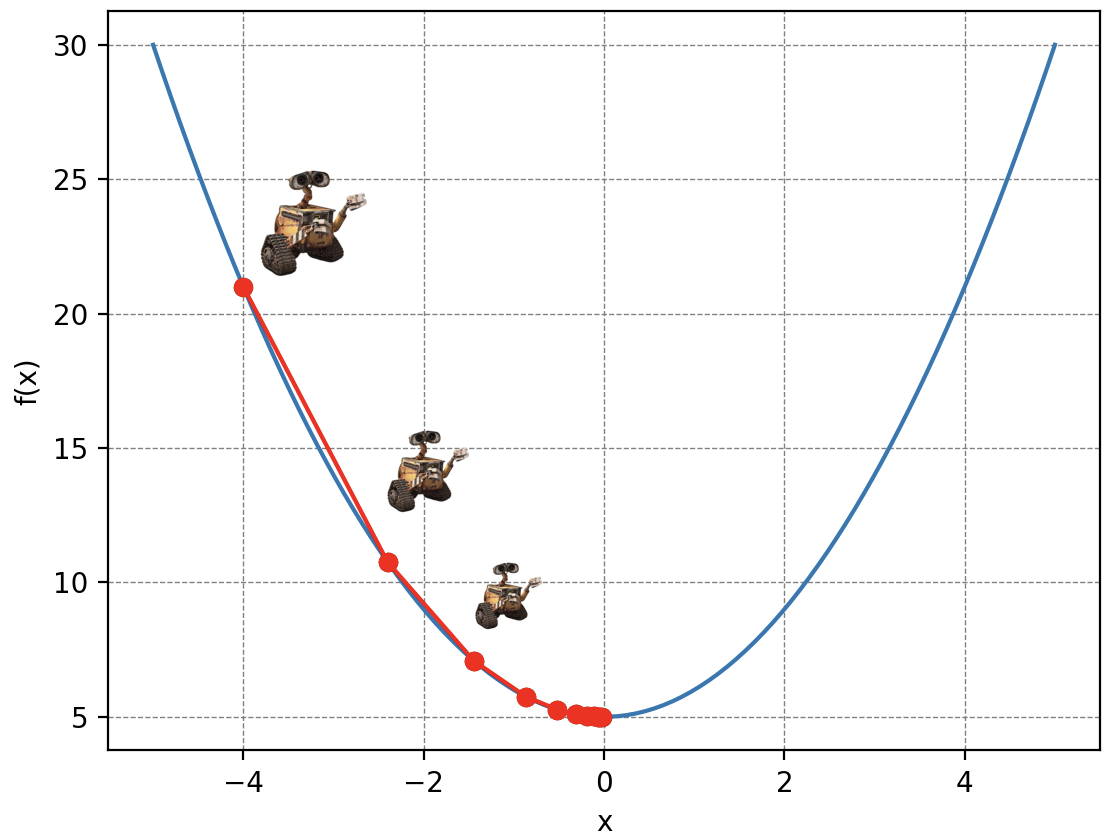

Por supuesto, la elección del valor es crucial en el descenso de gradiente. Porque imagínen que Wall-E se mueve con pasos demasiado pequeños: tardará demasiado en llegar al fondo. O si usa su jetpack para volar grandes distancias: corre el riesgo de pasar por encima de su refugio.
