
En tant que robot fidèle à sa mission et entre quelques estimations d’or, Wall-E n’oublie pas sa principale tâche : trier les déchets. C’est lors de ses expéditions dans les endroits reculés de la planète qu’il découvrit le défi ultime qui stimule son esprit curieux. Parmi les objets qu’il amasse, Wall-E tombe sur une collection variée de vieux composants électroniques, certains en bon état qu’il ramène à la base, et d’autres défectueux qu’il entrepose dans un coin.
Passionné par de tels objets, il se met à dévisser, à arracher et à classer soigneusement chaque composant en deux catégories distinctes (classification binaire) : d’un côté les pièces de métal précieuses (classification multiclasse) et de l’autre le plastique sans valeur. La question fondamentale est : comment réalise-t-il une telle mission ?
Il est fortement conseillé d’avoir lu l’épisode I et II avant de continuer !
Les Nouveaux Horizons de Wall-E : la Classification
L’épopée de notre intrépide robot solitaire, Wall-E, prend une nouvelle dimension fascinante lors de son exploration du vaste royaume de la classification. Après avoir brillamment maîtrisé l’art de la régression lors de l’épisode précédent (voir l’article Wall-E le petit mineur d’or), Wall-E entreprend courageusement une nouvelle phase en se lançant dans le tri binaire entre métaux précieux et plastiques. Cette première étape préparatoire marque le début d’une quête plus complexe, où Wall-E déploie avec audace ses compétences en classification.
S’appuyant sur ses succès initiaux, Wall-E décide d’élargir son champ d’action en s’attaquant à la classification multi-classe des métaux, faisant ainsi de l’algorithme K-Nearest Neighbors (KNN) son allié privilégié. Ce nouveau défi demande à Wall-E une compréhension plus approfondie, car il doit non seulement distinguer entre deux catégories, mais également classifier différents types de métaux tels que le bronze, l’or et l’argent.
L’Élément Clé : Toujours Les Données
À la Rencontre des Échantillons
Chaque exemple était un élément avec des caractéristiques spécifiques, telles que la densité , la conductivité thermique , électrique etc. Pour illustrer notre cas simplement, nous allons considérer uniquement la variable densité .
Ainsi, pour chaque échantillon , Wall-E note s’il est un métal (étiqueté comme ) ou un plastique (étiqueté comme ). En voici un exemple concret de 5 échantillons (parmi les 650 qu’il connaît déjà) :
| Échantillon | Densité | Type de Composant |
|---|---|---|
| 1 | 2.165747 | Plastique |
| 2 | 7.151579 | Métal |
| 3 | 0.901240 | Plastique |
| 4 | 19.24357 | Métal |
| 5 | 12.54564 | Métal |
Les Frontières de la Décision
La différence avec le problème précédent est qu’il faut définir ici ce que l’on nomme une frontière de décision. Au lieu de regarder chaque objet individuellement, Wall-E décide de diviser cet espace en différentes régions. Chaque région serait destinée à recevoir un type spécifique d’objet, soit métal, soit plastique. Les limites de ces régions définiront des frontières.
Lorsque Wall-E dessine ces frontières, il veut s’assurer que les objets similaires se trouvent dans la même région. Idéalement, il aimerait que les deux groupes soient parfaitement séparés, comme s’ils étaient dans des boîtes distinctes. Une simple ligne pourrait faire l’affaire.
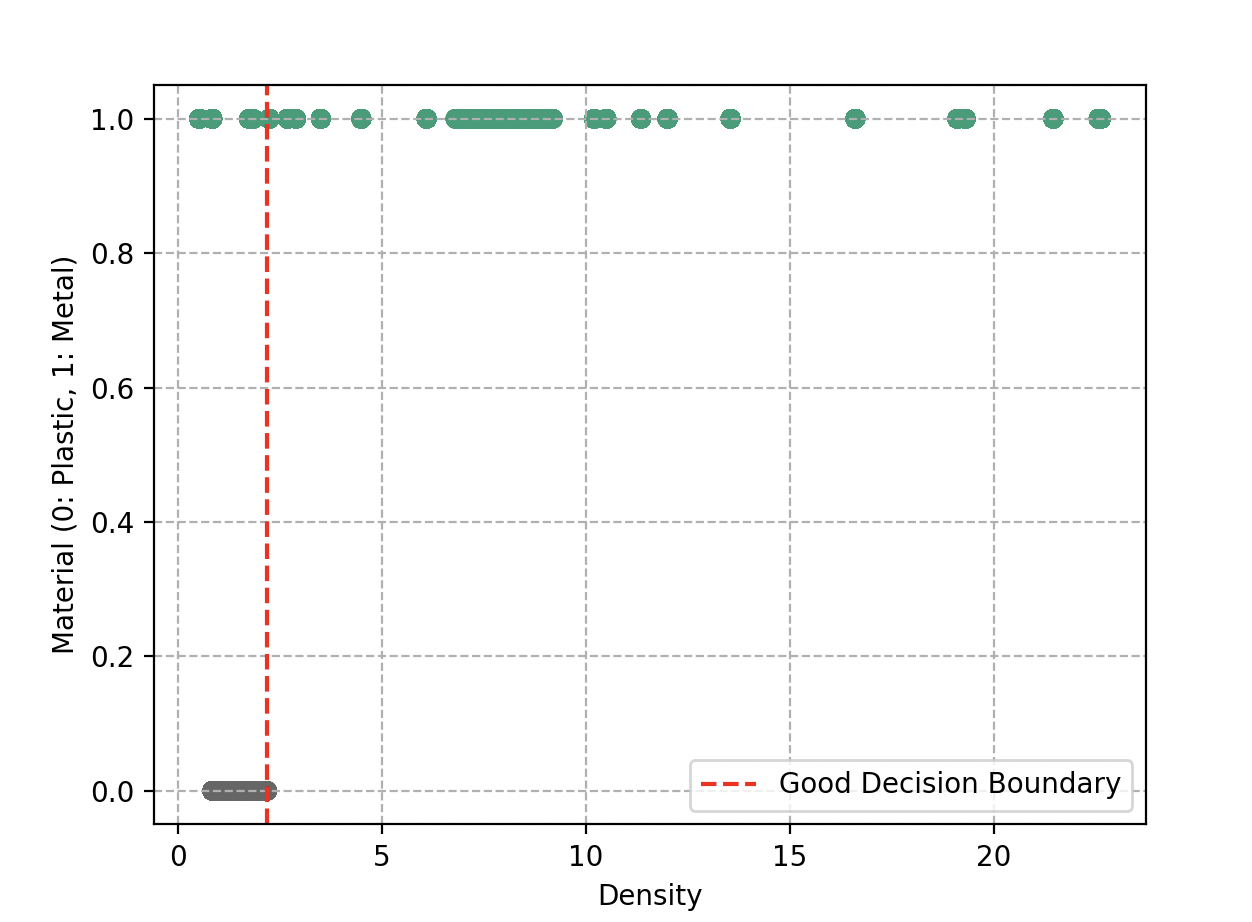
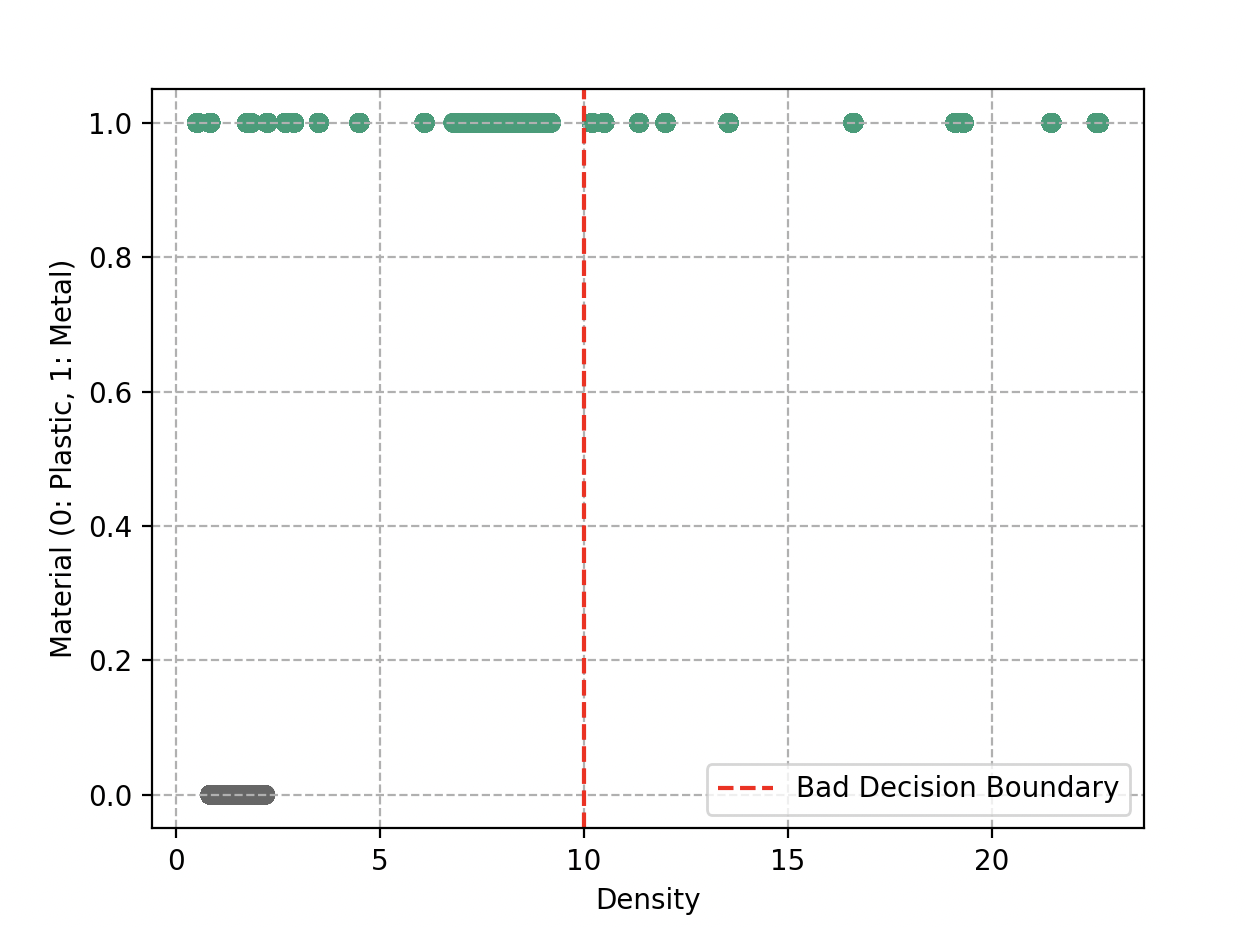
Cependant, la réalité n’est pas toujours aussi simple. Parfois, il y a des objets qui se retrouvent de l’autre côté de la ligne. Wall-E est aussi conscient qu’il ne doit pas se compliquer la tâche en dessinant des frontières zigzagantes et complexes. Cela pourrait mener à un sur-apprentissage.
