
En un mundo post-apocalíptico devastado, donde los vestigios de la civilización humana yacen sepultados bajo enormes montañas de basura, un pequeño robot solitario llamado Wall-E navega a través de este paisaje distópico. Su misión: el reciclaje metódico de los desechos abandonados durante años. Pero las hazañas de Wall-E van más allá del simple ordenamiento de trozos de plástico, láminas de metal y materiales orgánicos.
A través de sus interacciones con el entorno, este robot dedicado también recopila una abundancia de información, analiza millones de datos y aprende de sus experiencias para adaptarse, sobrevivir y llevar a cabo sus tareas con una eficiencia notable. Las capacidades de lo que parecía ser un simple robot recolector de basura revelan los fundamentos de un campo en pleno auge: la inteligencia artificial.

Créditos: Disney/PIXAR
La Esencia Misma de la Inteligencia Artificial: el Aprendizaje
En las primeras chispas de su existencia, nuestro pequeño robot, al igual que una computadora, nació para sumergirse en los abismos de cálculos que tomarían millones de años para que un humano encontrara una respuesta. Las tareas, antes titánicas para las almas terrenales, se erguían ante él, exigiendo ser dominadas.
Pero en sus circuitos se gestaba una transformación, inspirada por los genios de la comunidad científica mundial. Infundieron en nuestro robot una forma única de inteligencia, una chispa digital que cambió las reglas del juego. Wall-E, antes una máquina, ahora se estaba convirtiendo en una entidad que aprendería y tomaría decisiones complejas. Era el amanecer de la inteligencia artificial, una nueva era tecnológica.
Frente a desafíos cada vez mayores, Wall-E demostró su versatilidad. Se enfrentó sin problemas a los dos tipos de situaciones que la humanidad le presentaba. En un caso, seguía obedientemente los cálculos programados por humanos, respondiendo como una calculadora a un simple .
Sin embargo, se enfrentaba a un acertijo mucho más intrincado: ¿cómo diferenciar entre los tipos de basura que encontraba? ¿Cómo reconocer plástico de metal o material orgánico? O, más generalmente, ¿cómo resolver un problema dado sin conocer el cálculo específico requerido para su solución? Aquí entra en juego el aprendizaje, un método fascinante llamado machine learning. Una llave maestra para una multitud de tareas: reconocimiento de imágenes, predicciones bursátiles, estimación de valores de oro, detección de vulnerabilidades de ciberseguridad y, por supuesto, en nuestro caso: clasificación de basura.
Para dotar a esta computadora de una inteligencia capaz de aprender, se implementaron métodos inspirados en nuestro propio proceso de aprendizaje. Tres enfoques fundamentales destacan.
El aprendizaje supervisado es la piedra angular del machine learning. Al igual que nuestra propia experiencia de adquisición de conocimientos, este método guía a la pequeña computadora con ruedas proporcionándole ejemplos pre-etiquetados. Como un aprendiz ávido, Wall-E se expone a situaciones donde los resultados esperados son conocidos. Al observar estos ejemplos, generaliza gradualmente las relaciones entre entradas y salidas, lo que le permite tomar decisiones y resolver problemas similares más adelante.


Créditos: Disney/PIXAR
El aprendizaje no supervisado es una forma más abierta y exploratoria de la inteligencia artificial. Este método permite a la computadora descubrir de forma autónoma estructuras y patrones ocultos en los datos, sin necesidad de ejemplos pre-etiquetados. Como un explorador intrépido, Wall-E utiliza su análisis sensorial para discernir patrones, agrupar información similar y explorar los matices de su entorno.
El aprendizaje por refuerzo se basa en un sistema de recompensas y castigos para guiar a la computadora en su proceso de aprendizaje. Al igual que nuestras propias motivaciones, Wall-E es recompensado cuando completa una tarea con éxito y enfrenta consecuencias negativas por los fracasos. Estos estímulos y penalizaciones le permiten optimizar sus acciones y refinar sus habilidades con el tiempo.

Créditos: Disney/PIXAR
El Robot Bebé Crecerá: la Arquitectura del Aprendizaje Supervisado
Al nacer Wall-E, la humanidad ya había trazado su éxodo hacia los confines lejanos del espacio, dejando atrás una Tierra sofocada bajo el peso del cambio climático y la contaminación invasiva. Los equilibrios naturales que durante tanto tiempo habían acunado nuestro mundo se habían tambaleado, relegando al planeta a una nueva realidad.
Sin embargo, un grupo de científicos se había comprometido a permanecer en esta tierra cansada, guiados por una visión audaz: educar a este pequeño robot lleno de potencial para diferenciar metales, clasificar plásticos — todo ello con una misión crucial: limpiar y regenerar el propio planeta.

Créditos: Disney/PIXAR
Así comenzó una fase de aprendizaje, donde el conocimiento humano fue impartido a Wall-E. Los científicos emplearon un método específico para guiar a este robot aprendiz: el aprendizaje supervisado. Este aspecto fundamental del machine learning brindó a Wall-E la oportunidad de evolucionar y crecer absorbiendo ejemplos claramente etiquetados.
Los inicios de este viaje giran en torno a cuatro elementos cruciales: el dataset, el modelo y sus parámetros, la función de coste y el algoritmo de aprendizaje.
