
Dans un monde post-apocalyptique dévasté, où les vestiges de la civilisation humaine sont enfouis sous d’immenses montagnes de déchets, un petit robot solitaire du nom de Wall-E se fraie un chemin à travers ce paysage dystopique. Sa mission : le recyclage méthodique des déchets abandonnés depuis des années. Mais Wall-E ne se contente pas de trier les morceaux de plastique, les plaques de métal et les matières organiques.
À travers ses interactions avec son environnement, ce robot dévoué collecte également une abondance d’informations, analyse des millions de données et apprend de ses expériences pour s’adapter, survivre et accomplir ses tâches avec une efficacité remarquable. Les capacités de ce qui semblait n’être qu’un simple petit robot collecteur de déchets révèlent les prémices d’un domaine en plein essor : l’intelligence artificielle.

Crédits : Disney/PIXAR
L’Essence Même de l’Intelligence Artificielle : l’Apprentissage
Dans les premiers éclats de son existence, notre petit robot, à l’instar d’un ordinateur, naquit pour plonger dans les abîmes des calculs, ceux qui exigeraient des millions d’années pour trouver une réponse humaine. Les tâches, jadis titanesques pour les âmes terrestres, se dressèrent devant lui, insistant pour qu’il les apprivoise.
Mais dans ses circuits, une transformation allait se jouer — une transformation qui s’inspira des génies de la science du monde entier. Ils insufflèrent en notre robot une forme unique d’intelligence, une étincelle numérique qui changea la donne. Wall-E, jusque-là une machine, devenait une entité qui apprendrait et prendrait des décisions complexes. C’était l’aube de l’intelligence artificielle, une nouvelle ère technologique.
Face aux défis grandissants, Wall-E montra sa versatilité. Il s’engagea sans effort dans les deux types de situations que l’humanité lui présentait. Dans un cas, il suivait docilement les calculs programmés par les humains, répondant comme une calculatrice répondrait à un simple .
Cependant, il fut confronté à une énigme beaucoup plus complexe : comment différencier les types de déchets qu’il rencontrait ? Comment reconnaître le plastique du métal ou du matériau organique ? Ou plus généralement, comment résoudre un problème donné sans connaître le calcul requis à sa résolution ? C’est ici que l’apprentissage entre en scène, une méthode fascinante que nous appelons le Machine Learning. Une clé maîtresse pour une multitude de tâches : reconnaissance d’images, prédictions boursières, estimation de valeurs d’or, détection de failles en cybersécurité et, bien sûr, dans notre cas : le tri de déchets.
Pour doter cet ordinateur d’une intelligence apprenante, des méthodes inspirées de notre propre processus d’apprentissage ont été mises en œuvre. Trois approches fondamentales se distinguent.
L’apprentissage supervisé constitue la pierre angulaire du machine learning. À l’instar de notre propre expérience d’acquisition de connaissances, cette méthode guide le petit ordinateur à roulettes en lui fournissant des exemples pré-étiquetés. Comme un apprenti avide, Wall-E est exposé à des situations où les résultats attendus sont déjà connus. En observant ces exemples, il parvient peu à peu à généraliser les relations entre les entrées et les sorties, lui permettant ainsi de prendre des décisions et de résoudre des problèmes similaires plus tard.


Crédits : Disney/PIXAR
L’apprentissage non supervisé est une forme plus libre et exploratoire de l’intelligence artificielle. Cette méthode permet à l’ordinateur de découvrir de manière autonome des structures et des modèles cachés au sein des données, sans la nécessité d’exemples pré-étiquetés. Tel un explorateur intrépide, Wall-E utilise son analyse sensorielle pour discerner des schémas, regrouper des informations similaires et explorer les nuances de son environnement.
L’apprentissage par renforcement s’appuie sur un système de récompenses et de punitions pour guider l’ordinateur dans son apprentissage. À l’instar de nos propres motivations, Wall-E est récompensé lorsqu’il accomplit une tâche avec succès et subit des conséquences négatives en cas d’échec. Ces encouragements et ces sanctions lui permettent d’optimiser ses actions et d’affiner ses compétences au fil du temps.

Crédits : Disney/PIXAR
Bébé Robot Deviendra Grand : l’Architecture de l’Apprentissage Supervisé
À la naissance de Wall-E, l’humanité avait déjà tracé son exode vers les confins lointains de l’espace, laissant derrière elle une Terre étouffée sous le poids du dérèglement climatique et de la pollution envahissante. Les équilibres naturels qui avaient depuis si longtemps bercé notre monde avaient flanché, reléguant la planète à une nouvelle réalité.
Cependant, un groupe de scientifiques s’était engagé à rester sur cette terre fatiguée, guidé par une vision audacieuse : instruire ce petit robot plein de potentiel à différencier les métaux, à trier les plastiques, tout cela en vue d’une mission cruciale — nettoyer et régénérer la planète elle-même.

Crédits : Disney/PIXAR
C’est ainsi que s’amorça une phase d’apprentissage, où les savoirs humains furent transmis à Wall-E. Les scientifiques employèrent une méthode particulière pour guider ce robot apprenti : l’apprentissage supervisé. Cette base fondamentale du machine learning offrait à Wall-E la possibilité d’évoluer et de grandir en absorbant des exemples clairement étiquetés.