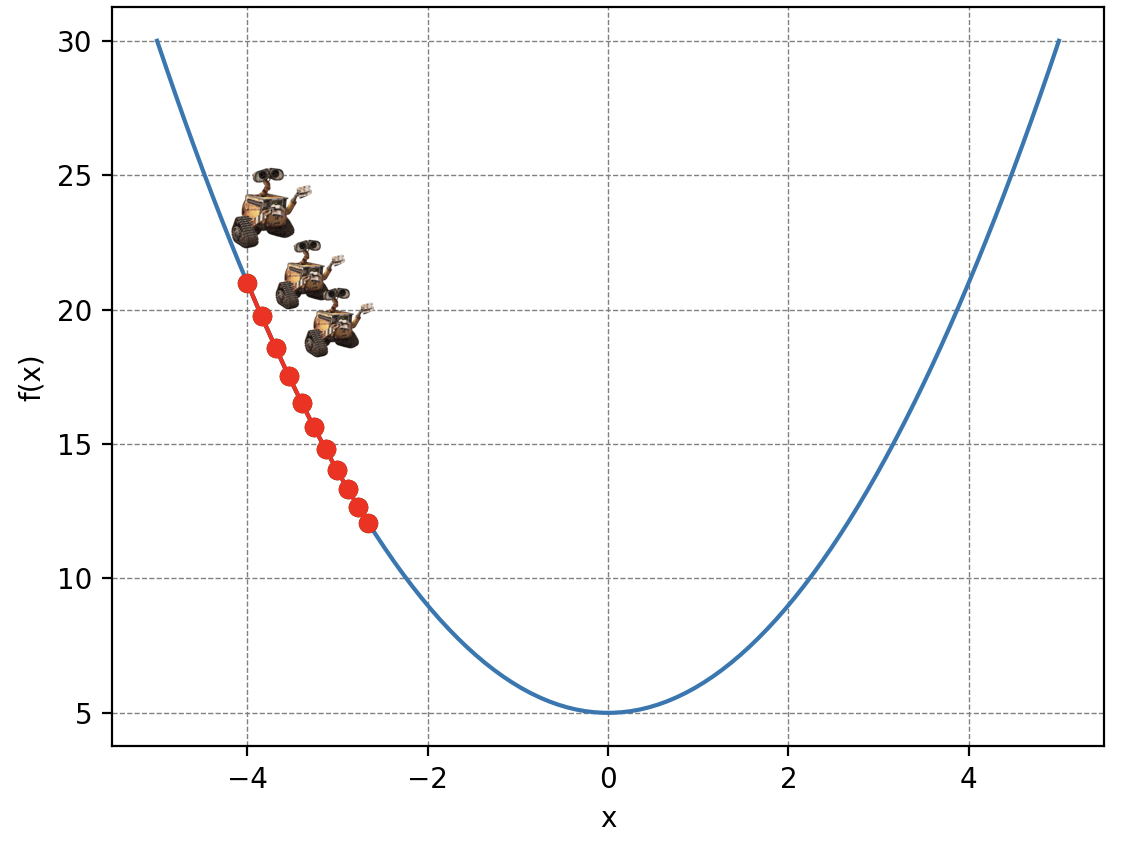
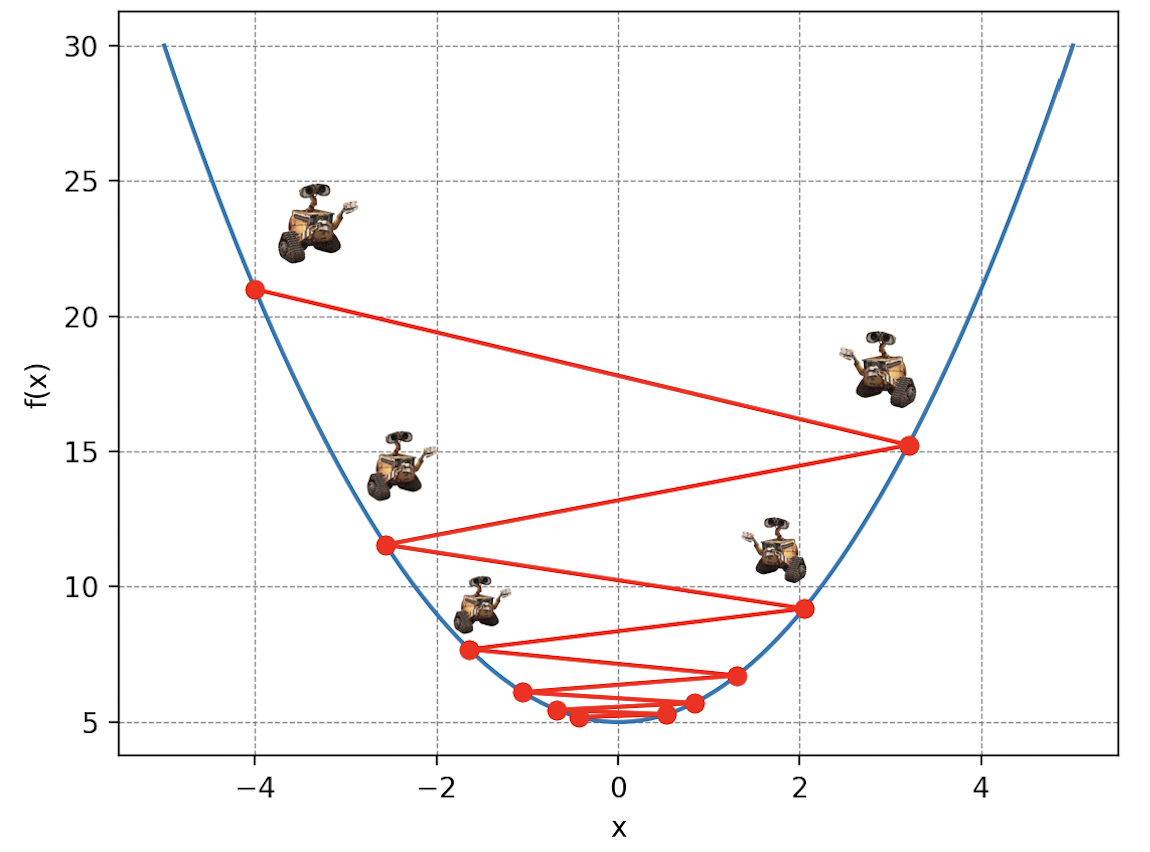
Volvamos a nuestro problema inicial. La montaña de basura simboliza nuestra función de coste, los parámetros de posición de Wall-E en la montaña representan los parámetros de nuestro modelo de regresión lineal y los pasos traducen lo que se llama la tasa de aprendizaje de Wall-E (Learning Rate en inglés). Así, descomponiendo las acciones de Wall-E algorítmicamente, tenemos:
- Nuestro robot calcula los gradientes, es decir, la pendiente a lo largo de los dos ejes ( y ) de la función de coste en cada iteración. Matemáticamente, esto implica calcular estas dos cantidades:
Los matemáticos lo habrán entendido bien; esto no es más que el cálculo de la derivada de una función con varias variables.