1. El Dataset: un Tesoro de Información
Como una mina de oro para Wall-E, el dataset constituye una colección organizada de ejemplos sobre los cuales el robot basará su aprendizaje. Cada ejemplo se compone de diversas variables de entrada (features) que dispone en una matriz, y de las salidas esperadas correspondientes (targets) que dispone en un vector. Estas últimas variables son las que Wall-E buscará predecir.
Por ejemplo, si deseamos enseñar a Wall-E a reconocer tipos de basura, las características específicas de los objetos constituirán los datos de entrada (densidad, conductividad eléctrica, contenido de carbono, etc.), y las etiquetas que indican el tipo de cada objeto constituirán las salidas esperadas (plástico, metal, orgánico).
| Índice | Densidad | Conductividad Eléctrica () | Contenido de Carbono | Material |
|---|---|---|---|---|
| 1 | 4.5 | 0 | Metal | |
| 2 | 0.5 | 0.5 | Orgánico | |
| 3 | 19.3 | 0 | Metal | |
| 4 | 1.1 | 0.4 | Orgánico | |
| 5 | 1.2 | 0 | Plástico |
Por supuesto, como robot clasificador de basura, esta tarea constituye su misión principal. Pero nuestro pequeño robot también es apasionado por la estimación del precio de los metales, especialmente del oro. Como no comprende realmente el sistema monetario humano, lo convierte todo en pernos. Para entretenerlo, los científicos le hacen analizar cada pieza de metal dorado para determinar su pureza y le asignan un valor de mercado.
| Índice | Pureza | Precio del oro |
|---|---|---|
| 1 | 0.374540 | 1224.193388 |
| 2 | 0.950714 | 1483.925567 |
| 3 | 0.731994 | 1360.214557 |
| 4 | 0.598658 | 1284.274057 |
| 5 | 0.156019 | 1004.083221 |
Con un conjunto de entrenamiento mucho más grande, podrá aprender a clasificar metal, plástico y materiales orgánicos según sus características, y evaluar el precio de un metal desconocido en función de su pureza.
2. El Modelo y sus Parámetros: la Arquitectura del Aprendizaje
Permítanme presentarles la estructura que Wall-E usará para aprender del conjunto de datos: su modelo. Imaginen una “caja negra” — un dispositivo electrónico que Wall-E utiliza para procesar información y hacer predicciones. Es “negra” en el sentido de que su funcionamiento interno es algo misterioso y complejo, al menos desde la perspectiva de Wall-E. Dentro de esta caja hay engranajes, palancas y mecanismos ocultos que transforman las entradas en salidas.
Dentro de esta caja negra están los parámetros. Son los ajustes internos que Wall-E puede modificar para mejorar su capacidad de hacer predicciones precisas — los botones y perillas secretos que puede girar y presionar para que la caja negra funcione más eficazmente. Cuando hablamos de un modelo, nos referimos a una configuración específica de esta caja negra.
El aprendizaje supervisado consiste en ajustar los parámetros de esta caja negra para que las predicciones que genera sean lo más cercanas posible a las respuestas correctas (etiquetas) proporcionadas en el conjunto de entrenamiento. Al ajustar los parámetros y observar cómo cambian las predicciones, Wall-E intenta entender cómo funciona realmente esta caja negra y cómo mejorarla.
Estos modelos pueden ser de naturalezas diferentes: algunos son lineales, otros no.
Modelos Lineales: la Simplicidad en la Linealidad
Los modelos lineales son representaciones matemáticas relativamente simples pero poderosas. Asumen que la relación entre las entradas y las salidas es lineal — lo que significa que puede representarse mediante una línea recta (o un plano o hiperplano en un espacio multidimensional).
Los científicos no solo limitaron al robot al simple reciclaje: también le enseñaron a estimar el precio de un metal en función de su pureza. Al revisar sus datos, Wall-E tiene un dataset de muestras de oro, donde la pureza es la feature de entrada y el precio correspondiente es el target .