Création du Modèle de Classification Binaire
Wall-E opte pour un modèle classique de régression logistique dont la fonction associée (comprise entre 0 et 1) s’exprime de la manière suivante :
Elle se nomme fonction sigmoïde (à cause de sa forme en « S »).

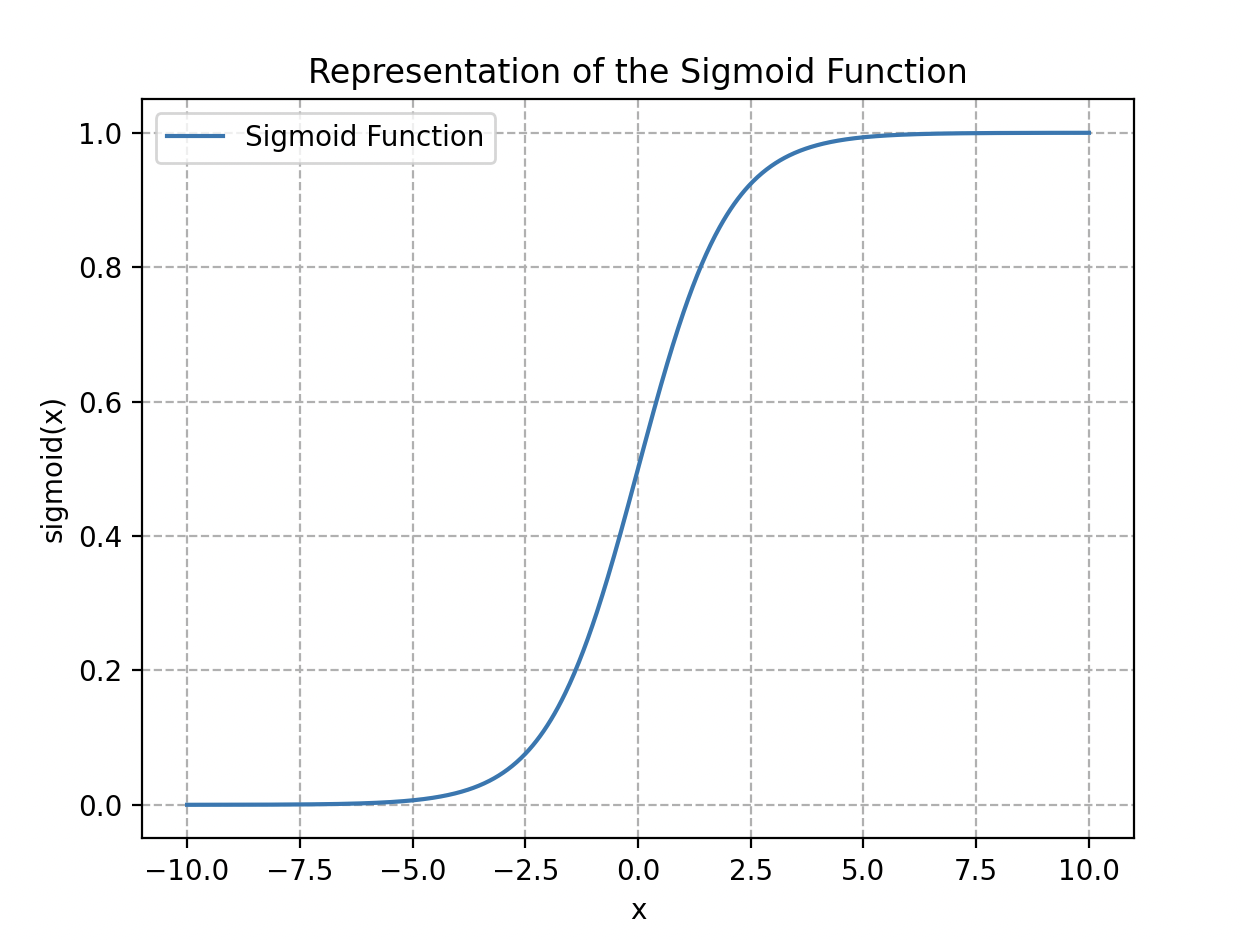
Représentation de la fonction logistique ou sigmoïde
En appliquant cette fonction à notre dataset, on obtient où peut être une fonction linéaire comme ou polynomiale comme avec , et les paramètres à ajuster.
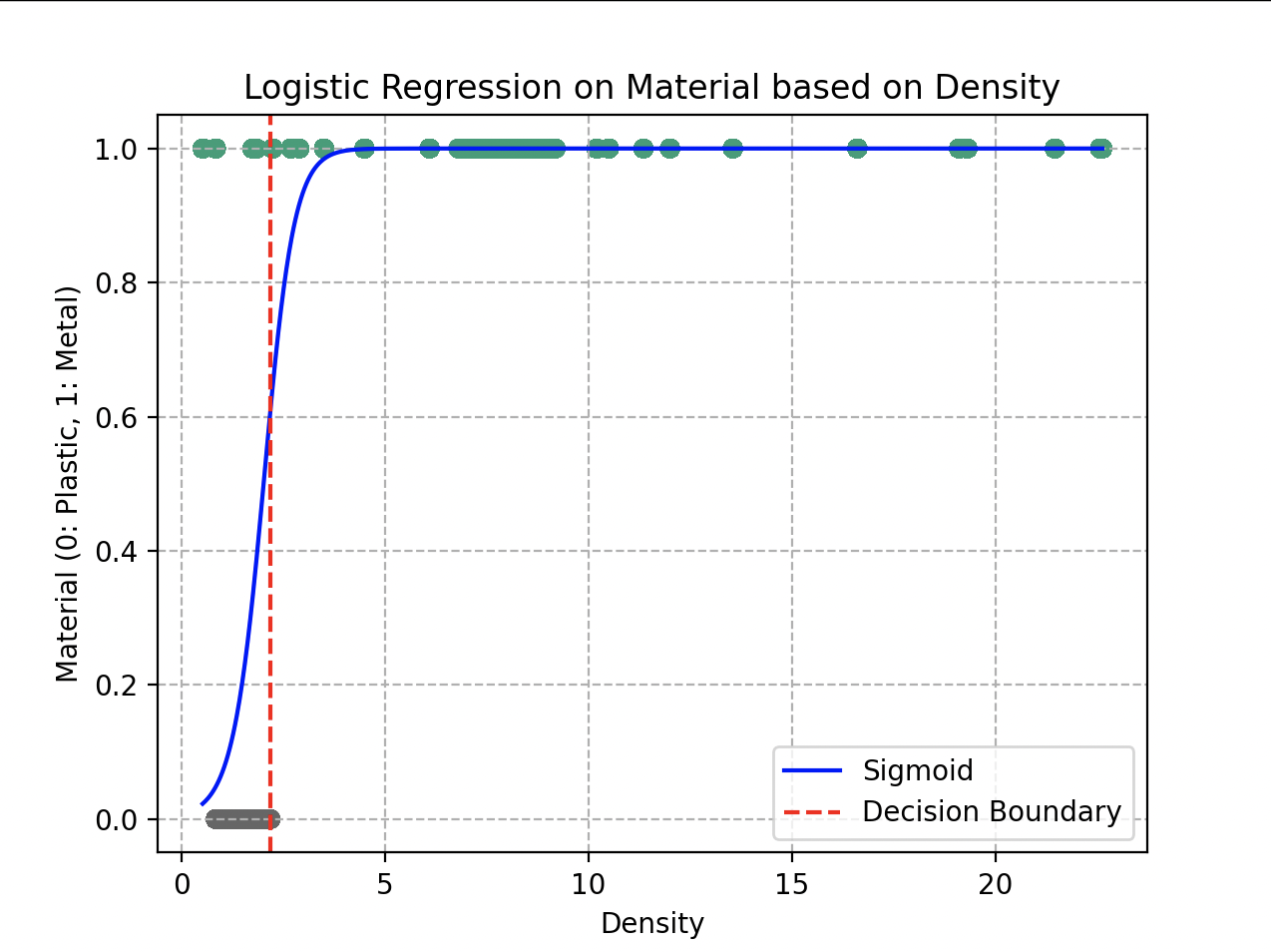
Le gros avantage d’une telle fonction est que nous pouvons définir très facilement une frontière de décision en fixant une valeur seuil de décision. Ainsi, si la probabilité est supérieure à 0,5, on classifie l’objet dans la catégorie « métal » ; si elle est inférieure à 0,5, ce sera du plastique.