- Actualiza los parámetros, acercándolo cada vez más al mínimo de la función de coste. Los parámetros actualizados se denominan y y se escriben:
Así, los nuevos parámetros se definen simplemente como la posición anterior menos la tasa de aprendizaje multiplicada por el valor de la pendiente. Por analogía, es la posición de Wall-E después de dar un paso en la dirección donde la pendiente es más empinada.
- Reinicia hasta encontrar el mínimo de la función de coste.
Es importante entender que el descenso de gradiente es un proceso iterativo, lo que significa que se repite muchas veces hasta que Wall-E alcanza un punto donde la función de coste es mínima y sus predicciones son lo más precisas posible.
Con respecto a la tasa de aprendizaje, algunos detalles necesitan aclararse. Como en la metáfora anterior, la elección del valor de es crucial. Un demasiado pequeño podría ralentizar la convergencia, ya que los ajustes de los parámetros serían diminutos en cada paso, mientras que un demasiado grande podría provocar oscilaciones o incluso impedir la convergencia, ya que los ajustes podrían sobrepasar el mínimo deseado. Por lo tanto, elegir el valor de es crucial para que el algoritmo de Wall-E converja de manera eficiente hacia la solución óptima.
¿Cuándo Llegaremos?
Ha pasado un poco de tiempo ahora que nuestro valiente robot se mueve desesperadamente en la oscuridad, cegado por la madre naturaleza. Se pregunta cuándo llegará al fondo de la montaña. Al igual que en esta situación, en machine learning, alcanzar el mínimo de la función de coste — el equivalente del refugio para Wall-E — puede parecer complicado. Su posición es incierta, y para llegar allí, Wall-E debe ajustar su progreso, teniendo en cuenta la longitud de sus pasos y el número de estos pasos.
Para navegar, Wall-E debe registrar meticulosamente cada una de sus posiciones a lo largo de la pendiente de la montaña, lo que se llama la historia del descenso. Al mantener un registro preciso de cada paso, puede luego trazar su trayectoria, creando una “curva de descenso”. Esto le permite visualizar su camino, medir su progreso y determinar si está cerca del punto más bajo. A continuación se muestra un ejemplo, asumiendo que Wall-E está colocado al azar en la montaña.