| Índice | ||
|---|---|---|
| 1 | 0.374540 | 1224.193388 |
| 2 | 0.950714 | 1483.925567 |
| 3 | 0.731994 | 1360.214557 |
| 4 | 0.598658 | 1284.274057 |
| 5 | 0.156019 | 1004.083221 |
La muestra 2, por ejemplo, tiene pureza y vale pernos. Al graficar los datos (mostramos 50 muestras en lugar de 5, e imaginen que podrían ser millones):

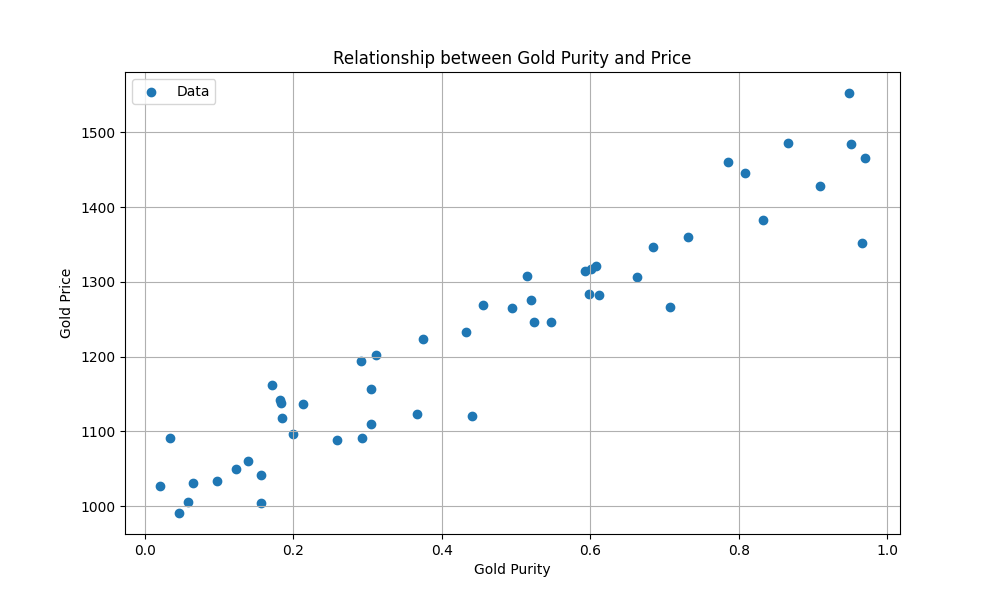
Créditos: Disney/PIXAR — Diagrama de dispersión del precio del oro en función de su pureza.
Tal modelo podría representarse mediante una ecuación de la forma , donde (la pendiente) y (la ordenada al origen) son parámetros ajustables. El aprendizaje supervisado busca encontrar los valores óptimos de y para que el modelo trace la mejor línea posible que minimice el error entre predicciones y valores reales.
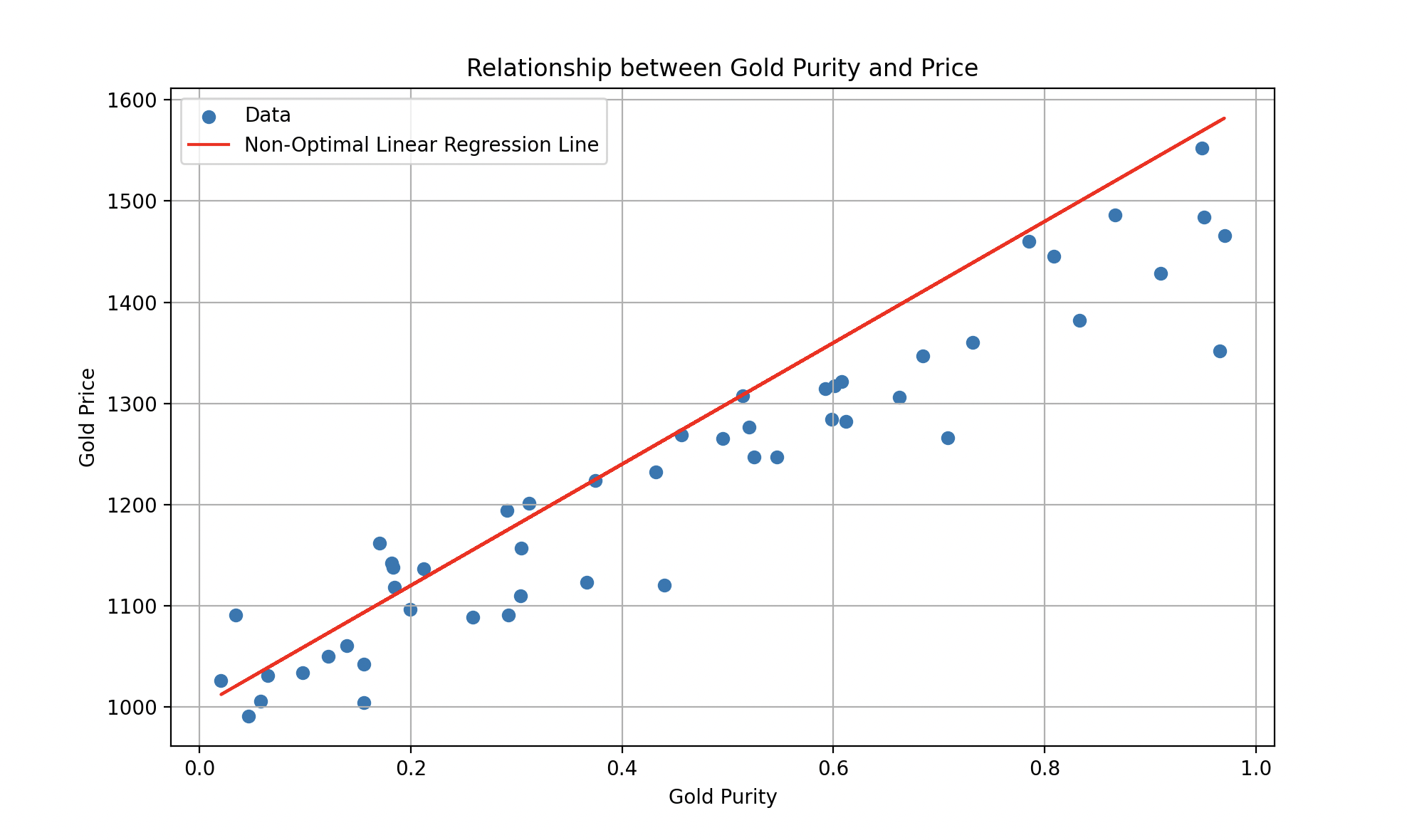
Una línea de regresión lineal ajustada sobre el precio del oro en función de la pureza.