Évaluation des Prédictions : la Fonction de Coût
Wall-E élabore son modèle, mais il désire évaluer la précision de ses prédictions. Pour ce faire, il pourrait utiliser une fonction coût classique de la régression, la MSE (voir l’article Wall-E le petit mineur d’or) :
Cependant, cette fonction de coût ne présente pas de caractère convexe ; en réalité, elle comporte plusieurs minima locaux. Cette particularité rend l’algorithme de la descente de gradient peu efficace, car en utilisant l’analogie d’un relief montagneux, Wall-E risque de rester piégé dans un minimum local qui n’est pas nécessairement le minimum global de la courbe.
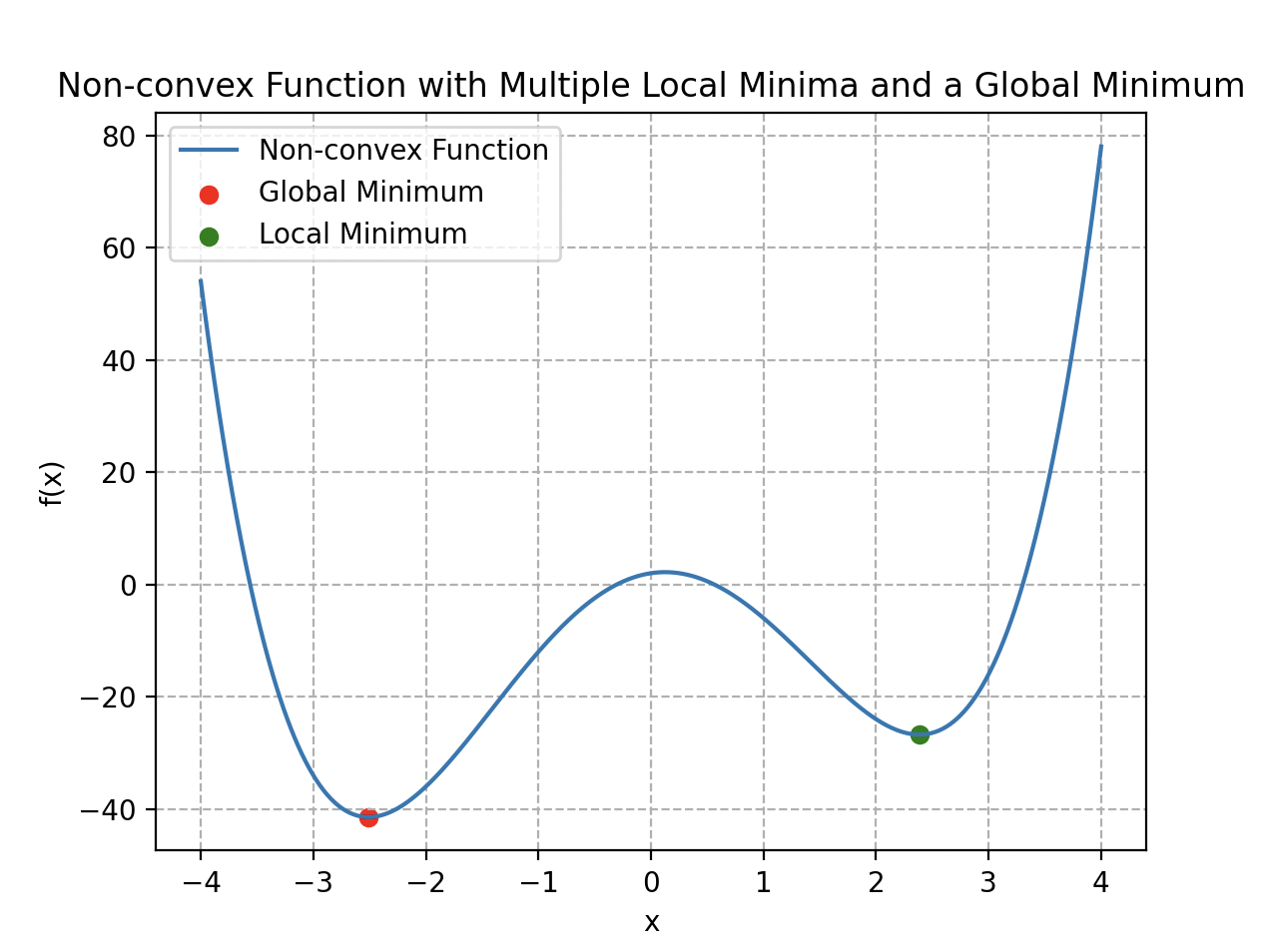
Exemple de fonction non convexe avec des minima locaux et un minimum global
Wall-E introduit donc une nouvelle fonction coût basée sur le logarithme (log-vraisemblance négative) :
Cette fonction possède la propriété de convexité, ce qui signifie qu’elle n’a qu’un seul minimum global et pas de minima locaux. Cela facilite l’utilisation de la descente de gradient pour ajuster les paramètres du modèle.
La première partie de la fonction de coût, lorsqu’une étiquette est 1, est représentée par le terme . La deuxième partie traite les cas où l’étiquette est 0 : .