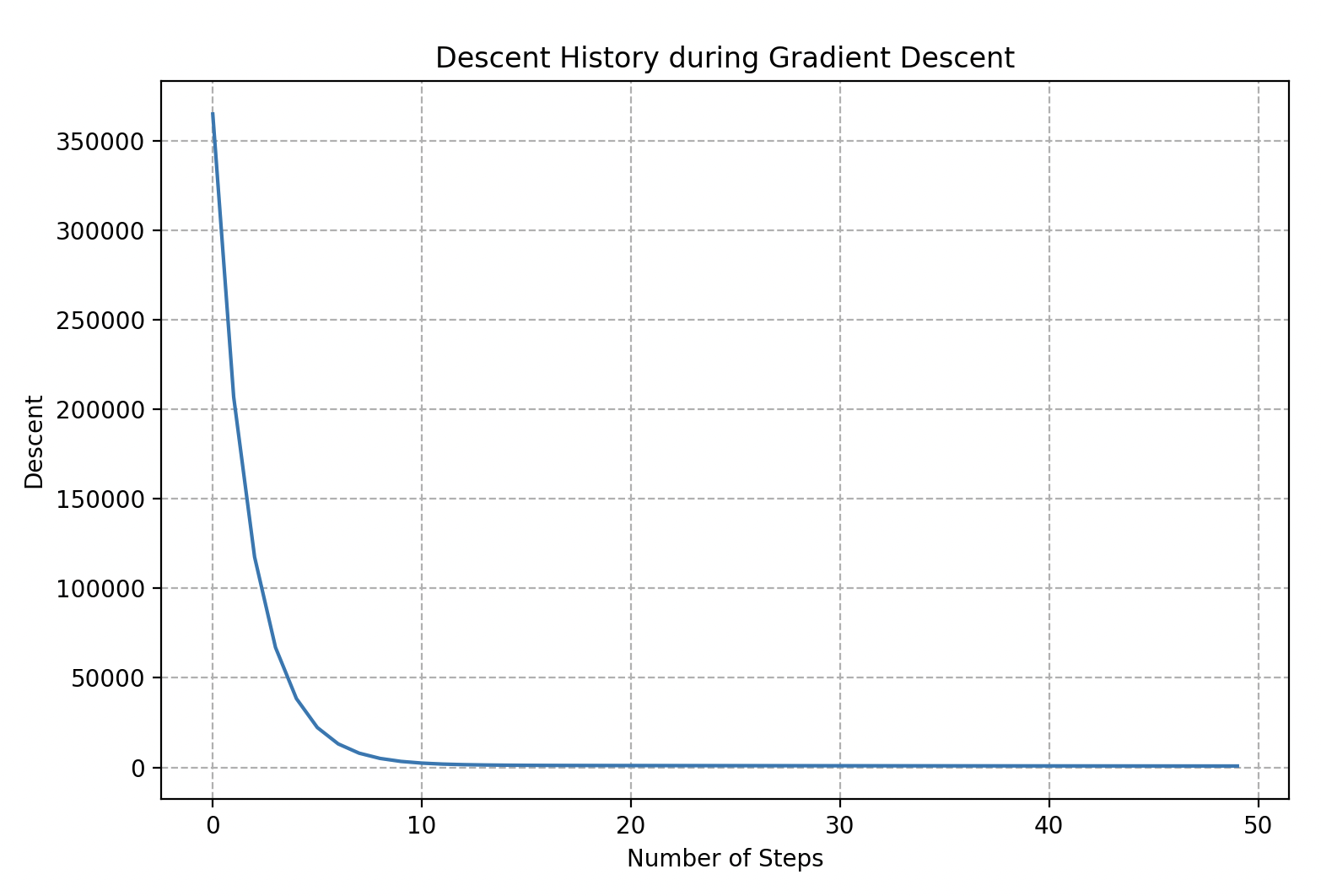

En el campo del machine learning, la historia del descenso se llama en realidad historia del coste ya que proporciona los valores de la función de coste basados en variables clave como la tasa de aprendizaje y el número de iteraciones del algoritmo de descenso de gradiente.
Además, su representación gráfica, denominada curva de descenso, en realidad se llama curva de aprendizaje. Es esencial para evaluar el rendimiento de un modelo porque ilustra dinámicamente la evolución de la precisión del modelo.
En este caso particular, después de unos diez pasos, Wall-E parece dejar de descender más, lo que indica que ha alcanzado su refugio. Los 40 pasos adicionales son por lo tanto innecesarios. Esta información es crucial en informática, ya que nos permite evitar ejecutar el algoritmo innecesariamente, lo que potencialmente ahorra tiempo y recursos, especialmente cuando ciertas simulaciones pueden tomar tiempos considerables, que van desde días hasta semanas.
En sus Circuitos Impresos: la Estimación del Precio del Oro
¿Pero qué sucede exactamente en el cerebro electrónico de nuestro adorable robot? Antes de realizar cualquier suma, Wall-E traduce no solo todo el conjunto de datos en una tabla, sino también los parámetros del modelo y los gradientes: una especie de lenguaje cifrado para máquinas conocido como forma matricial que simplifica enormemente los cálculos. Más precisamente, esto da lugar a un vector compuesto por elementos correspondientes a los precios de las muestras de oro,
acompañado de una matriz con filas y columnas que encapsula con precisión cada una de las características (en este caso, hay solo una, ) y una columna que contiene solo s, que llamaremos el “sesgo”:
Esta última columna simplemente nos permite realizar los cálculos matriciales necesarios para el aprendizaje. Vale la pena señalar que, en general, tenemos:
Simultáneamente, un vector de parámetros (una columna) hace su entrada, reuniendo cuidadosamente todos los parámetros de nuestro modelo, es decir, y :
No olviden que estamos buscando tal que minimice la función de coste. Gracias a esto, Wall-E puede expresar todos los pasos de aprendizaje fácilmente y estimar el precio de una pepita de oro con un valor desconocido:
-
La Cosecha se realiza mostrando los datos en una matriz: cada muestra, con sus características de pureza y precio, encuentra su lugar en esta matriz.