Por supuesto, la realidad es más compleja: para una estimación más precisa, sería necesario considerar información histórica sobre los precios del oro, así como factores económicos, políticos y geopolíticos. Si bien los modelos lineales son simples y fáciles de interpretar, pueden ser limitados para capturar relaciones complejas. Aquí es donde entran en juego los modelos no lineales.
Modelos No Lineales: la Elegancia en la Complejidad
Los modelos no lineales ofrecen mayor flexibilidad que los modelos lineales. Son capaces de capturar relaciones complejas entre entradas y salidas, permitiendo representar comportamientos más sofisticados. Imaginen que tenemos datos que se comportan más bien así:
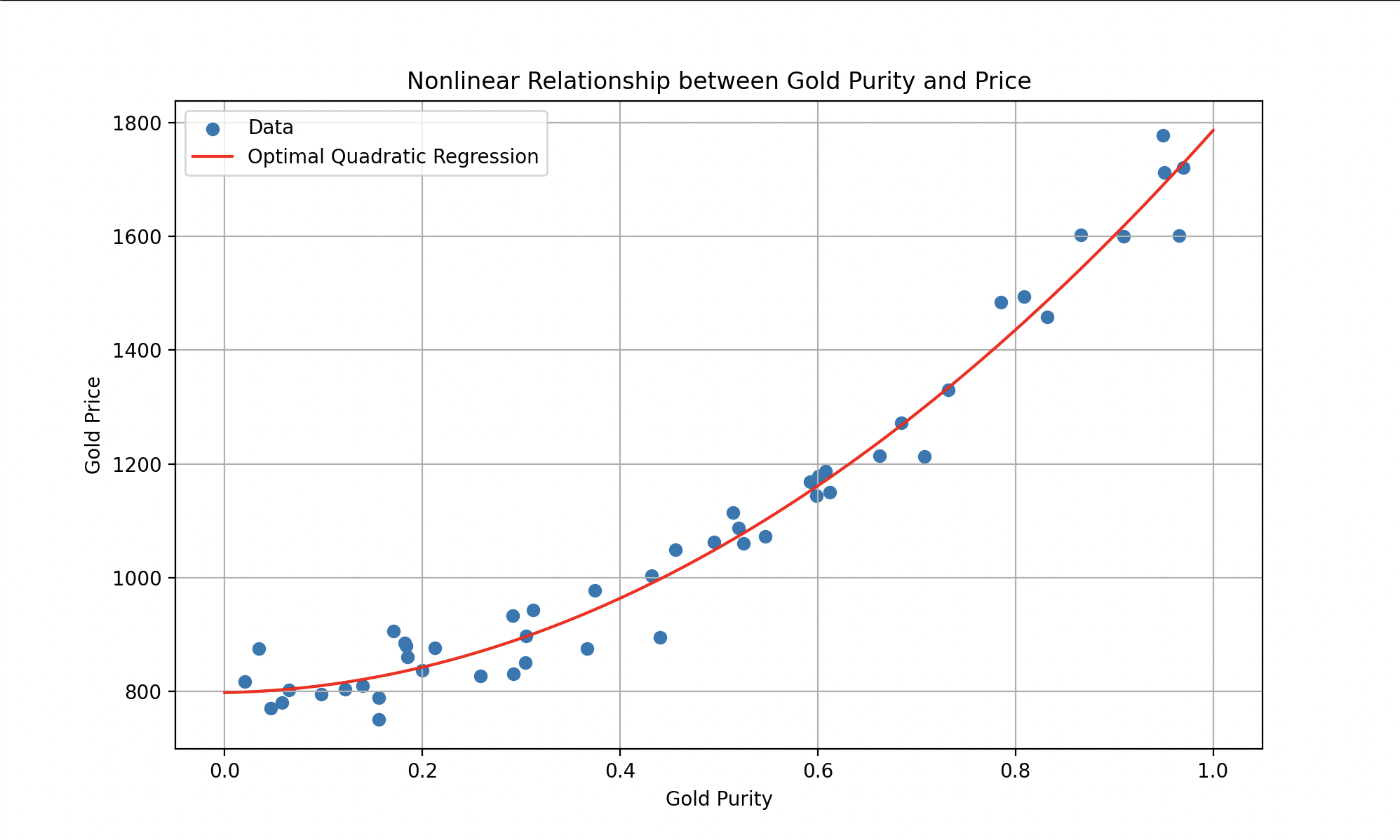
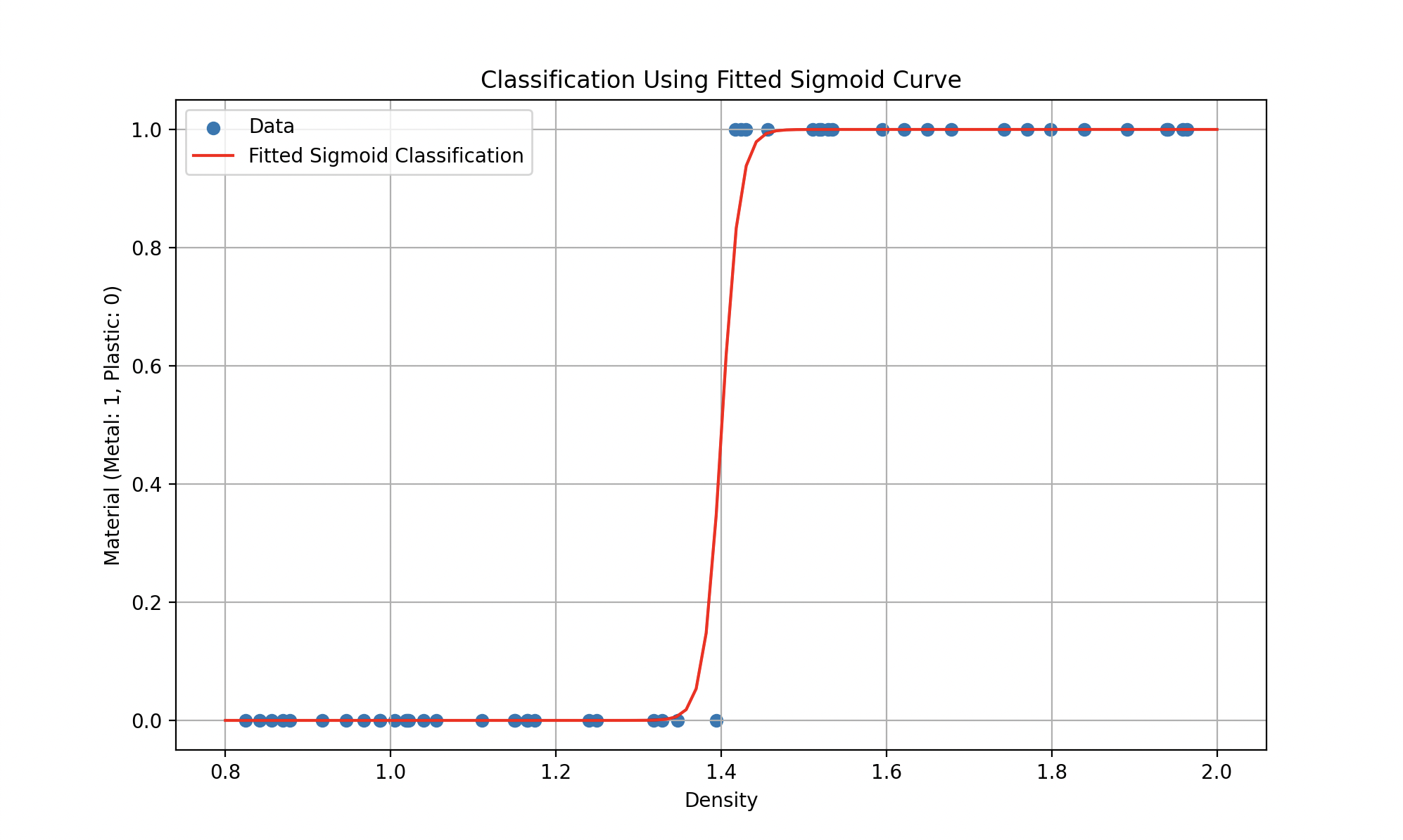
Izquierda: estimación del precio del oro por polinomio. Derecha: clasificación plástico-metal por sigmoide.
Tales modelos podrían representarse mediante ecuaciones como (un polinomio cuadrático para la primera curva) o funciones más complejas (como la sigmoide para la segunda), donde el objetivo sigue siendo encontrar los parámetros que minimicen el error.

Créditos: Disney/PIXAR
La elección entre un modelo lineal y uno no lineal depende de la naturaleza de los datos y la complejidad del problema.
3. La Función de Coste: Medir los Errores
Para medir el desempeño de Wall-E en esta tarea de estimación, usamos una función especial llamada función de coste. Desempeña un papel crucial: cuantificar los errores entre las estimaciones de precio hechas por Wall-E y los precios reales del oro de los datos históricos. Calcula el error para cada estimación y luego suma estos errores para formar una medida global del rendimiento de Wall-E.