Les prémices de cette aventure s’articulent autour de quatre éléments cruciaux : le dataset, le modèle et ses paramètres, la fonction coût et l’algorithme d’apprentissage.
1. Le Dataset : un Trésor d’Informations
Telle une mine d’or pour Wall-E, le dataset constitue une collection organisée d’exemples sur lesquels le robot basera son apprentissage. Chaque exemple se compose de diverses variables d’entrée (features) qu’il dispose dans une matrice, et des sorties attendues correspondantes (targets) qu’il dispose dans un vecteur. Ces dernières sont ce que Wall-E cherchera à prédire.
Par exemple, pour enseigner à Wall-E à reconnaître des déchets, les caractéristiques spécifiques des objets constituent les données d’entrée (densité, conductivité électrique, teneur en carbone, etc.), et les étiquettes indiquant le type de chaque objet constituent les sorties attendues (plastique, métal, organique).
| Indice | Densité | Conductivité Électrique () | Teneur en Carbone | Matériel |
|---|---|---|---|---|
| 1 | 4.5 | 0 | Métal | |
| 2 | 0.5 | 0.5 | Organique | |
| 3 | 19.3 | 0 | Métal | |
| 4 | 1.1 | 0.4 | Organique | |
| 5 | 1.2 | 0 | Plastique |
Évidemment, en tant que robot trieur de déchets, cette tâche constitue sa mission principale. Mais notre petit robot se passionne aussi pour l’estimation du prix des métaux, notamment celui de l’or. Comme il ne comprend pas vraiment le système monétaire humain, il convertit tout en boulons. Pour le divertir, les scientifiques lui font analyser chaque bout de métal doré pour en déterminer la pureté et lui en donnent la valeur marchande.
| Indice | Pureté | Prix de l’or |
|---|---|---|
| 1 | 0.374540 | 1224.193388 |
| 2 | 0.950714 | 1483.925567 |
| 3 | 0.731994 | 1360.214557 |
| 4 | 0.598658 | 1284.274057 |
| 5 | 0.156019 | 1004.083221 |
Avec une base d’apprentissage beaucoup plus fournie, il pourra apprendre à classer le métal, le plastique et les matières organiques en fonction de leurs caractéristiques, et évaluer le prix d’un métal inconnu en fonction de sa pureté.
2. Le Modèle et ses Paramètres : l’Architecture de l’Apprentissage
Permettez-moi de vous présenter la structure que Wall-E utilisera pour apprendre à partir du jeu de données : son modèle. Imaginez une « boîte noire » — un dispositif électronique que Wall-E utilise pour traiter l’information et faire des prédictions. Elle est « noire » dans le sens où son fonctionnement interne est mystérieux et complexe, du moins du point de vue de Wall-E. À l’intérieur, il y a des engrenages, des leviers et des mécanismes cachés qui transforment les entrées en sorties.
À l’intérieur de cette boîte noire se trouvent les paramètres. Ce sont les réglages internes que Wall-E peut ajuster pour améliorer sa capacité à faire des prédictions précises — les boutons et molettes secrets qu’il peut tourner et appuyer pour rendre la boîte noire plus efficace. Lorsque nous parlons de modèle, nous nous référons à une configuration spécifique de cette boîte noire.
L’apprentissage supervisé consiste à ajuster les paramètres de cette boîte noire de manière à ce que les prédictions soient aussi proches que possible des bonnes réponses (étiquettes) fournies dans l’ensemble d’entraînement. En ajustant les paramètres et en observant comment les prédictions changent, Wall-E essaie de comprendre comment cette boîte noire fonctionne réellement et comment l’améliorer.
Ces modèles peuvent être de natures différentes : certains sont linéaires et d’autres non linéaires.
Modèles Linéaires : la Simplicité dans la Linéarité
Les modèles linéaires sont des représentations mathématiques relativement simples mais puissantes. Ils supposent que la relation entre les entrées et les sorties est linéaire — c’est-à-dire qu’elle peut être représentée par une droite (ou un plan ou un hyperplan dans un espace multidimensionnel).
Les scientifiques n’ont pas limité le robot au simple recyclage : ils lui ont aussi appris à estimer le prix d’un métal en fonction de sa pureté. En revisitant ses données, Wall-E dispose d’un dataset de échantillons d’or, où la pureté est la feature d’entrée et le prix correspondant la cible .