-
La Creación del Modelo es el proceso donde Wall-E define los parámetros mostrados en la columna tomada al azar, que se utilizan para establecer la relación lineal entre la pureza y el precio del oro: .
-
La Función de Coste se redefine de la siguiente manera:
donde denota el producto escalar (hablaremos del producto escalar en otro artículo).
- Encontrar el Mínimo implica calcular el gradiente:
y aplicar iterativamente el descenso de gradiente para actualizar el parámetro :
donde es el nuevo parámetro.
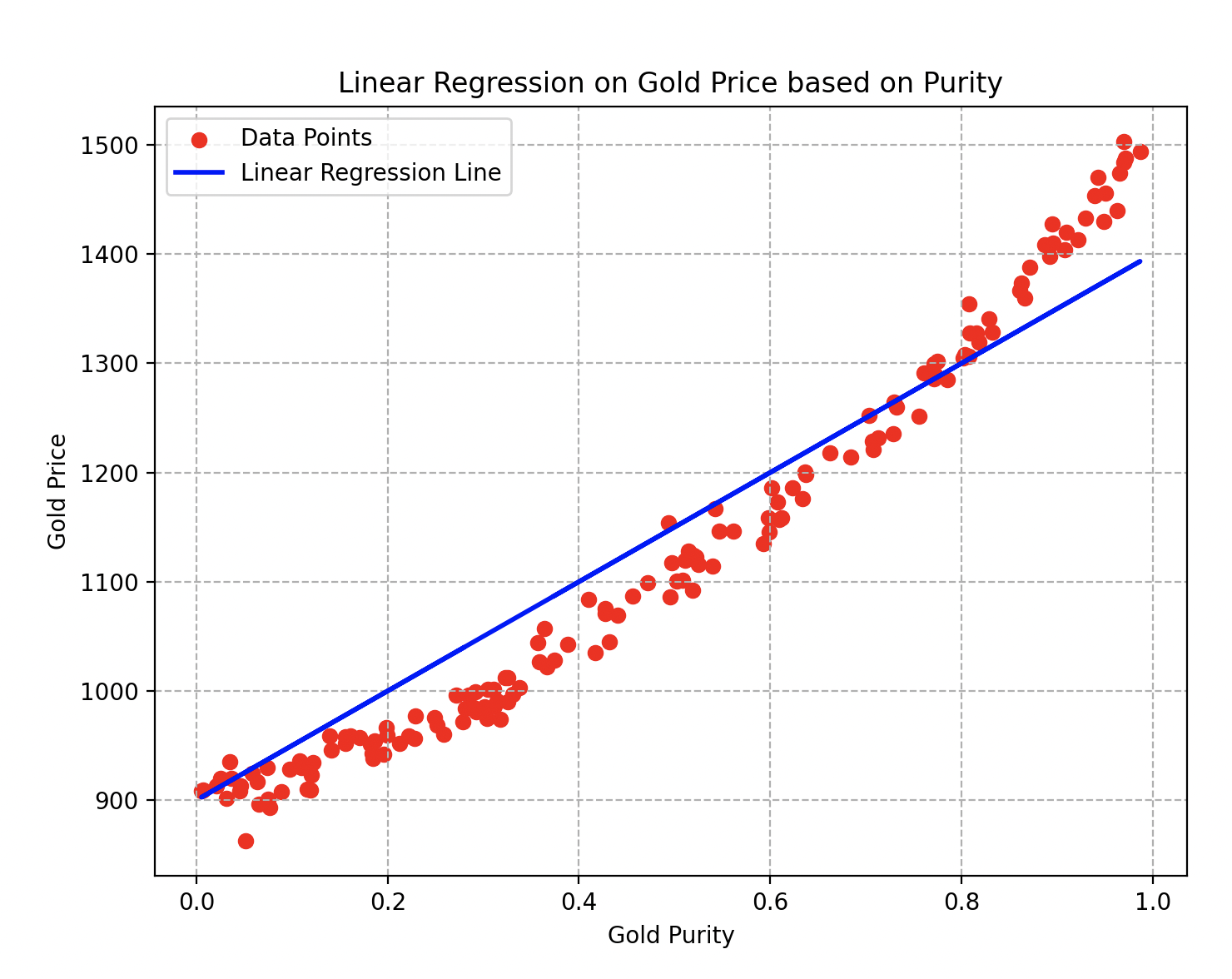
Wall-E, al aplicar cuidadosamente todos los pasos, ¡ahora está listo para estimar el precio del oro según la pureza que le proporcionen! Aquí está la curva final que obtiene.