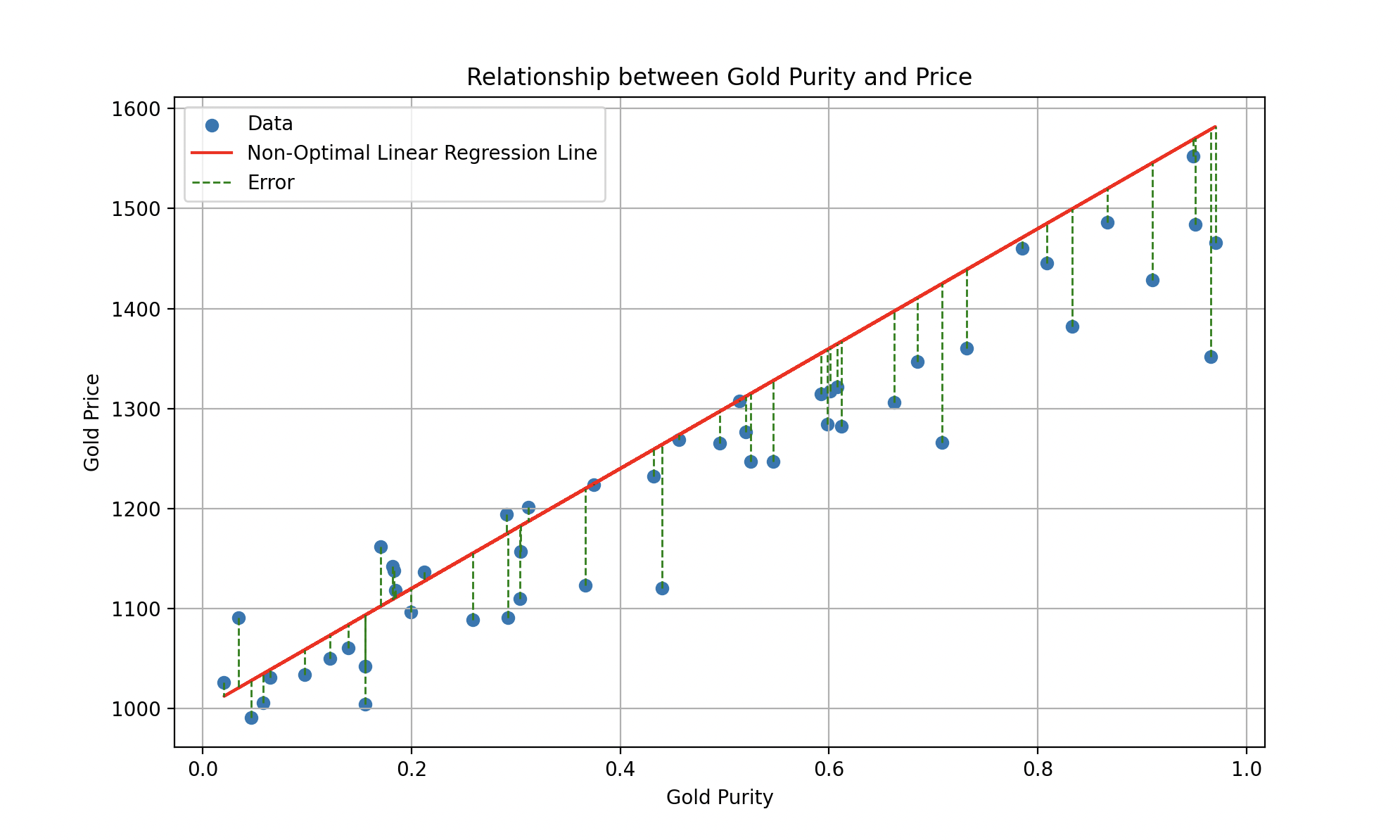
Los segmentos verticales verdes representan los errores individuales entre la línea predicha y cada punto.
Como verdadero perfeccionista, Wall-E busca una función de coste lo más pequeña posible. Minimizarla implica minimizar los errores entre sus estimaciones y los precios reales, para hacer las predicciones lo más precisas posible.
4. El Algoritmo de Aprendizaje: Encontrar el Óptimo
Para reducir esta función de coste, Wall-E emplea un algoritmo bien conocido: el descenso de gradiente. Esta técnica le permite ajustar gradualmente sus parámetros internos (para el modelo lineal: y ) según los errores cometidos. En cada paso, mejora su rendimiento acercándose al óptimo, donde la función de coste es mínima.
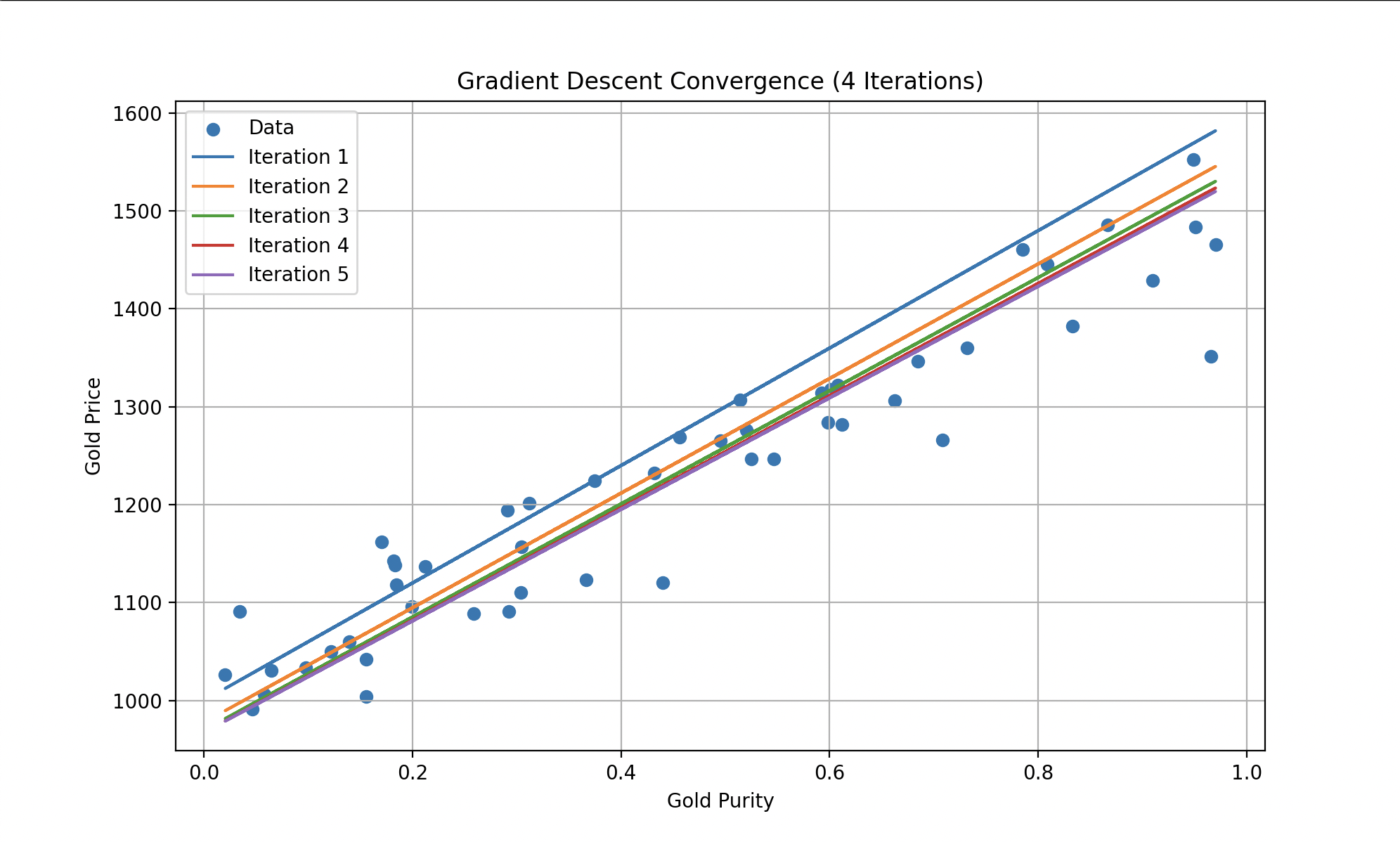

Izquierda: historial del coste a lo largo de las iteraciones. Derecha: Wall-E haciendo cuentas (Disney/PIXAR).
En cada iteración, los errores se vuelven progresivamente más pequeños hasta estabilizarse. Así, Wall-E se convierte en un experto en la estimación del precio del oro, haciendo predicciones con notable precisión.
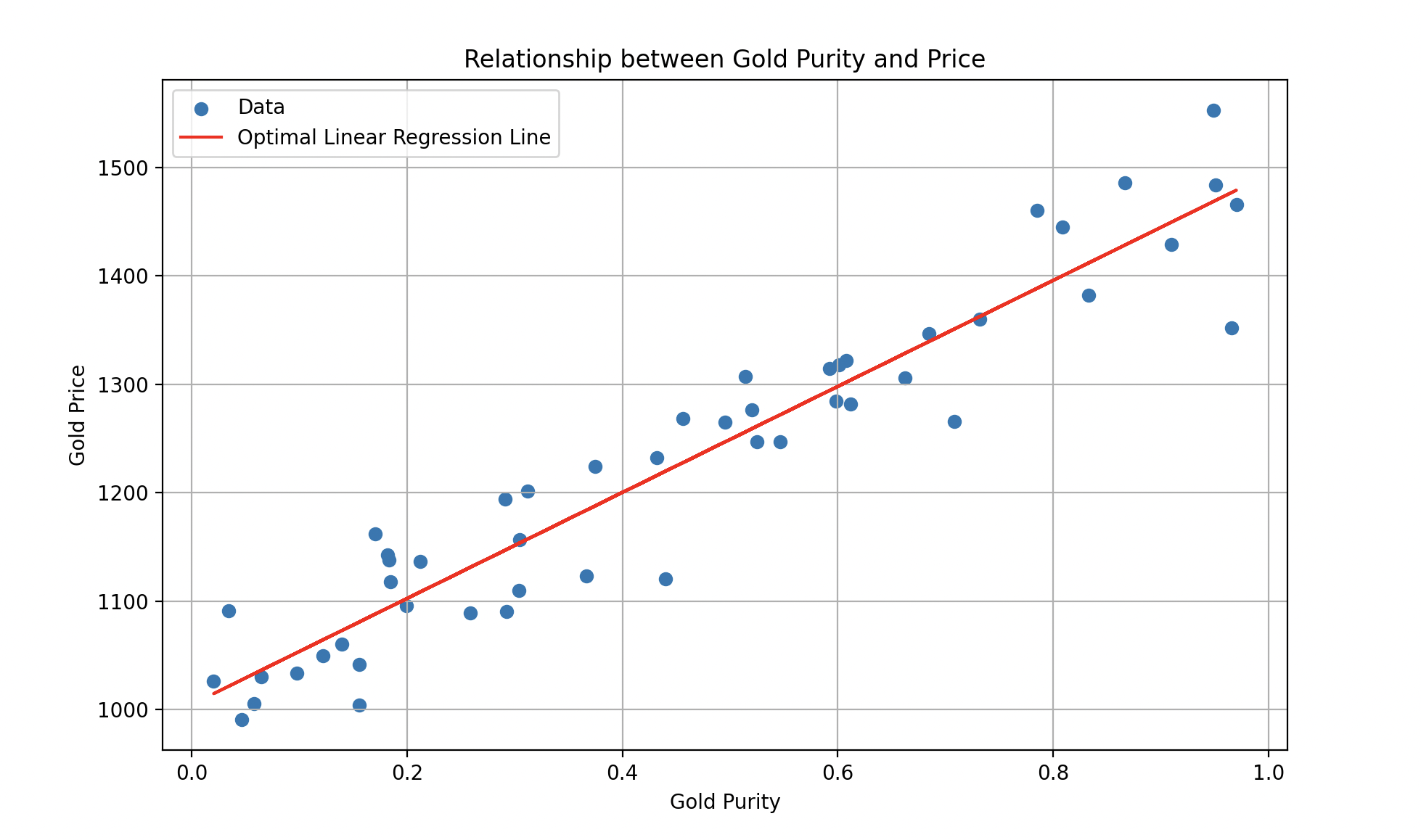
Curva final ajustada. Una muestra de oro con pureza 0,8 valdría aproximadamente 1400 pernos.