| Indice | ||
|---|---|---|
| 1 | 0.374540 | 1224.193388 |
| 2 | 0.950714 | 1483.925567 |
| 3 | 0.731994 | 1360.214557 |
| 4 | 0.598658 | 1284.274057 |
| 5 | 0.156019 | 1004.083221 |
L’échantillon 2 a par exemple une pureté et vaut boulons. En traçant les données (50 échantillons au lieu de 5, et imaginez qu’il pourrait y en avoir des millions) :

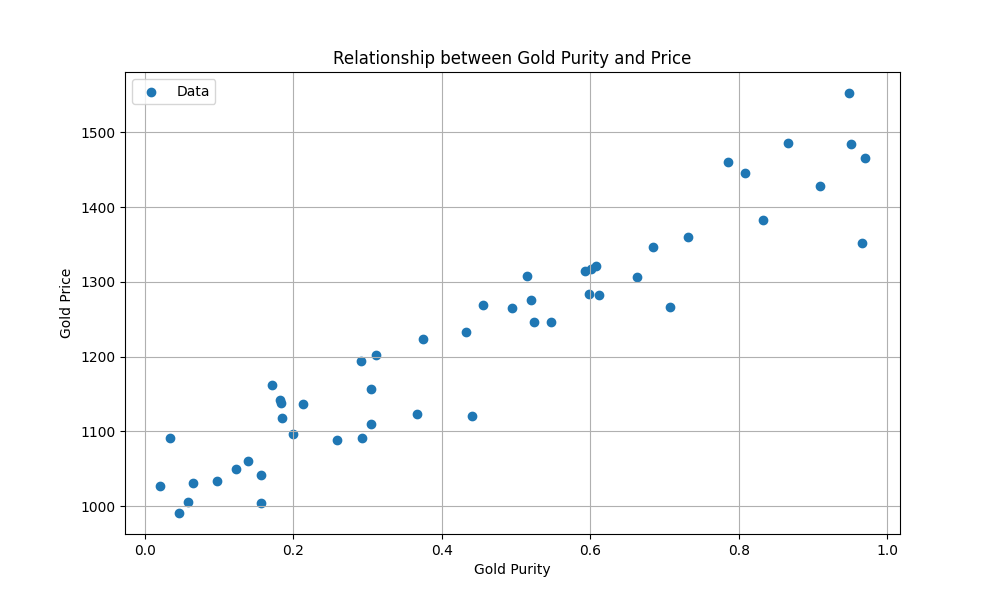
Crédits : Disney/PIXAR — Nuage de points du prix de l’or en fonction de sa pureté.
Un tel modèle pourrait être représenté par une équation de la forme , où (la pente) et (l’ordonnée à l’origine) sont des paramètres ajustables. L’apprentissage supervisé vise à trouver les valeurs optimales de et pour que le modèle trace la meilleure droite possible, minimisant l’erreur entre prédictions et valeurs réelles.
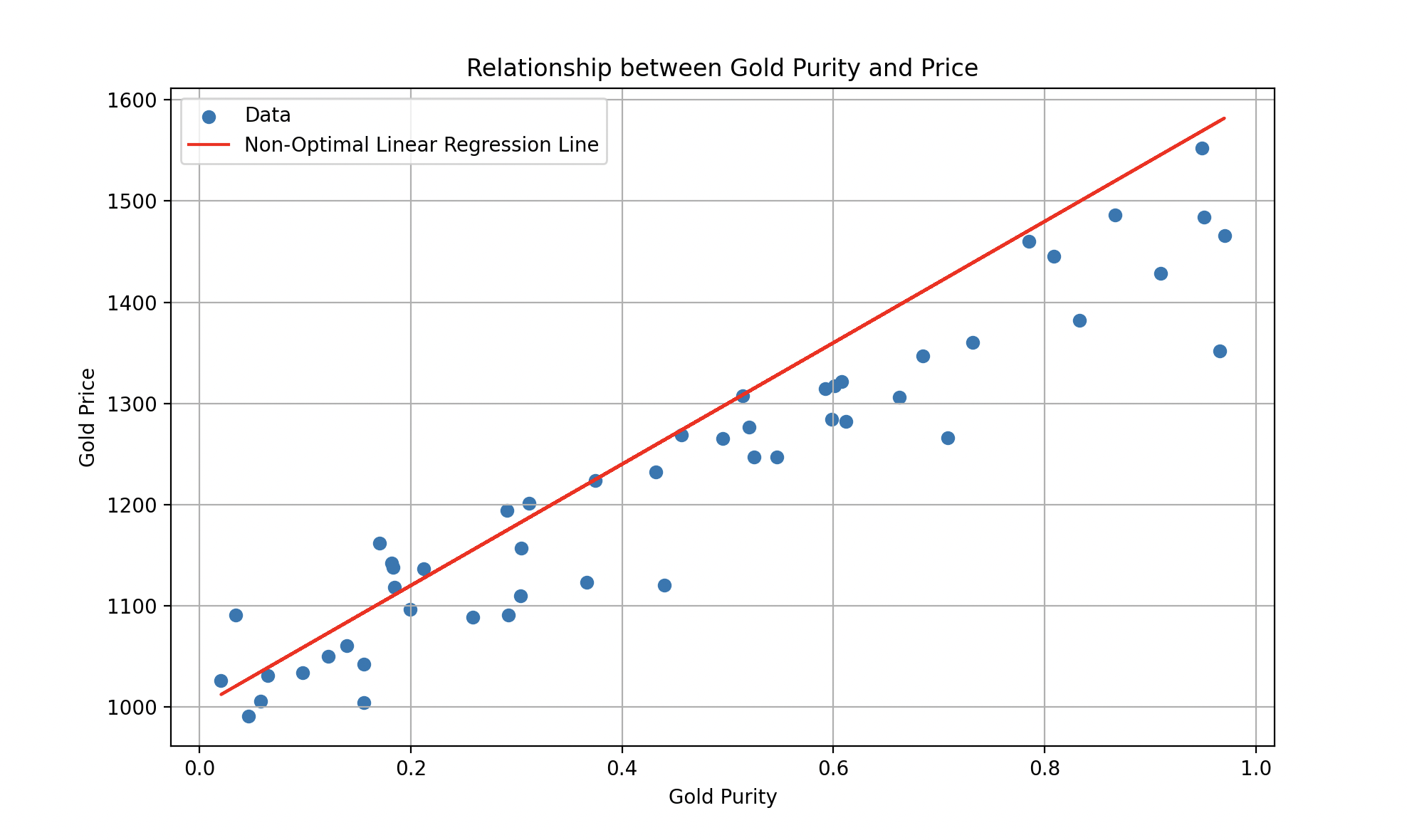
Une droite de régression linéaire ajustée sur le prix de l’or en fonction de la pureté.