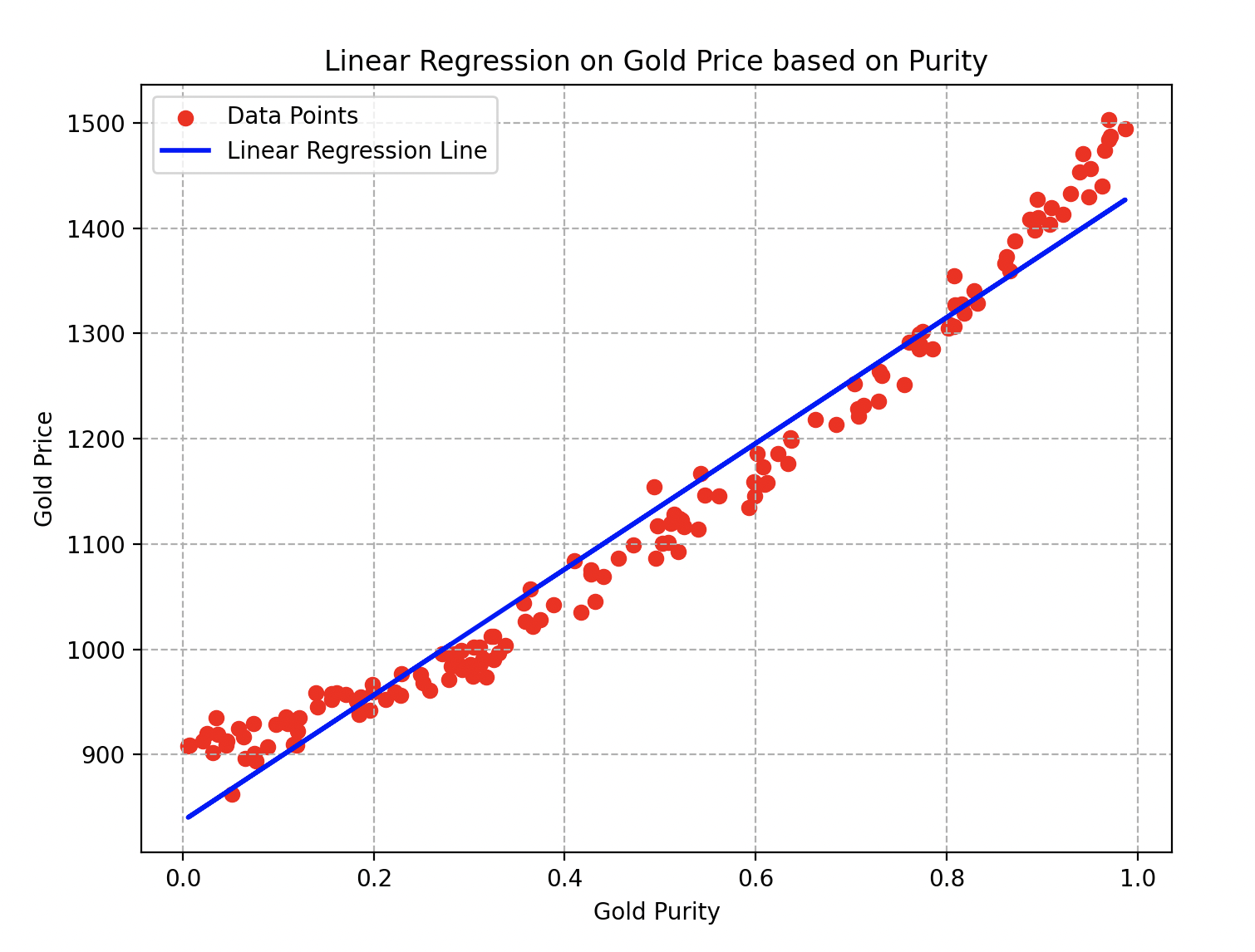
Curva de regresión lineal sobre el precio del oro en función de su pureza
Los parámetros y de la línea azul son respectivamente iguales a y . Para el descenso de gradiente, utilizó una tasa de aprendizaje de y realizó alrededor de veinte iteraciones del algoritmo.
Se puede observar fácilmente que al elegir una aleación de oro con una pureza de , su precio estimado sería de alrededor de pernos.