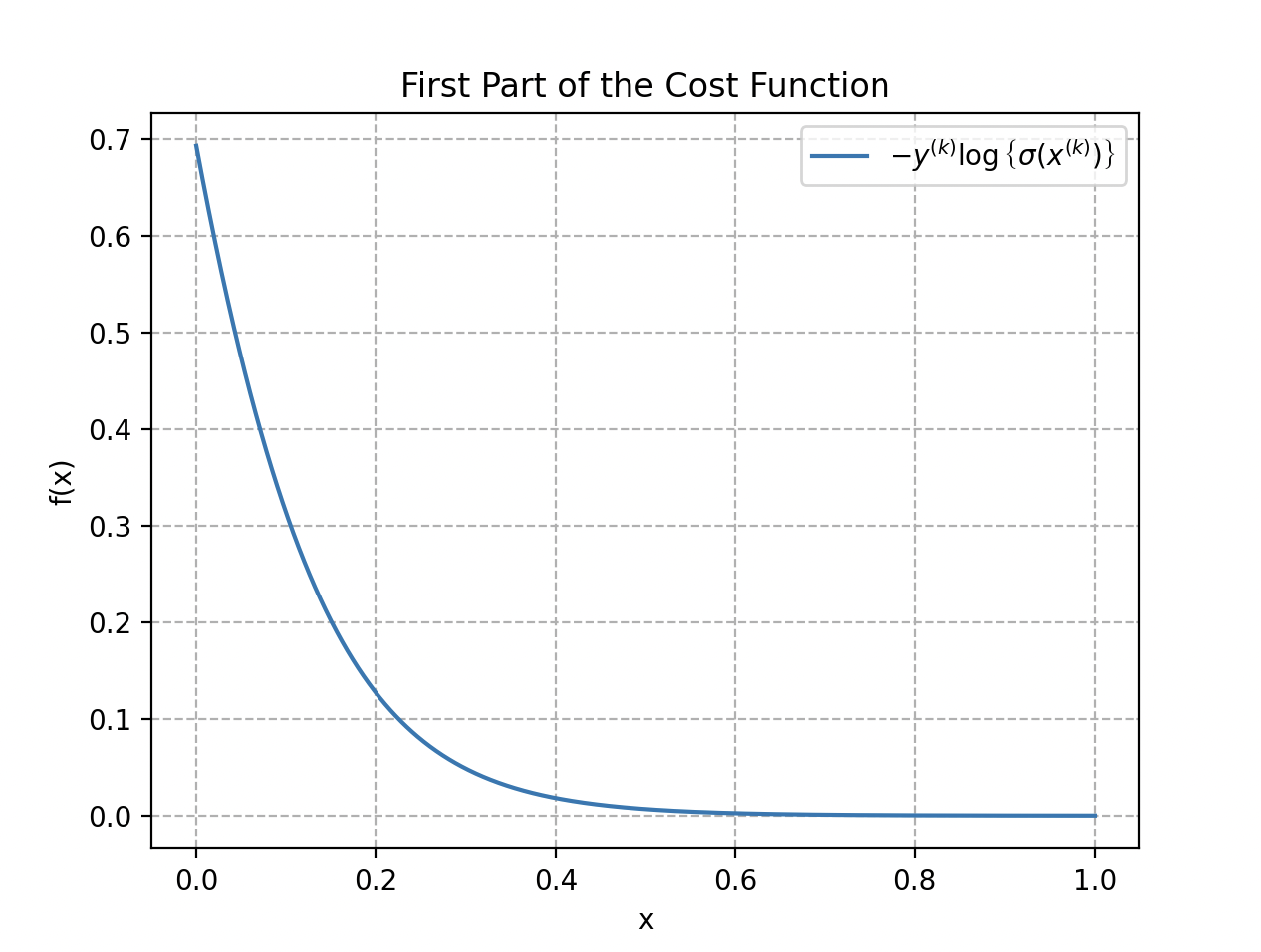
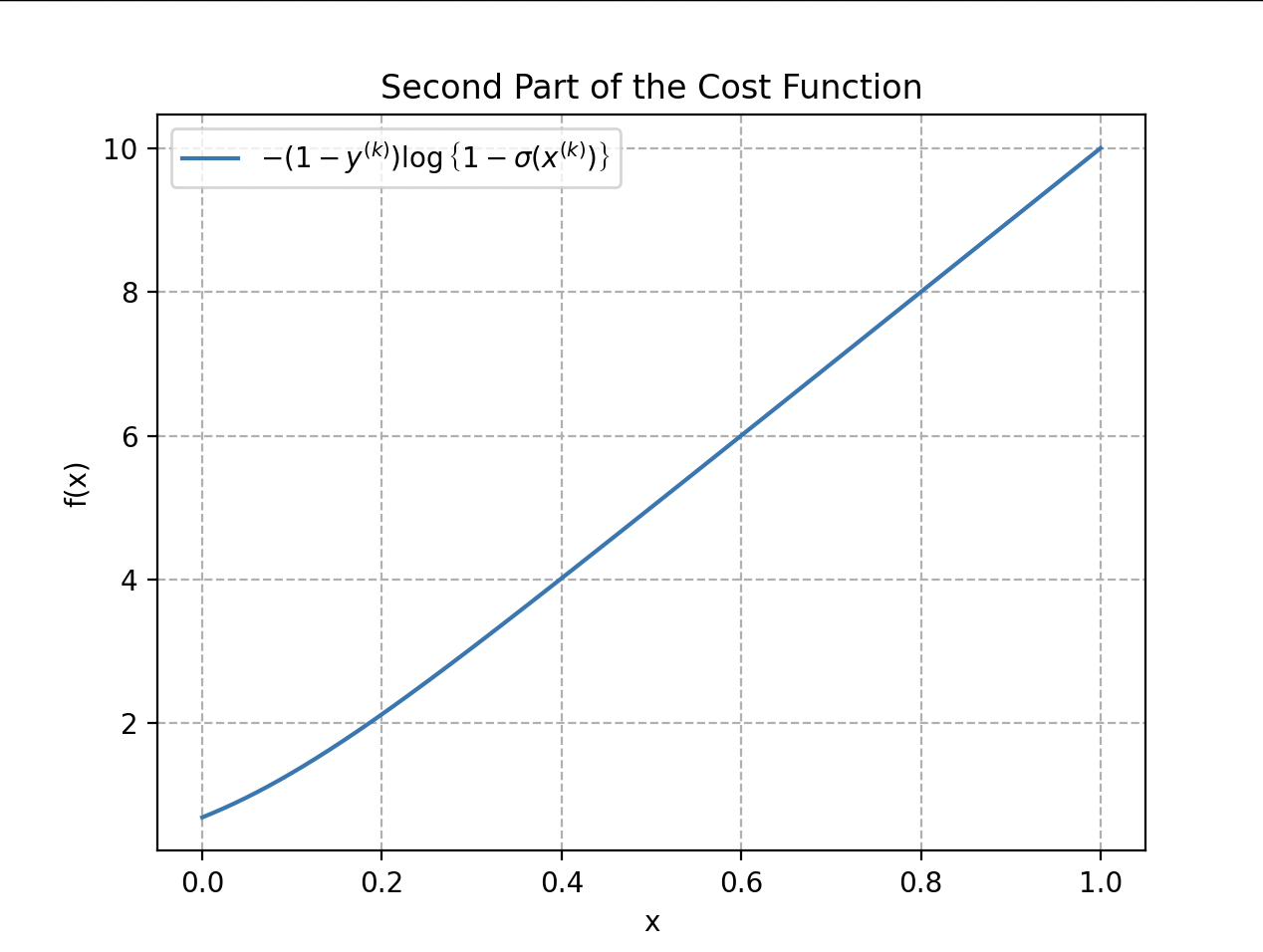
Lorsque dans la fonction coût vaut 1 seulement la première partie de la fonction agit ; s’il vaut 0 c’est l’autre. La fonction de coût totale est la moyenne de ces deux parties, prise sur l’ensemble des exemples d’apprentissage , pour obtenir une mesure globale de l’ajustement du modèle aux données d’entraînement.
La Redescente de Gradient
On fait exactement la même chose que pour la régression mais avec la nouvelle fonction coût. Les gradients s’écrivent :
Et la mise à jour des paramètres :

Crédits : Disney/PIXAR
La Puissance du Petit Trieur de Déchets
En notation matricielle, avec le vecteur , la matrice et le vecteur paramètre , la fonction sigmoïde s’applique sur chaque coordonnée :
La fonction coût devient :
et son gradient :
avec la mise à jour :
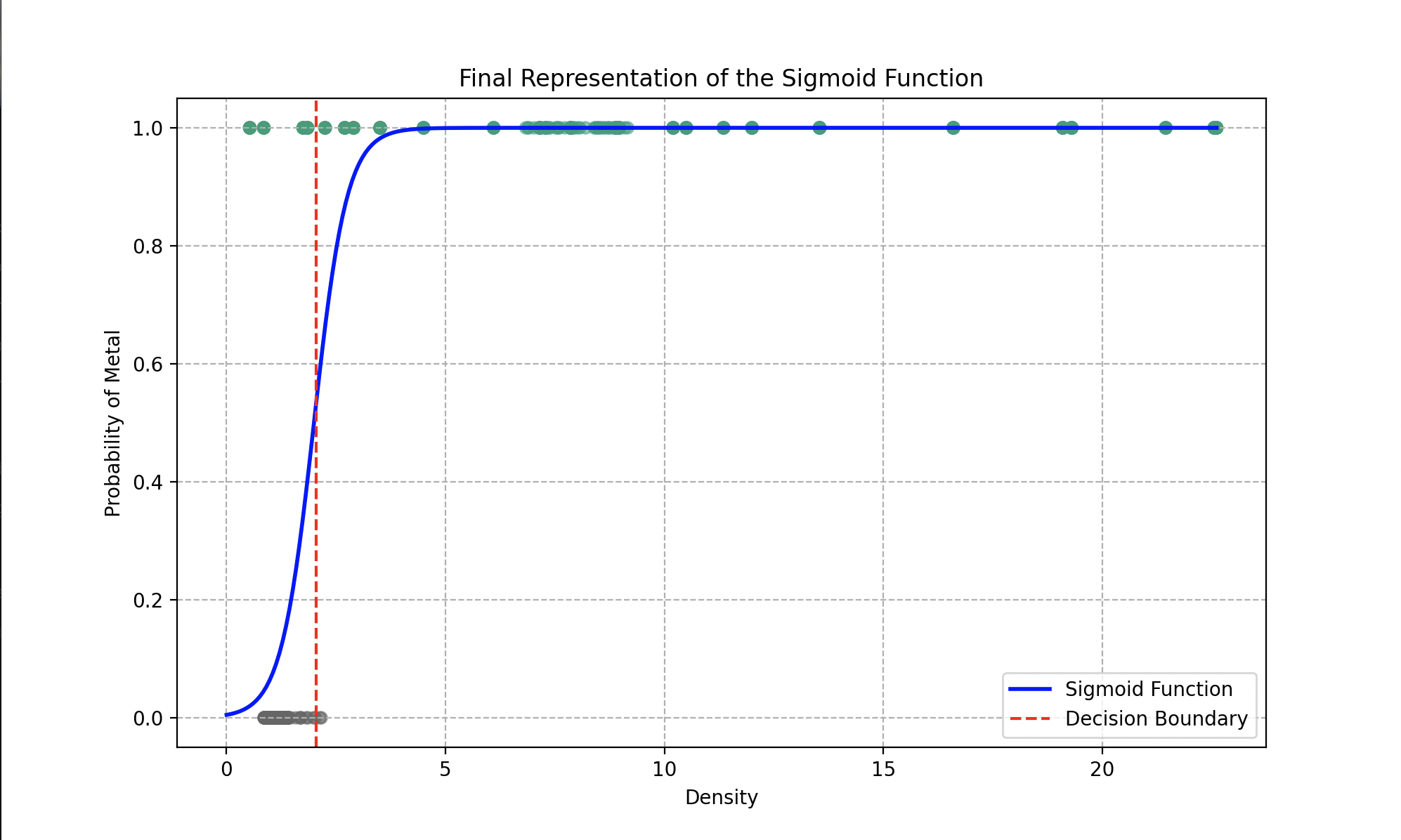
Représentation finale de la fonction sigmoïde s’ajustant au mieux aux données présentes
Les paramètres optimaux obtenus après la descente de gradient sont et . Le modèle peut, de manière générale, déterminer avec une précision de 93% si le matériau fourni est du métal ou du plastique.