Bien sûr, la réalité est plus complexe : pour une estimation plus précise, il faudrait considérer des informations historiques sur les prix de l’or, ainsi que des facteurs économiques, politiques et géopolitiques. Si les modèles linéaires sont simples et faciles à interpréter, ils peuvent être limités pour capturer des relations complexes. C’est là que les modèles non linéaires entrent en jeu.
Modèles Non Linéaires : l’Élégance dans la Complexité
Les modèles non linéaires offrent une flexibilité accrue par rapport aux modèles linéaires. Ils sont capables de capturer des relations complexes entre entrées et sorties, permettant la représentation de comportements plus sophistiqués. Imaginez que les données se comportent plutôt ainsi :
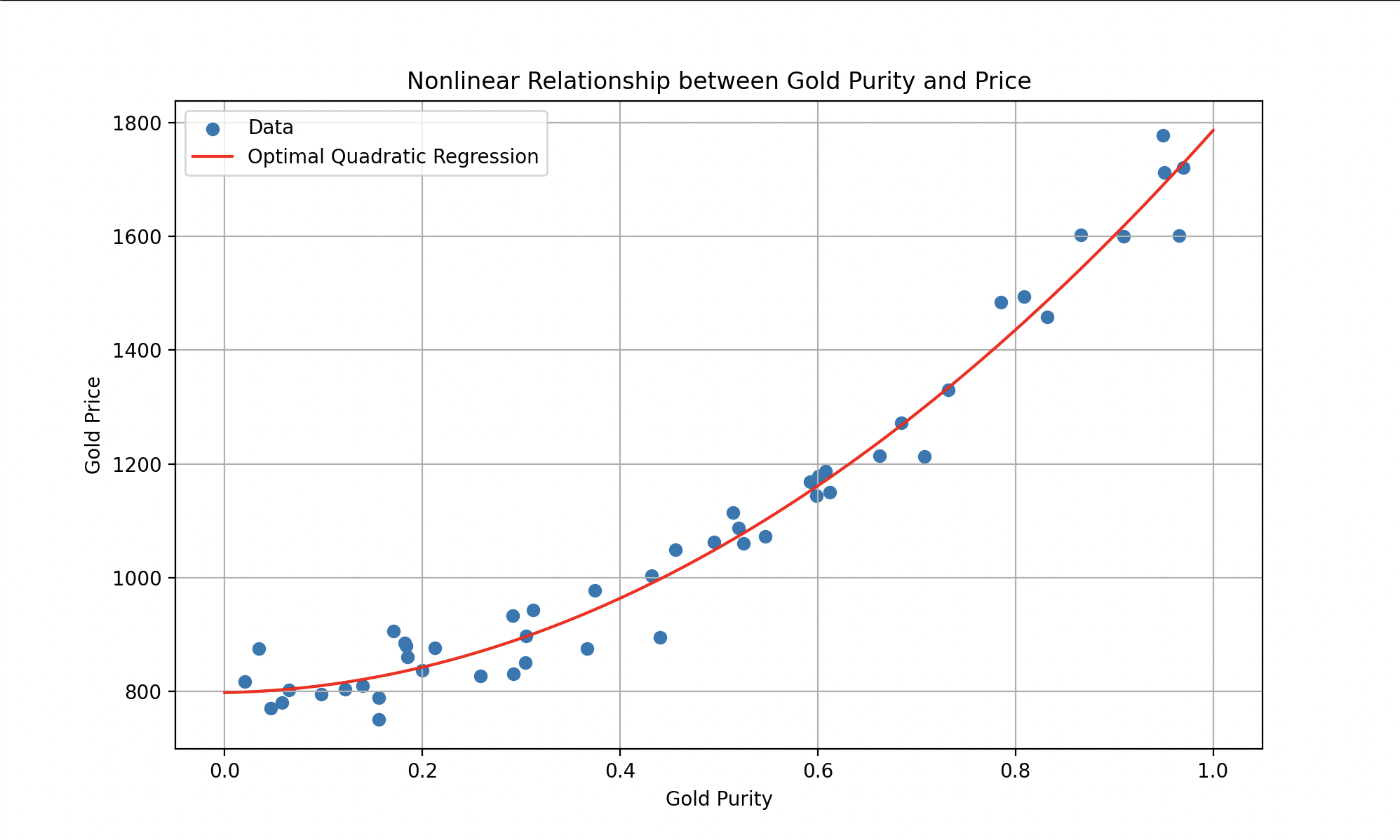
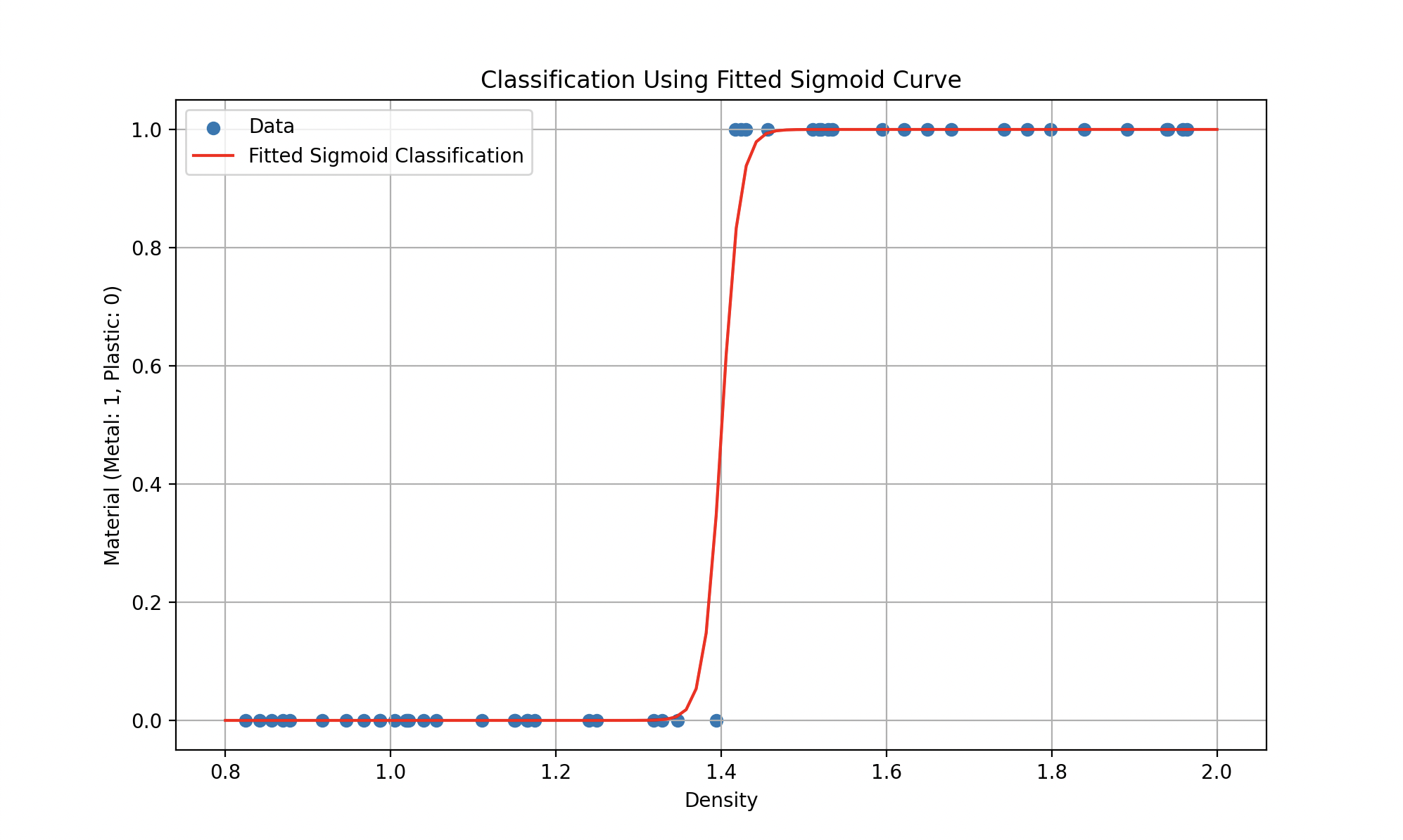
Gauche : estimation du prix de l’or par un polynôme. Droite : classification plastique-métal par une sigmoïde.
De tels modèles pourraient être représentés par des équations comme (un polynôme quadratique pour la première courbe) ou des fonctions plus complexes (comme la sigmoïde pour la seconde), où l’objectif reste de trouver les paramètres qui minimisent l’erreur.

Crédits : Disney/PIXAR
Le choix entre un modèle linéaire et un modèle non linéaire dépend de la nature des données et de la complexité du problème.
3. La Fonction Coût : Mesurer les Erreurs
Pour mesurer les performances de Wall-E dans cette tâche d’estimation, on utilise une fonction spéciale appelée fonction coût. Elle joue un rôle crucial : quantifier les erreurs entre les estimations de Wall-E et les vrais prix. Elle calcule l’erreur pour chaque estimation puis somme ces erreurs pour former une mesure globale de la performance.