Transferencia de Conocimientos y Rendimiento del Modelo: Lecciones Aplicables a Todas las Regresiones
¡Todos los pasos y cálculos realizados para estimar el precio del oro en función de su pureza a través de la regresión lineal son fundamentalmente similares a los realizados para la regresión no lineal u otros tipos de modelos de machine learning!
Wall-E, el pequeño robot apasionado por estimar el precio del oro, sigue una secuencia bien definida para entrenar su modelo, minimizar el error y ajustar los parámetros para predecir el precio del oro en función de su pureza. El proceso implica transformar los datos en matrices, crear el modelo, definir la función de coste para evaluar los errores, minimizar esta función ajustando iterativamente los parámetros y, finalmente, obtener el parámetro óptimo para estimar con precisión el precio del oro.
Este proceso es flexible y puede aplicarse a diferentes situaciones y tipos de modelos de aprendizaje, adaptándose así a problemas más complejos que requieren modelos más sofisticados. El éxito de Wall-E en la estimación del precio del oro demuestra el poder y la eficiencia de estos métodos, abriendo el camino a aplicaciones más amplias y diversas del machine learning en diversos contextos.
Pero todavía hay una última cosa por considerar: el Coeficiente de Determinación, también conocido como . Juega un papel crucial en la evaluación del rendimiento del modelo de Wall-E, ya que mide qué tan bien se ajusta el modelo a los datos en comparación con las variaciones en ellos. En términos matemáticos, se escribe de la siguiente manera:
donde no es más que el promedio de los valores de nuestras muestras (en nuestro caso, es simplemente el precio promedio). A pesar de su apariencia aparentemente compleja, esconde una fracción simple de entender. Reescribiéndola en una forma más digerible, tenemos:
Recuerden (ver el artículo “Derrota al Maestro del Juego”) que la varianza es una medida de la dispersión de los valores de las muestras.
Así, para Wall-E, obtener un cercano a sería ideal, lo que implica que la fracción de la derecha está cerca de . Esto significa que los errores son en gran parte despreciables en comparación con cómo se dispersan los datos, y el modelo propuesto por Wall-E se ajusta bien a los valores de las muestras.
Por el contrario, si está cerca de , indicaría que el modelo no explica bien la variabilidad de los datos, y las predicciones pueden ser menos confiables porque los errores son del mismo orden de magnitud que la varianza.
Con todas estas explicaciones, Wall-E se embarcó en el cálculo del coeficiente de determinación para evaluar la calidad de su modelo anterior. El resultado es bastante gratificante, con una puntuación encomiable de . En otras palabras, el modelo se ajusta notablemente bien a los datos, cubriendo aproximadamente el 93% de la variabilidad observada. ¡Este rendimiento confirma la efectividad de su enfoque al estimar el precio del oro en función de su pureza!