Au-delà du Tri de Déchets : Déterminer le Type de Métal
Explorant plus profondément le domaine de la classification des métaux, Wall-E se confronte à un défi plus complexe : la détermination du type spécifique de métal parmi une variété d’alliages comprenant le bronze, l’or, l’argent, et bien d’autres.
Pour relever ce défi, l’outil de prédilection de Wall-E devient l’algorithme des K plus proches voisins (KNN). Voici la liste de tous les métaux purs enregistrés pour Wall-E :
| Type de Métal | Conductivité Électrique (en Giga S/m) | Densité |
|---|---|---|
| Acier | 1.5 | 7.500 - 8.100 |
| Aluminium | 37.7 | 2.700 |
| Argent | 63 | 10.500 |
| Béryllium | 31.3 | 1.848 |
| Bronze | 7.4 | 8.400 - 9.200 |
| Carbone (graphite) | 61 | 2.250 |
| Cuivre | 59.6 | 8.960 |
| Étain | 9.17 | 7.290 |
| Fer | 9.93 | 7.860 |
| Iridium | 19.7 | 22.560 |
| Lithium | 10.8 | 5.30 |
| Magnésium | 22.6 | 1.750 |
| Mercure | 1.04 | 13.545 |
| Molybdène | 18.7 | 10.200 |
| Nickel | 14.3 | 8.900 |
| Or | 45.2 | 19.300 |
| Osmium | 10.9 | 22.610 |
| Palladium | 9.5 | 12.000 |
| Platine | 9.66 | 21.450 |
| Plomb | 4.81 | 11.350 |
| Potassium | 13.9 | 0.850 |
| Tantale | 7.61 | 16.600 |
| Titane | 2.34 | 4.500 |
| Tungstène | 8.9 | 19.300 |
| Uranium | 3.8 | 19.100 |
| Vanadium | 4.89 | 6.100 |
| Zinc | 16.6 | 7.150 |
Cela simule des alliages métalliques, où chaque alliage est considéré comme composé d’un métal pur à déterminer et d’impuretés modifiant légèrement ses caractéristiques. La base de données de Wall-E comporte 300 échantillons pour chaque type d’alliage métallique. En voici cinq, chacun caractérisé par ses propriétés distinctives :
| Type de Métal | Conductivité Électrique (en Giga S/m) | Densité |
|---|---|---|
| Acier | 2.7093 | 7.7446 |
| Vanadium | 5.8000 | 7.5000 |
| Fer | 9.2600 | 8.4000 |
| Or | 43.000 | 18.500 |
| Bronze | 7.5132 | 8.7000 |
Le but de Wall-E sera donc de classifier chaque échantillon métallique qu’il trouvera en fonction de sa densité et de sa conductivité électrique dans une catégorie de métaux purs.
Contraste avec la Classification Binaire et Complexités de la Classification Multiclasse
Wall-E, après avoir maîtrisé la classification binaire pour distinguer les métaux précieux des plastiques, se rend compte que l’étape suivante, la classification multiclasse, représente un défi plus complexe. Alors que la classification binaire divise simplement les objets en deux catégories distinctes, Wall-E doit maintenant différencier entre des types spécifiques. La simplicité d’une frontière de décision comme une droite, utilisée dans la classification binaire, ne suffit plus.
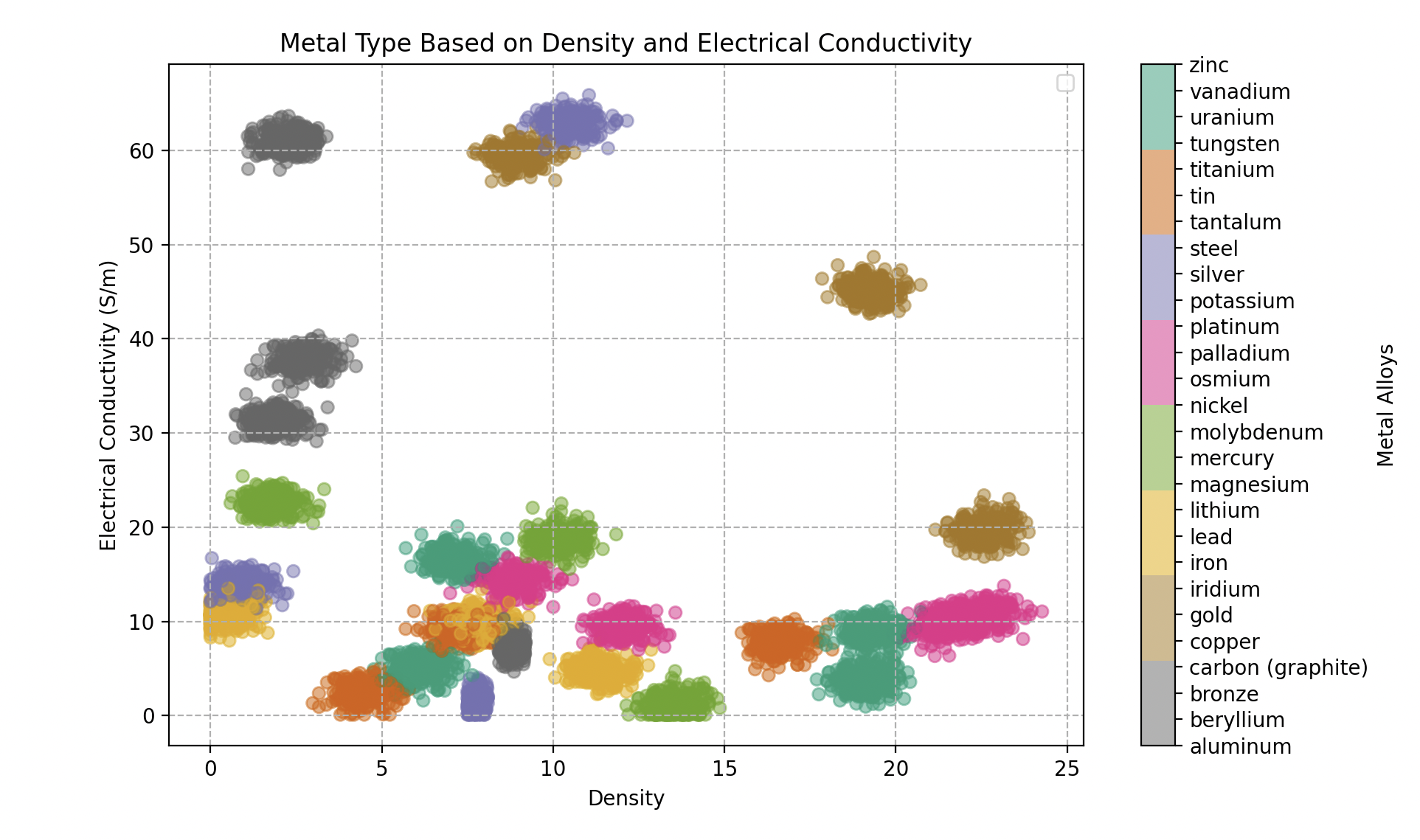
Type de métal en fonction de la densité et de la conductivité électrique (en Giga Siemens par mètres). 300 échantillons pour chaque alliage.
Dans ce nouveau territoire, Wall-E doit naviguer dans un espace caractéristique complexe où les métaux peuvent tous se chevaucher. Cette complexité exige une approche plus raffinée, et c’est ici que Wall-E se tourne vers une méthode qui prend en compte les subtilités des relations entre les métaux.
Le Pouvoir de la Proximité : K Nearest Neighbors
L’idée essentielle derrière KNN consiste à regrouper des objets similaires dans l’espace des caractéristiques. Dans notre contexte, si un morceau de bronze partage des caractéristiques similaires avec d’autres morceaux de bronze, ces objets seront situés à proximité les uns des autres dans cet espace multidimensionnel.
Son processus de fonctionnement est assez intuitif. Lorsqu’un nouveau morceau de métal doit être classifié, Wall-E mesure ses caractéristiques spécifiques, le positionnant dans l’espace des caractéristiques. Ensuite, l’algorithme identifie les voisins les plus proches. Une fois les voisins identifiés, KNN attribue au nouveau morceau le type de métal qui recueille le plus de votes parmi ces voisins proches.