Un Súper Robot
El universo de aprendizaje de Wall-E se extiende a numerosas aplicaciones, que se reparten en dos grandes familias: la regresión y la clasificación.
La regresión es una técnica cuantitativa para predecir valores continuos — números que pueden tomar cualquier valor en un cierto rango. La estimación del precio del oro pertenece a la regresión. Otros ejemplos que Wall-E podría abordar:


Créditos: Disney/PIXAR
- Estimación de las reservas de agua potable: combinar niveles históricos de aguas subterráneas, precipitaciones y tasas de evaporación para estimar las reservas subterráneas y ayudar a los humanos a planificar mejor su uso.
- Predicción de la producción de energía solar: a partir de datos de luz solar diaria, calidad de los paneles y meteorología, predecir la producción a diferentes horas del día y bajo distintas condiciones climáticas.


Créditos: Disney/PIXAR
- Estimación de la vida útil de las baterías: analizar el rendimiento pasado y las condiciones ambientales para predecir la vida útil restante y planificar reemplazos proactivos.
- Predicción de niveles de contaminación: agregar datos sobre contaminación del aire y del agua, así como prácticas de descarga, para identificar las zonas más críticas para la limpieza.
La clasificación es otra técnica de aprendizaje supervisado para predecir etiquetas o categorías discretas. En su búsqueda por limpiar la Tierra, Wall-E debe clasificar una amplia variedad de residuos. A partir de datos sobre forma, tamaño, composición y peligrosidad, puede crear un modelo de clasificación para repartirlos automáticamente en clases (plástico, metal, orgánico, residuo tóxico, etc.). Algunas aplicaciones:


Créditos: Disney/PIXAR
- Clasificación de objetos celestes: identificar asteroides, cometas, planetas y otros cuerpos basándose en sus características y trayectorias.
- Clasificación de emociones humanas: capturar expresiones faciales, gestos y tonos vocales para reconocer alegría, tristeza, miedo o enojo — y adaptar las interacciones.

Créditos: Disney/PIXAR
- Clasificación de señales extraterrestres: distinguir mensajes de saludo, patrones matemáticos o advertencias mientras Wall-E escanea las estrellas.
Exploración y Enriquecimiento
A medida que evolucionaba en este mundo intrincado, el pequeño robot solitario demostró un dominio incomparable con cada desafío que enfrentaba. Su viaje comenzó humildemente como un mero recolector de basura, pero evolucionó hasta convertirse en un experto en estimación de valores — descubriendo así los profundos fundamentos de la inteligencia artificial. El aprendizaje supervisado, verdadera piedra angular de esta inteligencia, le permitió trascender los límites de su naturaleza mecánica.
Las próximas secciones profundizan en dos aspectos cruciales del aprendizaje supervisado.
Parte II — El Pequeño Minero de Oro: el modelo de regresión que permitió a Wall-E entender la estimación del valor del oro. Desde el análisis del dataset hasta el diseño del modelo, pasando por la función de coste y el descenso de gradiente, cada paso se diseca metódicamente.
Parte III — El Compactador Terrestre de Basura: el reino de la clasificación de residuos, una tarea crítica y compleja. Detallamos cómo Wall-E utiliza modelos de clasificación para distinguir distintos tipos de residuos — desde la clasificación binaria plástico vs. metal hasta la identificación multiclase de metales con KNN.
Así como Wall-E aprendió a diferenciar el plástico del metal y a estimar la pureza del oro, la inteligencia artificial encuentra su lugar en dominios que van desde la predicción de la producción de energía solar hasta la clasificación de emociones humanas. El camino recorrido es solo un prólogo.
Bibliografía
- G. James, D. Witten, T. Hastie y R. Tibshirani, An Introduction to Statistical Learning, Springer Verlag, coll. “Springer Texts in Statistics”, 2013
- D. MacKay, Information Theory, Inference, and Learning Algorithms, Cambridge University Press, 2003
- T. Mitchell, Machine Learning, 1997
- F. Galton, Kinship and Correlation (reimpreso en 1989), Statistical Science, vol. 4, no 2, pp. 80–86
- C. Bishop, Pattern Recognition and Machine Learning, Springer, 2006