Créditos: Disney/PIXAR
Sin embargo, Wall-E, como un perfeccionista incansable, no se conforma con el éxito ya logrado. Constantemente busca formas de mejorar su modelo.
Así, decide trascender el modelo lineal inicial optando por un enfoque polinomial (de grado 2). Modifica la función de referencia a y repite meticulosamente todos los pasos del algoritmo, sin dejar nada al azar. Aquí están los resultados que obtuvo.
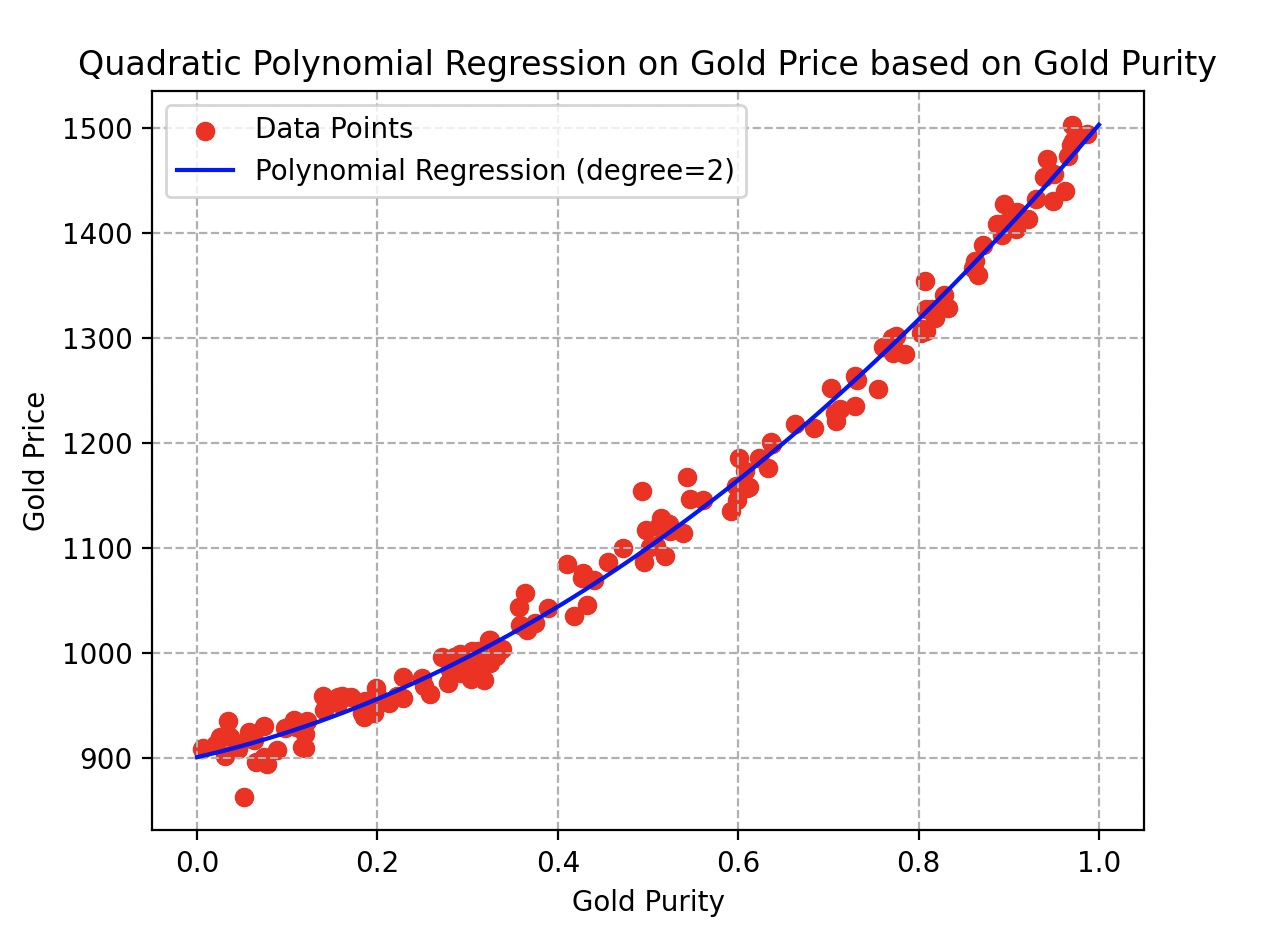
Curva de regresión polinómica de grado 2 sobre el precio del oro en función de su pureza
¡La curva se ajusta muy bien a los datos y por una buena razón! Con valores de parámetros de , y , alcanza un coeficiente de determinación sobresaliente del 97%. Observen aquí que una muestra de oro con una pureza de valdría alrededor de pernos.
Al contemplar este éxito, no se puede evitar anticipar con entusiasmo las futuras exploraciones de Wall-E en el complejo mundo del modelado y el aprendizaje automático.
Exploración Exitosa de los Intríngulis de la Regresión: Próximo Paso, el Fascinante Mundo de la Clasificación
En esta cautivadora exploración de los problemas de regresión, nos sumergimos en el fascinante universo del modelado matemático, con Wall-E como nuestro intrépido guía. Desde los descensos de gradiente hasta las curvas de aprendizaje, y a través de la definición de errores, desmitificamos aspectos clave de la regresión, revelando la magia subyacente del machine learning.
Mientras dejamos a Wall-E descansar sus circuitos después de sus hazañas de regresión, prepárense para embarcarse en una nueva aventura en nuestro próximo artículo. Nos sumergiremos en los misterios de los problemas de clasificación, explorando cómo los modelos pueden aprender a categorizar y tomar decisiones en un mundo de datos complejos. ¡Manténganse atentos para una inmersión aún más profunda en el universo dinámico del machine learning con Wall-E como su fiel compañero de viaje!
Bibliografía
- G. James, D. Witten, T. Hastie y R. Tibshirani, An Introduction to Statistical Learning, Springer Verlag, coll. “Springer Texts in Statistics”, 2013
- D. MacKay, Information Theory, Inference, and Learning Algorithms, Cambridge University Press, 2003
- T. Mitchell, Machine Learning, 1997
- F. Galton, Kinship and Correlation (reimpreso en 1989), Statistical Science, Institute of Mathematical Statistics, vol. 4, no 2, 1989, pp. 80–86
- C. Bishop, Pattern Recognition and Machine Learning, Springer, 2006
- G. Saint-Cirgue, Machine Learnia, canal de YouTube
- D. V. Lindley, Regression and Correlation Analysis, 1987