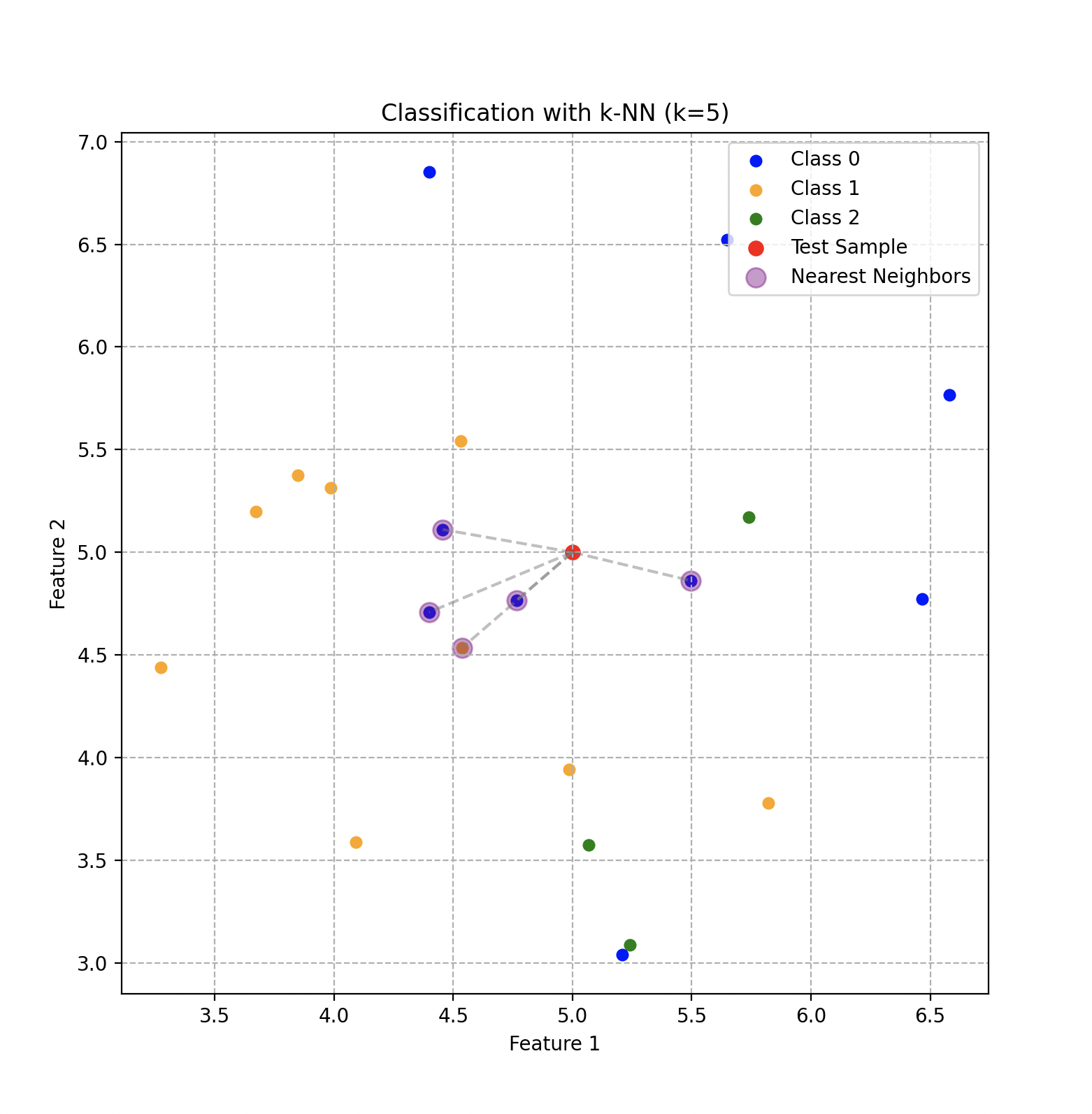
Classification en utilisant l’algorithme KNN avec 5 voisins et 3 classes qui dépendent de deux caractéristiques.
Processus de Classification Métallique : les Voisins à l’Action
Wall-E recherche dans sa base de données relativement étendue, comprenant divers types de métaux et alliages, chacun associé à des caractéristiques spécifiques telles que la conductivité électrique, la densité et d’autres propriétés uniques. Lorsqu’un nouveau morceau de métal se présente, Wall-E active l’algorithme KNN pour déterminer son type :
- Mesure des caractéristiques : Wall-E mesure les caractéristiques du nouveau morceau de métal, le plaçant dans l’espace caractéristique.
- Identification des voisins proches : KNN identifie les voisins les plus proches du nouveau morceau dans cet espace.
- Majorité des votes : Wall-E attribue au nouveau morceau le type de métal majoritaire parmi les voisins proches.

Crédits : Disney/PIXAR
Avec un paramètre optimal de 20 voisins, Wall-E peut affirmer avec une assurance avoisinant les 95% sa capacité à identifier n’importe quel alliage métallique.
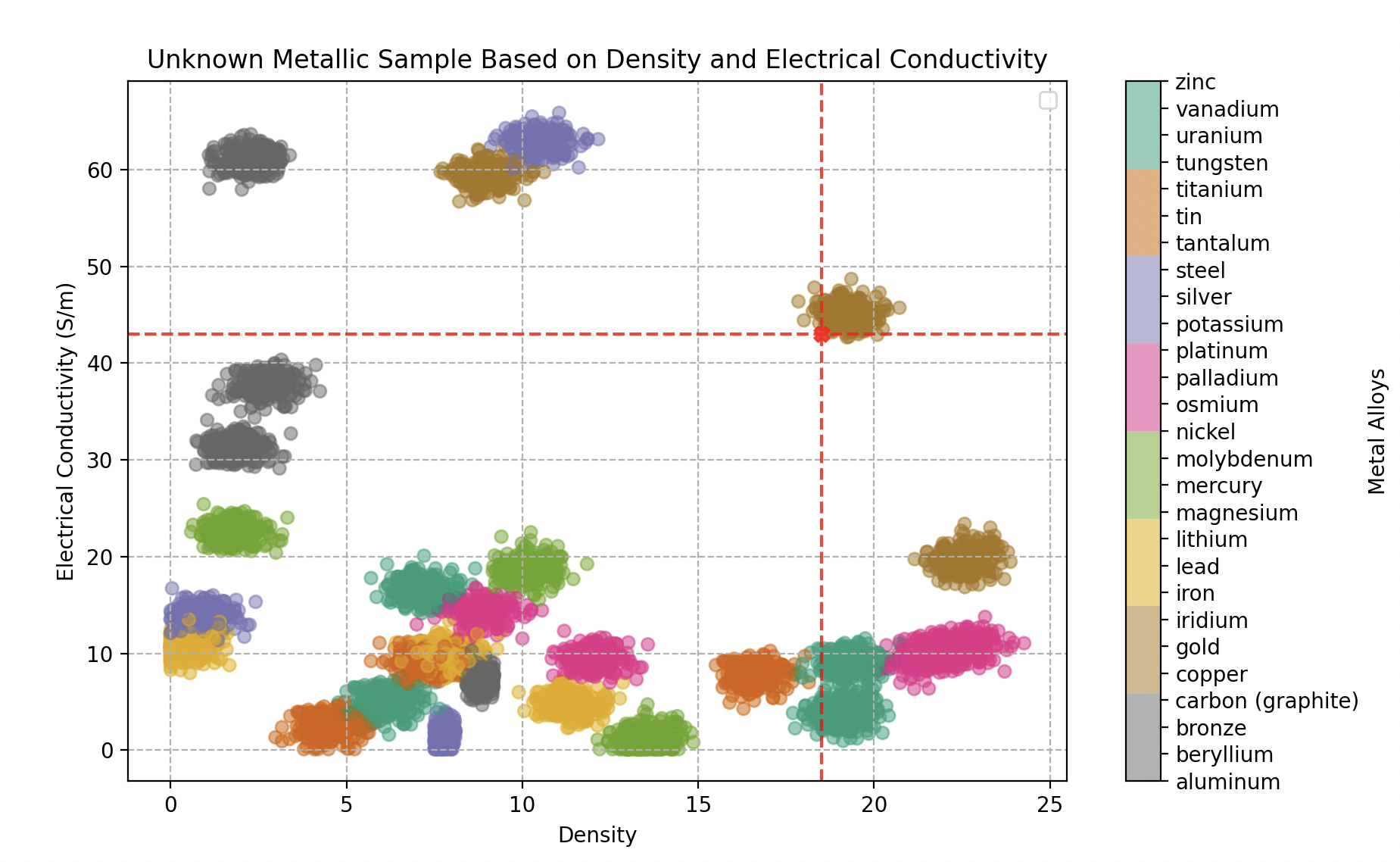
Classement d’un échantillon métallique inconnu en fonction de sa densité et de sa conductivité électrique qui se révèle être un alliage d’or
- Le premier objet analysé (densité 18,5, conductivité 43 GS/m) est identifié comme de l’or à 100%.