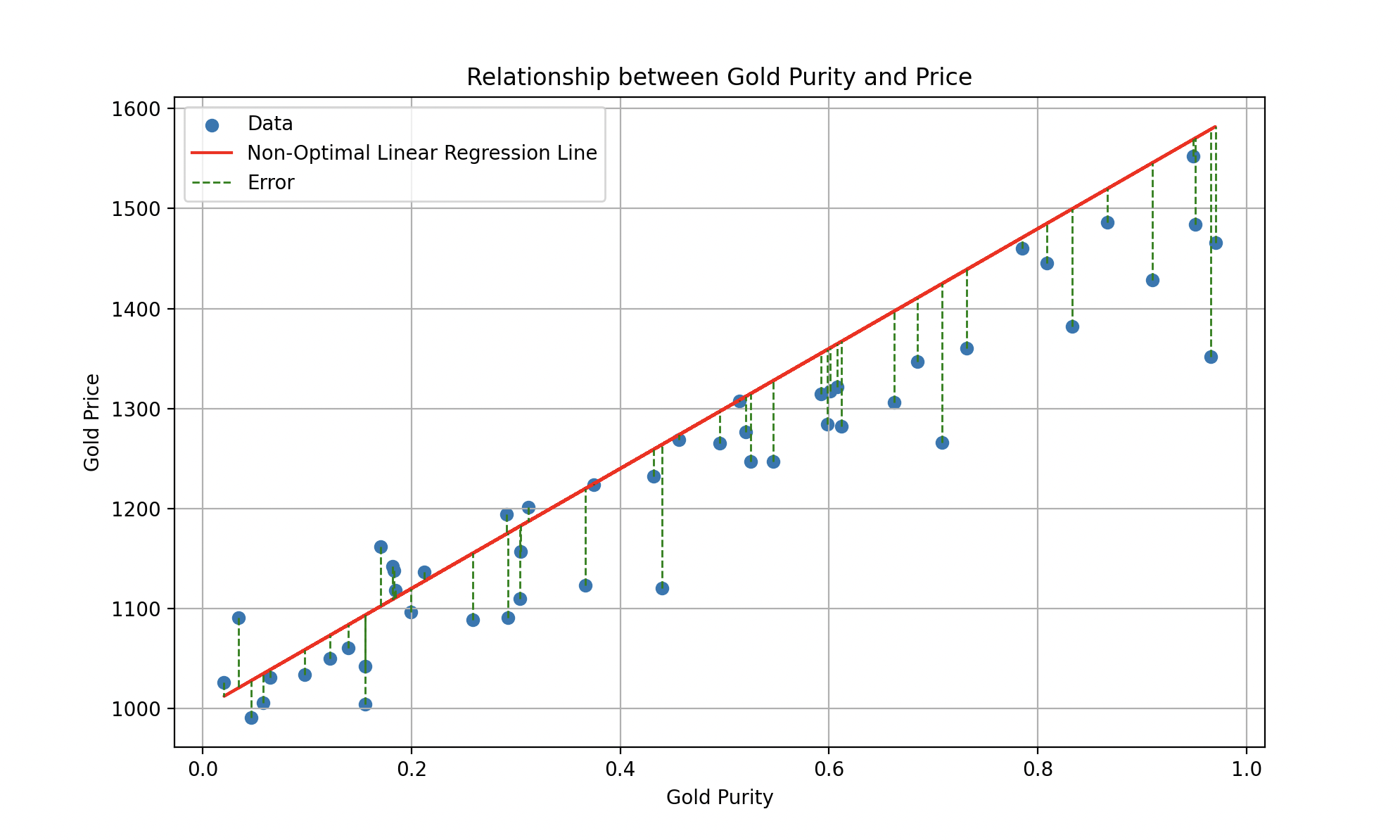
Les segments verts représentent les erreurs individuelles entre la droite prédite et chaque point.
En vrai perfectionniste, Wall-E veut une fonction coût aussi petite que possible. Minimiser cette fonction revient à minimiser les erreurs entre ses estimations et les prix réels, pour faire les prédictions les plus précises possible.
4. L’Algorithme d’Apprentissage : Trouver l’Optimum
Pour réduire cette fonction coût, Wall-E emploie un algorithme bien connu : la descente de gradient. Cette technique lui permet d’ajuster progressivement ses paramètres internes (pour le modèle linéaire : et ) en fonction des erreurs commises. À chaque étape, il améliore ses performances en se rapprochant de l’optimum, là où la fonction coût est minimale.
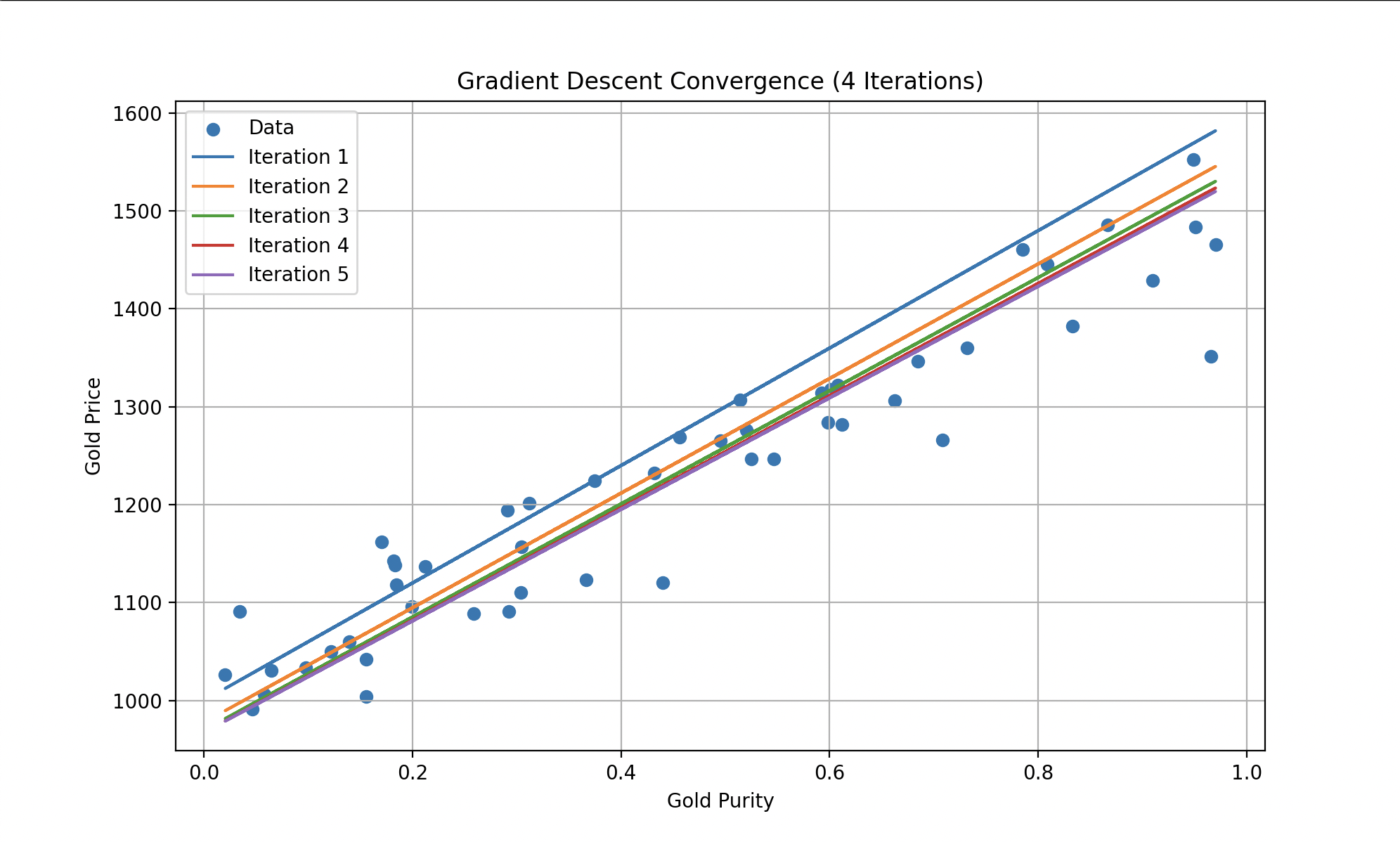

Gauche : historique du coût au fil des itérations. Droite : Wall-E à la calculette (Disney/PIXAR).
À chaque itération, les erreurs deviennent progressivement plus petites jusqu’à se stabiliser. Ainsi, Wall-E devient un expert de l’estimation du prix de l’or.
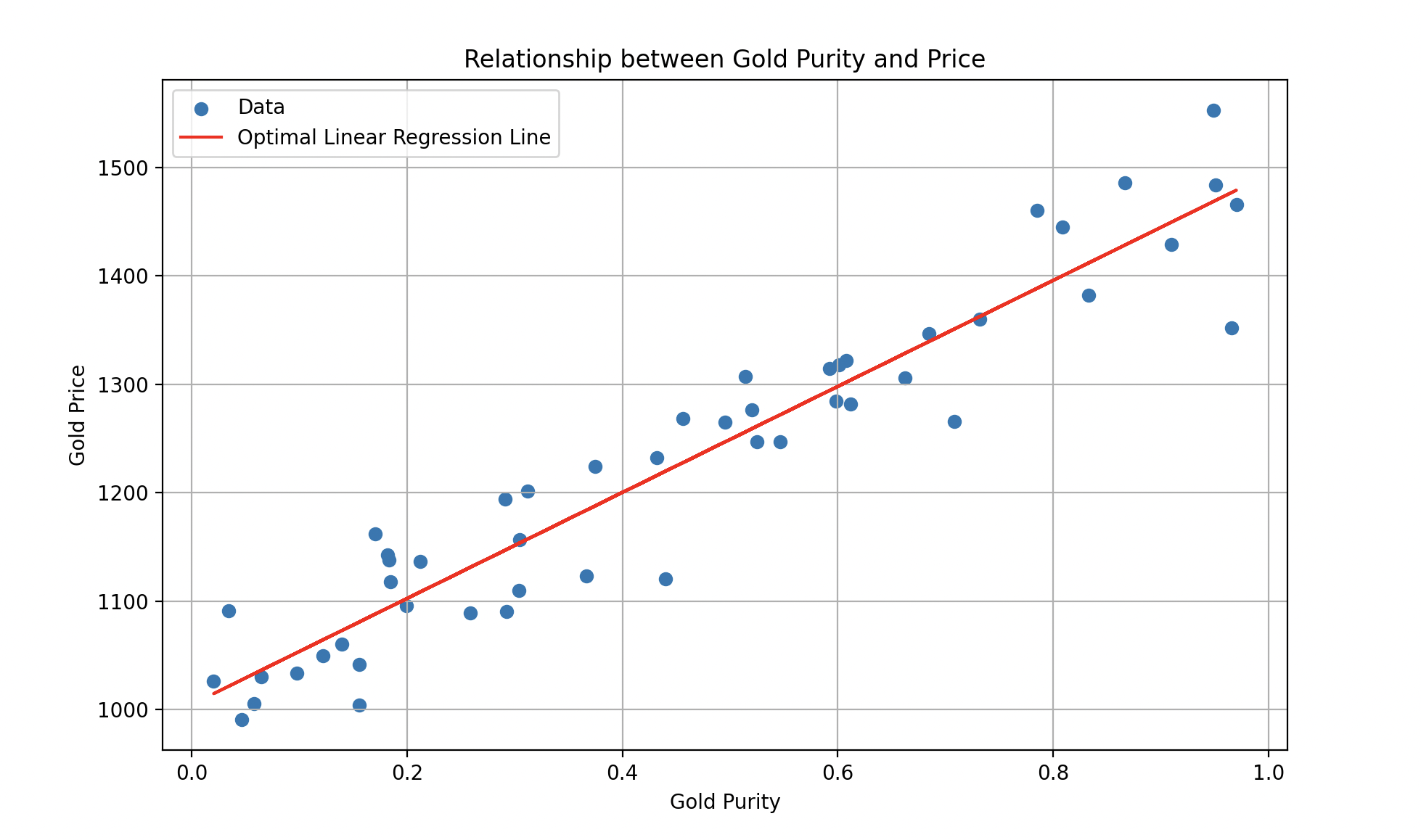
Courbe finale ajustée. Un échantillon d’or de pureté 0,8 vaudrait environ 1400 boulons.