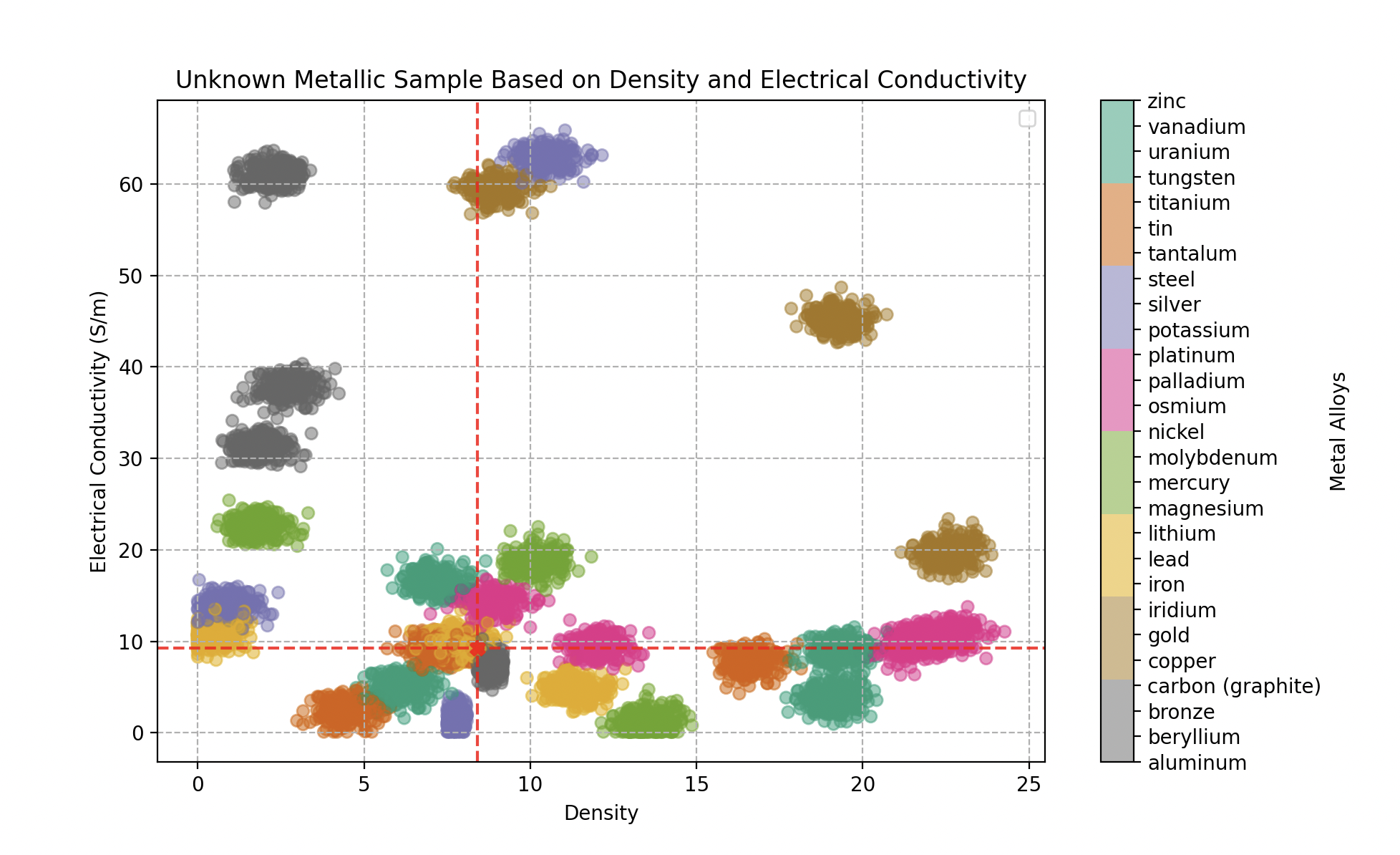
Classement d’un échantillon métallique inconnu : alliage de fer (70% fer, 20% bronze, 10% étain)
- Le deuxième (densité 8,4, conductivité 9,26 GS/m) : 70% fer, 20% bronze, 10% étain.
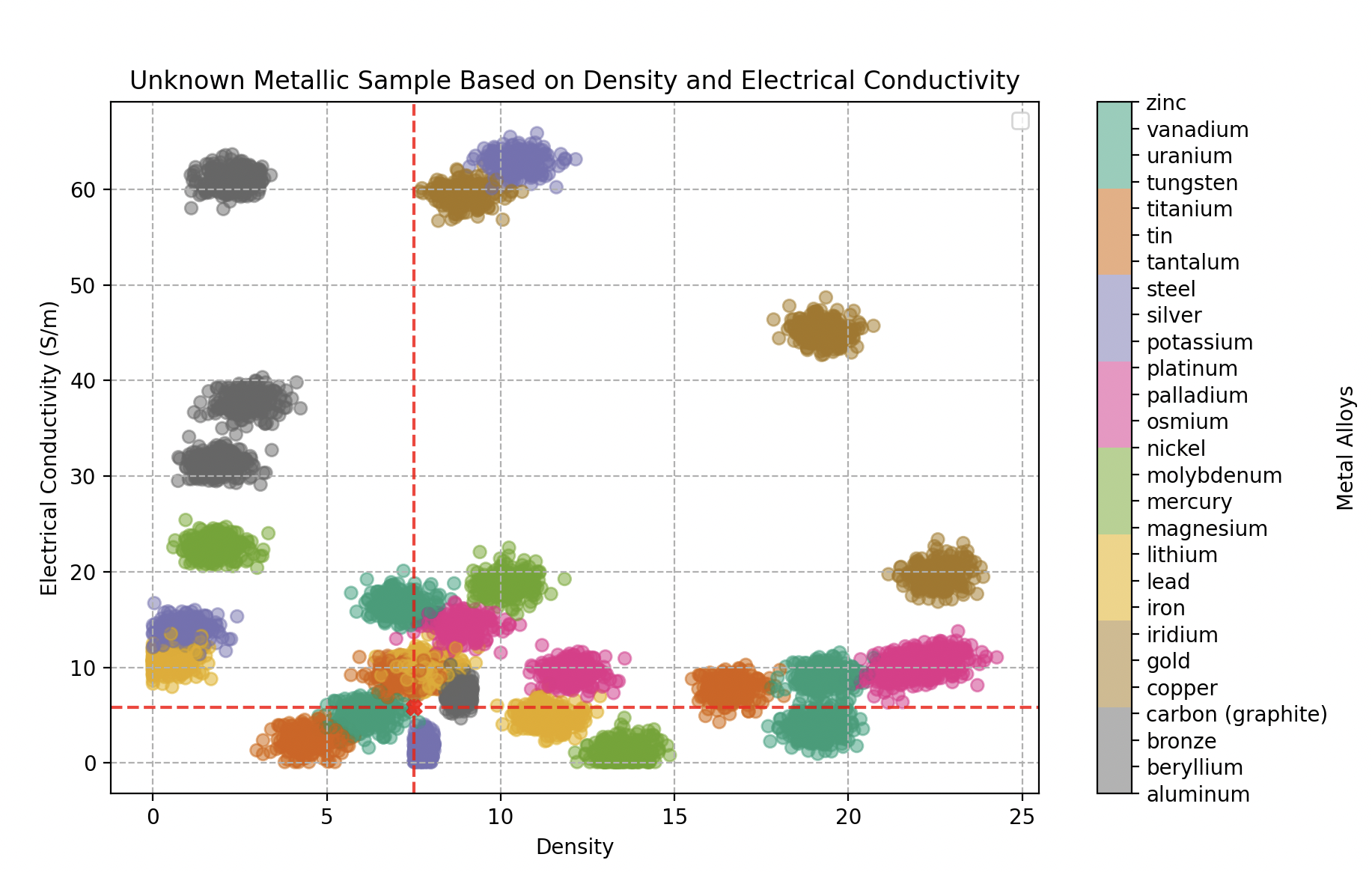
Classement d’un échantillon métallique inconnu : alliage de vanadium (70% vanadium, 25% étain, 5% fer)
- Le troisième (densité 7,5, conductivité 5,8 GS/m) : 70% vanadium, 25% étain, 5% fer.
L’Art de la Sélection du Modèle
Entraînement et Test
Wall-E saisit rapidement l’importance de ne jamais évaluer son modèle sur les mêmes données qui ont servi à son entraînement. Il divise l’ensemble des données en deux parties :
- Train set (80%) : dédié à l’entraînement du modèle.
- Test set (20%) : réservé à l’évaluation finale.

Crédits : Disney/PIXAR
Validation du Modèle
Pour ajuster les hyperparamètres (comme le nombre de voisins du KNN), Wall-E introduit une troisième section : le validation set. Il compare différents modèles — KNN avec 2, 3, 20 ou 100 voisins — en suivant cette méthodologie :
- Entraîner les modèles sur l’ensemble d’entraînement.
- Sélectionner le modèle avec les meilleures performances sur l’ensemble de validation.
- Évaluer ce modèle sur l’ensemble de test.
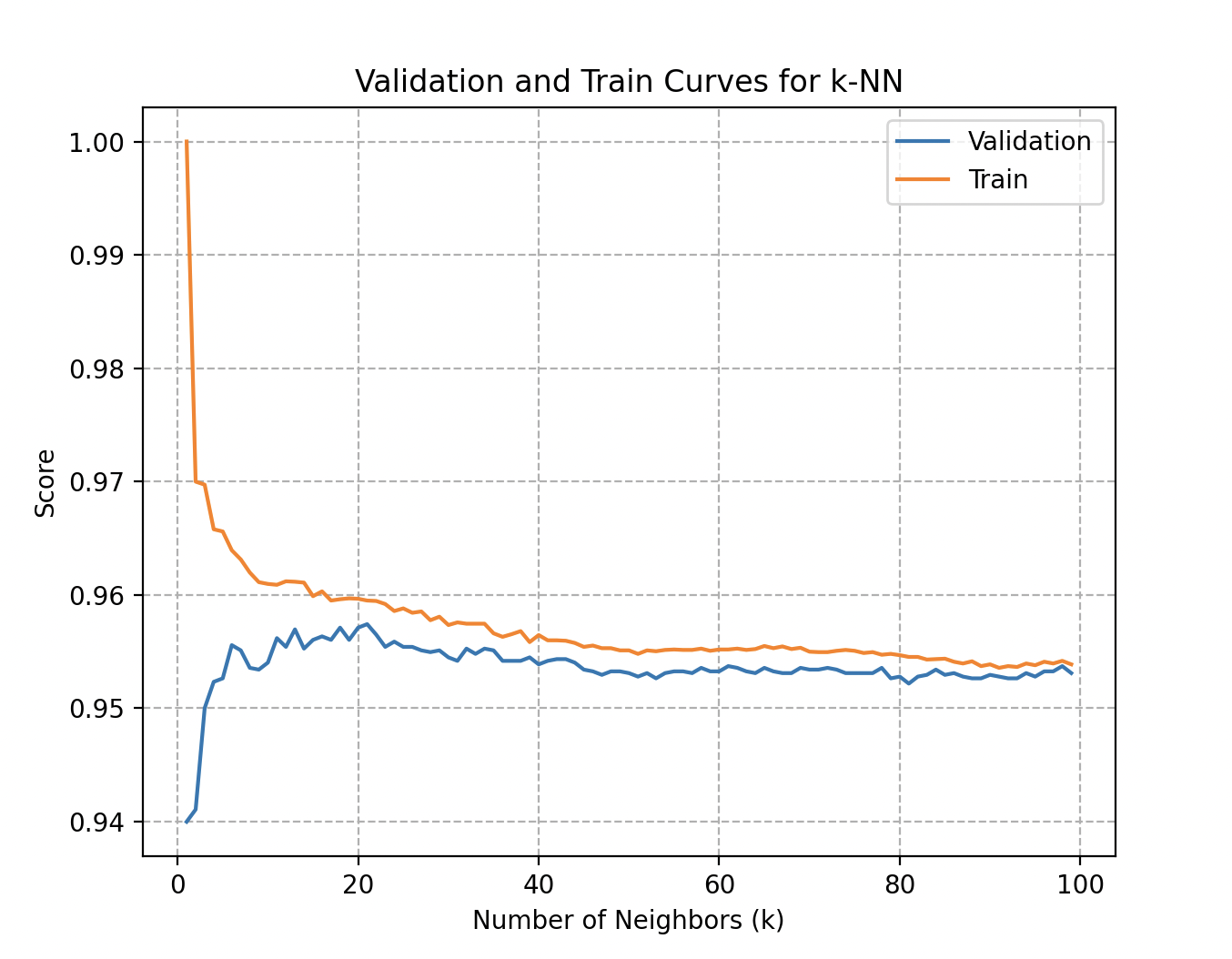
Courbes de validation et d’entraînement représentant le score de précision en fonction du nombre de voisins utilisés dans l’algorithme KNN
Plus précisément, la courbe de validation pour le nombre de voisins dans le KNN offre des réponses à des questions clés :
- Sur-ajustement (overfitting) : un écart significatif entre le score d’entraînement et le score de validation peut indiquer que le modèle est trop complexe et perd en généralisation.
- Sous-ajustement (underfitting) : à l’inverse, un modèle qui n’a pas bien appris les motifs dans les données d’entraînement présente des performances médiocres et conduit à des prédictions peu fiables.
- Sensibilité au choix du paramètre : observer les variations de performance permet de choisir une valeur optimale de .
Dans son cas, les deux courbes atteignent rapidement le score de 95,7% de précision à partir d’environ 20 à 25 voisins.
Validation Croisée
Wall-E utilise la méthode K-fold (avec 5 partitions). Pendant l’entraînement, le modèle est systématiquement entraîné sur de ces partitions et validé sur la partition restante, répétant ce processus fois. Il exploite également le Stratified K-fold, qui prend en compte la distribution des classes dans l’ensemble de données.
Courbes d’Apprentissage
Curieux de déterminer si son modèle peut bénéficier d’une amélioration par l’ajout de données supplémentaires, Wall-E examine les courbes d’apprentissage. Bien que l’ajout de données puisse initialement conduire à une amélioration des performances, Wall-E reconnaît que ces avantages finissent par atteindre un seuil.
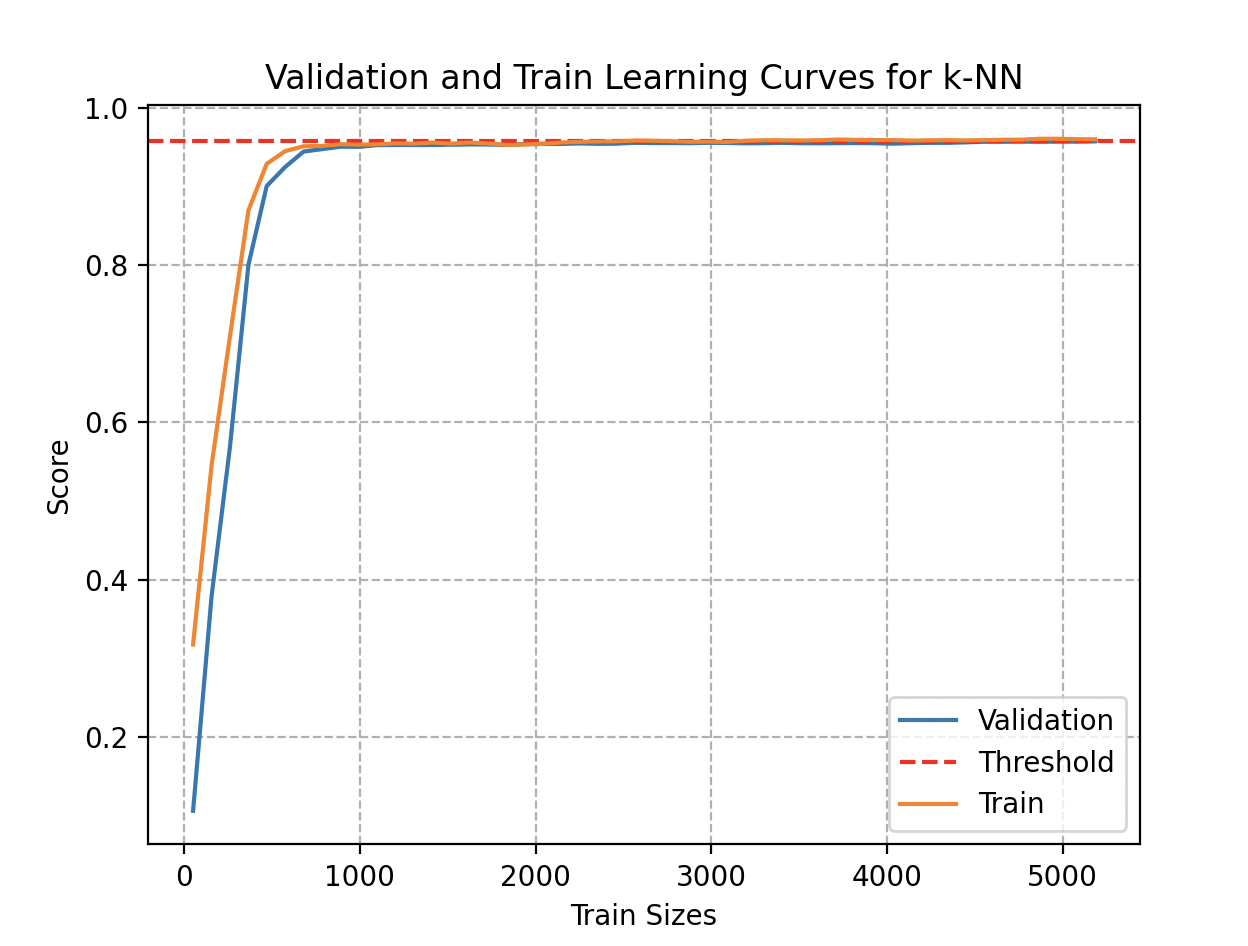
En examinant cette courbe, il remarque qu’une estimation suffisamment précise aurait pu être obtenue en utilisant moins de 1000 échantillons de métaux. Même en accumulant 300 échantillons pour chaque type (8100 objets au total), la précision stagne à 95,7%.
La Fin d’une Trilogie, le Début d’une Ère Technologique
Ce dernier épisode marque la conclusion de la saga captivante du petit robot Wall-E, une aventure qui a débuté avec les fondamentaux du machine learning. Depuis ses premiers pas dans le royaume de l’intelligence artificielle, Wall-E a évolué à travers divers chapitres, explorant les principes de base de l’apprentissage automatique, plongeant dans l’étude approfondie de la régression, et finalement, gravissant les sommets complexes de la classification.
Cette saga, riche en enseignements, se clôture avec la certitude que Wall-E est désormais prêt à affronter de nouveaux défis dans le monde complexe de l’intelligence artificielle.

Crédits : Disney/PIXAR
Bibliographie
- G. James, D. Witten, T. Hastie et R. Tibshirani, An Introduction to Statistical Learning, Springer Verlag, 2013
- D. MacKay, Information Theory, Inference, and Learning Algorithms, Cambridge University Press, 2003
- T. Mitchell, Machine Learning, 1997
- C. Bishop, Pattern Recognition And Machine Learning, Springer, 2006
- J. Tolles, W-J. Meurer, “Logistic Regression Relating Patient Characteristics to Outcomes”, JAMA, 316 (5): 533–4, 2016
- B-V. Dasarathy, Nearest Neighbor (NN) Norms: NN Pattern Classification Techniques, 1991