Un Super Robot
L’univers d’apprentissage de Wall-E s’étend à de nombreuses applications, qui se répartissent en deux grandes familles : la régression et la classification.
La régression est une technique quantitative pour prédire des valeurs continues — des nombres pouvant prendre n’importe quelle valeur dans un intervalle. L’estimation du prix de l’or relève de la régression. Voici d’autres exemples que Wall-E pourrait aborder :


Crédits : Disney/PIXAR
- Estimation des réserves d’eau potable : combiner les niveaux historiques des nappes phréatiques, les précipitations et les taux d’évaporation pour estimer les réserves souterraines et aider les humains à mieux planifier leur usage.
- Prédiction de la production d’énergie solaire : à partir des données d’ensoleillement, de la qualité des panneaux et de la météo, prédire la production aux différents moments de la journée.


Crédits : Disney/PIXAR
- Estimation de la durée de vie des batteries : analyser les performances passées et les conditions environnementales pour prédire la durée de vie restante et planifier les remplacements.
- Prédiction des niveaux de pollution : agréger des données sur la pollution de l’air et de l’eau et les pratiques de dépôt pour identifier les zones les plus critiques.
La classification est une autre technique d’apprentissage supervisé pour prédire des étiquettes ou catégories discrètes. Dans sa quête pour nettoyer la Terre, Wall-E doit trier une grande variété de déchets. À partir de données sur la forme, la taille, la composition et la dangerosité, il peut bâtir un modèle de classification pour les répartir en classes (plastique, métal, organique, déchet toxique, etc.). Quelques applications :


Crédits : Disney/PIXAR
- Classification d’objets célestes : identifier astéroïdes, comètes, planètes et autres corps en fonction de leurs caractéristiques et trajectoires.
- Classification d’émotions humaines : capter expressions faciales, gestes et tonalités pour reconnaître joie, tristesse, peur ou colère — et adapter ses interactions.

Crédits : Disney/PIXAR
- Classification de signaux extraterrestres : distinguer messages de salutation, motifs mathématiques ou avertissements à mesure que Wall-E sonde les étoiles.
Exploration et Enrichissement
À mesure qu’il évoluait dans ce monde complexe, le petit robot solitaire a démontré une maîtrise inégalée à chaque défi rencontré. Son parcours, parti d’humbles débuts comme simple collecteur de déchets, l’a mené jusqu’à devenir un expert en estimation de valeurs — révélant les fondations profondes de l’intelligence artificielle. L’apprentissage supervisé, véritable pierre angulaire de cette intelligence, lui a permis de transcender les limites de sa nature mécanique.
Les prochains chapitres détaillent deux aspects cruciaux de l’apprentissage supervisé.
Partie II — Le Petit Mineur d’Or : le modèle de régression qui a permis à Wall-E de comprendre l’estimation du prix de l’or. De l’analyse du dataset à la conception du modèle, en passant par la fonction coût et la descente de gradient, chaque étape est méthodiquement disséquée.
Partie III — Le Compacteur Terrien de Déchets : le tri des déchets, tâche à la fois critique et complexe. On y détaille comment Wall-E utilise des modèles de classification pour distinguer différents types de déchets — du tri binaire plastique-vs-métal à l’identification multi-classe des métaux par KNN.
Comme Wall-E a appris à différencier le plastique du métal et à estimer la pureté de l’or, l’intelligence artificielle trouve sa place dans des domaines allant de la prédiction d’énergie solaire à la classification d’émotions humaines. Le chemin parcouru n’est qu’un prologue.
Bibliographie
- G. James, D. Witten, T. Hastie et R. Tibshirani, An Introduction to Statistical Learning, Springer Verlag, coll. « Springer Texts in Statistics », 2013
- D. MacKay, Information Theory, Inference, and Learning Algorithms, Cambridge University Press, 2003
- T. Mitchell, Machine Learning, 1997
- F. Galton, Kinship and Correlation (réimprimé en 1989), Statistical Science, vol. 4, no 2, p. 80–86
- C. Bishop, Pattern Recognition and Machine Learning, Springer, 2006